ViT简述【Transformer】
Transformer在NLP任务中表现很好,但是在CV任务中应用还很有限,基本都是作为CNN的一个辅助,Vit尝试使用纯Transformer结构解决CV的任务,并成功将其应用到了CV的基本任务--图像分类中。
因此,简单而言,这篇论文的主旨就是,用Transformer结构完成图像分类任务。
结构概述
基本结构如下:
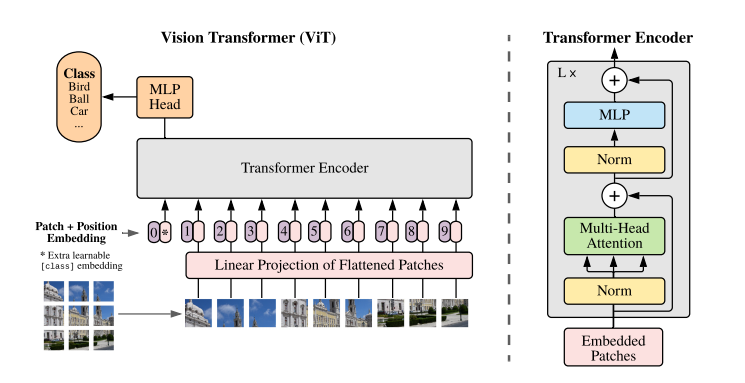
核心要点:
- 图像切patch
- Patch0
- Position Embedding
- Multi-Head Attention
图像切patch
在NLP任务中,将自然语言使用Word2Vec转为向量(Embedding)送入模型进行处理,在CV中没有对应的序列化token,因此作者采用将原始图像切分为多个小块,然后将每个小块儿内的信息展平的方式。
假设输入的shape为:(1, 3, 288, 288)
切分为9个小块,则每个小块的shape为:(1, 3, 32, 32)
然后将每个小块展平,则每个小块为(1, 3072),有9个小块,所以Linear Projection of Flattened Patched的shape为:(1, 9, 3072)输出shape为(1, 9, 1024),再加上Position Embedding,Transformer Encoder的输入shape为(1, 10, 1024),也就是图中Embedded Patches的shape。
Patch0
为什么需要有Patch0?
这是因为需要对1-9个patches信息的整合,最后送入MLP Head的只有Patch0。
Position Embedding
图像被切分和展开后,丢失了位置信息,对于图像处理任务来说,这是很怪异的,因此,作者这里采用在每个Patch上增加一个位置信息的方式,将位置信息纳入考虑。
Multi-Head Attention
参考Attention的基本结构。[Todo, Link]
代码[Pytorch]
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img)
print(preds.shape) # 1000,与ViT定义的num_classes一致
ViT类参数解析:
- dim:Linear Projection的输出维度:1024
- depth:有多少个Transformer Blocks
- heads:Multi-Head的Head数
- mlp_dim:Transformer Encoder内部的MLP的维度
- dropout
- ......
ViT的forward函数:
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
输入端的切分主要由下面这句话完成:
x = self.to_patch_embedding(img)
==>
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
#由传入参数: image_size = 256, patch_size = 32
# Rearrange完成的shape变换为(b, c, 256, 256) -> (b, 64, 1024*c)
# nn.LayerNorm
# nn.Linear: (b, 64, 1024*c) --> (b, 64, 1024)
Rearrange用更加可理解的方式实现transpose的功能:
We don't write:
y = x.transpose(0, 2, 3, 1)
We write comprehensible code:
y = rearrange(x, 'b c h w -> b h w c')
ViT简述【Transformer】的更多相关文章
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- Transformer详解
0 简述 Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提 ...
- 从零搭建Pytorch模型教程(三)搭建Transformer网络
前言 本文介绍了Transformer的基本流程,分块的两种实现方式,Position Emebdding的几种实现方式,Encoder的实现方式,最后分类的两种方式,以及最重要的数据格式的介绍. ...
- 论文阅读 | Transformer-XL: Attentive Language Models beyond a Fixed-Length Context
0 简述 Transformer最大的问题:在语言建模时的设置受到固定长度上下文的限制. 本文提出的Transformer-XL,使学习不再仅仅依赖于定长,且不破坏时间的相关性. Transforme ...
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言 人脸表情识别(FER)在计算机视觉领域受到越来越多的关注.本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER ...
- ICCV2021 | PnP-DETR:用Transformer进行高效的视觉分析
前言 DETR首创了使用transformer解决视觉任务的方法,它直接将图像特征图转化为目标检测结果.尽管很有效,但由于在某些区域(如背景)上进行冗余计算,输入完整的feature maps ...
- pycaffe︱caffe中fine-tuning模型三重天(函数详解、框架简述)
本文主要参考caffe官方文档[<Fine-tuning a Pretrained Network for Style Recognition>](http://nbviewer.jupy ...
- 带你读Paper丨分析ViT尚存问题和相对应的解决方案
摘要:针对ViT现状,分析ViT尚存问题和相对应的解决方案,和相关论文idea汇总. 本文分享自华为云社区<[ViT]目前Vision Transformer遇到的问题和克服方法的相关论文汇总& ...
随机推荐
- 使用Typora
Markdown学习 标题:#+空格+名称 二级标题 二级标题:##+空格+名称 三级标题 几级标题以此类推,最多支持到六级标题 字体 Hello,world! 变粗体:一句话的前后加上两个** 变斜 ...
- TypeError: Object(…) is not a function
vue中遇到的这个错误 1. 先检查变量名或者函数名是否有重复定义 报这错之后看了好久,也没有发现starkflow上说的,重复定义了变量或者函数 2. vue的话 检查下函数写的位置,直接写到cre ...
- Spring 6 源码编译和高效阅读源码技巧分享
一. 前言 Spring Boot 3 RELEASE版本于 2022年11月24日 正式发布,相信已经有不少同学开始准备新版本的学习了,不过目前还不建议在实际项目中做升级,毕竟还有很多框架和中间件没 ...
- css实习滤镜效果(背景图模糊)
模糊实例 图片使用高斯模糊效果: img { -webkit-filter: blur(5px); /* Chrome, Safari, Opera */ filter: blur(5px); } c ...
- DSS+Linkis Ansible 单机一键安装脚本
DSS+Linkis Ansible 单机一键安装脚本 一.简介 为解决繁琐的部署流程,简化安装步骤,本脚本提供一键安装最新版本的DSS+Linkis环境:部署包中的软件采用我自己编译的安装包,并且为 ...
- gitee删除上传到的远程分支的提交记录
在实际开发中可能也经常会遇到写完代码后提交到远程分支但发现写的提交信息有误,不符合规范.由于自己的gitee账号可能没有修改提交记录的权限.因此最佳的解决方法是,撤销本地分支当前的提交记录,将代码回滚 ...
- 字符编码:Unicode & UTF-16 & UTF-8
ASCII码 使用一个字节(8位),对128个字符进行编码: 最高位始终为0: 码数范围为0000_0000(0x00)到0111_1111(0x7F): Unicode 开始的编码设计 使用两个字节 ...
- [OpenCV实战]44 使用OpenCV进行图像超分放大
图像超分辨率(Image Super Resolution)是指从低分辨率图像或图像序列得到高分辨率图像.图像超分辨率是计算机视觉领域中一个非常重要的研究问题,广泛应用于医学图像分析.生物识别.视频监 ...
- 有意思,小程序还可以一键生成App!
小程序≠微信小程序 说到小程序,大部分同学的第一反应,可能是微信小程序.支付宝小程序,确实,小程序的概念深入人心,并且已经被约定俗成的绑定到某些互联网公司的 APP 上. 但是,"小程序&q ...
- 在 C# 9 中使用 foreach 扩展
在 C# 9 中,foreach 循环可以使用扩展方法.在本文中,我们将通过例子回顾 C# 9 中如何扩展 foreach 循环. 代码演示 下面是一个对树形结构进行深度优先遍历的示例代码: usin ...