pandas:数据迭代、函数应用
1、数据迭代
1.1 迭代行
(1)df.iterrows()
for index, row in df[0:5].iterrows(): #需要两个变量承接数据
print(row)
print("\n")
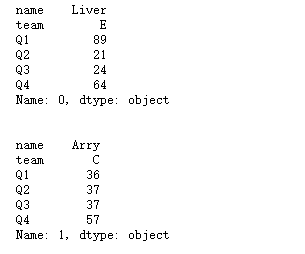
for index, row in df[0:5].iterrows():
print(row.team) #通过对象属性方式
print(row['name']) #通过字典方式读取具体列
print("\n")

(2)df.iertuples()
#生成一个nametuples类型的数据,默认name为Pandas(可在参数中指定)
for row in df[0:5].itertuples():
print(row,"\n")

for row in df[0:5].itertuples():
print(row.name,"\n") #可以通过元素属性的方式取出具体值

1.2 迭代列
(1)df.iteritems()、df.items()
# df.items(),df.iteritems() 迭代时返回(列名,本列的series结构数据)
for label, item in df[0:5].items(): #label是列名
print(label,item)
print("\n")

for label, item in df[0:5].items():
print(item) #item的数据结构是series(有行索引,和数据)
print("\n")

for label, colunm in df[0:5].items():
print(colunm.sort_values()) #数据结构是series(有行索引,和数据)因此可以使用series的方法
print("\n")

(2)对dataframe直接进行迭代
for item in df:
print(item) #item会得到df的列名
print("\n")

for item in df:
print(df[item]) #item会得到df的列名,通过df[item]又可以得到每个列的值
print("\n")

2、函数应用
2.1 pipe()
#将复杂的调用简化,语法结构为df.pipe(<函数名>,<参数列表或字典>)
#ta将dataframe或series作为函数的第一个参数
#定义一个函数,给所有季度的成绩加n,然后增加一个平均数
def add_mean(df,n):
n_df = df.copy()
n_df = n_df.loc[:,'Q1':'Q4'] + n
n_df['avg'] = n_df.sum(1)
return n_df
add_mean(df,100) #此时原本的df没变
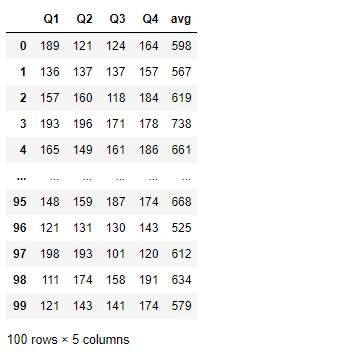
df.pipe(add_mean,100) #运行结果与上图一致
#函数部分还可以使用lambda
df.pipe(lambda df,x,y: df[(df.Q1>x) & (df.Q2 >y)],60,70) #选出df中同时满足Q1>60,Q2>70的数据
2.2 apply()
#apply(),对df按行和列(默认逐列传入)进行函数处理,也支持series(传入具体值)
#将name转换为全小写
df.name.apply(lambda x : x.lower())

#计算每个季度的平均成绩,计算方法为去掉一个最高分和去掉一个最低分
def avg(s ):
min = s.min()
max = s.max()
average = (s.sum()-min-max)/ (s.count()-2)
return average
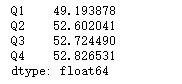
df.select_dtypes(include='number').apply(avg)

#计算每个学生的平均成绩
df1 = df.set_index('name')
df1.select_dtypes(include='number').apply(avg)
#与np.where()配合使用 np.where(逻辑表达式,替换值1,替换值2)
df.apply(lambda x: (x.team=='A') & (x.Q1>90), axis=1).map({True:'GOOD',False:'Other'})
2.3 applymap()
#applymap(),对dataframe或者series的所有元素(不包括索引)应用函数处理
#使用lambda时,变量是指具体的值
#例子:计算每个数据的长度
df.applymap(lambda x:len(str(x)))
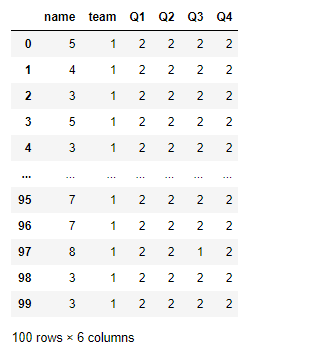
2.4 map()
#map()根据输入对应关系映射值返回最终数据
#可传入一个人字典(键为原值,值为新值)
#可传入一个函数(参数为series的每个值)
df.team.map({'A':'一班','B':'二班','C':'三班','D':'四班'}) #没有映射值的会被填为NAN

df.team.map('I am a {}'.format) #传入格式化表达式来格式化数据内容

df.Q1.map('11{}'.format) #数字会被转为字符

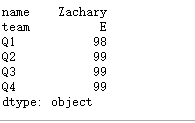
2.5 agg()
#agg使用指定轴上的一项或多项操作进行汇总
#可以传入一个函数挥着函数的字符
#每列的最大值
df.agg('max')
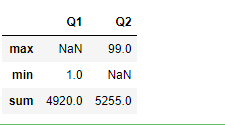
#将所有列聚合产生sum和min两行
#传入多个函数
df.agg(['sum','min'])

#序列多个聚合
df.agg({'Q1':['sum','min'],'Q2':['sum','max']})
#分组后聚合
df.groupby('team').agg('max')
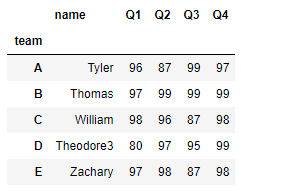
#支持每个列分别用不同的方法聚合
#支持指定轴的方向
#1、不同列使用不同的方法进行聚合
df.agg(最大值=('Q1',max),
最小值=('Q2',min),
平均值=('Q3',np.mean),
求和=('Q4',lambda x :x.sum())
)
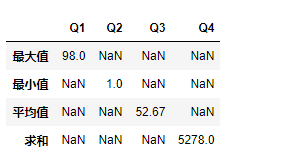
#2、按行聚合
df.loc[:,'Q1':'Q4'].agg(np.mean,axis=1)
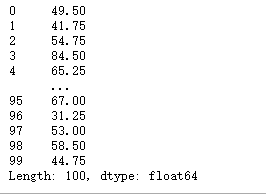
2.6 transform()
#datafram或者series自身调用函数,并返回一个与自身长度相同的数据
#1、应用匿名函数
df.transform(lambda x:x*2) #字符串会变成重复两遍,数字会*2
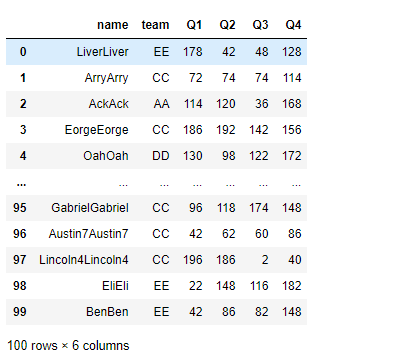
#调用多个函数
df.transform([np.sqrt,np.exp]) #自动筛选数字列,并应用
3、参考文献
《深入浅出Pandas》
pandas:数据迭代、函数应用的更多相关文章
- Jq_Ajax 操作函数跟JQuery 遍历函数跟JQuery数据操作函数
JQuery文档操作方法 jQuery 库拥有完整的 Ajax 兼容套件.其中的函数和方法允许我们在不刷新浏览器的情况下从服务器加载数据. 函数 ...
- 【summary】JQuery 相关css、ajax、数据操作函数或方法
总结一下JQuery常用的函数方法,更加系统的整理一下. JQuery遍历的一些函数: 函数 描述 .add() 将元素添加到匹配元素的集合中. .andSelf() 把堆栈中之前的元素集添加到当前集 ...
- pandas小记:pandas数据输入输出
http://blog.csdn.net/pipisorry/article/details/52208727 数据输入输出 数据pickling pandas数据pickling比保存和读取csv文 ...
- pandas DataFrame apply()函数(1)
之前已经写过pandas DataFrame applymap()函数 还有pandas数组(pandas Series)-(5)apply方法自定义函数 pandas DataFrame 的 app ...
- pandas DataFrame.shift()函数
pandas DataFrame.shift()函数可以把数据移动指定的位数 period参数指定移动的步幅,可以为正为负.axis指定移动的轴,1为行,0为列. eg: 有这样一个DataFrame ...
- pandas 数据预处理
pandas 数据预处理 缺失数据处理 csv_data=''' A,B,C,D 1.0,2.0,3.0,4.0 5.6,6.0,,8.0 0.0,11.0,12.0,,''' import pand ...
- Pandas数据规整
Pandas数据规整 数据分析和建模方面的大量编程工作都是用在数据准备上的,有时候存放在文件或数据库中的数据并不能满足数据处理应用的要求 Pandas提供了一组高级的.灵活的.高效的核心函数和算法,它 ...
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- Python之pandas数据加载、存储
Python之pandas数据加载.存储 0. 输入与输出大致可分为三类: 0.1 读取文本文件和其他更好效的磁盘存储格式 2.2 使用数据库中的数据 0.3 利用Web API操作网络资源 1. 读 ...
随机推荐
- 使用 Blueprint 要注意 render_template 函数
此文章主要是为了记录在使用 Flask 的过程中遇到的问题.本章主要讨论 render_template 函数的问题. 使用 Flask 的同学都应该知道,项目中的 url 和视图函数是在字典里一一对 ...
- CSS - 定位属性position使用详解(static、relative、fixed、absolute)
position 属性介绍 (1)position 属性自 CSS2 起就有了,该属性规定元素的定位类型.所有主流浏览器都支持 position 属性. (2)position 的可选值有四个:sta ...
- 论文阅读总结-Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records
一.论文提出的方法: 使用进入ICU前48h的用药特征作为预测因子预测重症监护患者的死亡率和ICU住院时间. 用到了联邦学习,自编码器,k-means聚类算法,社区检测. 数据集:从50家患者人数超过 ...
- 【Android开发】【布局】几个常用布局构成的简单demo
图image1.jpg,就是常用的 底部菜单栏 + Fragment联动 使用 RadioGroup + Fragment 图image2.jpg ,就是 TabLayout + ViewPager ...
- 一个抽取百度定位的教程(下载百度地图Demo+配置+抽取)
效果展示 已经下载Demo的可以直接到第五步,已经配置好的并可以运行的可以直接到第七步. 1.在浏览器搜索 " 百度定位API ",点击下面这个链接 2.翻到最下面找到并点击 &q ...
- 论文解读(Graph-MLP)《Graph-MLP: Node Classification without Message Passing in Graph》
论文信息 论文标题:Graph-MLP: Node Classification without Message Passing in Graph论文作者:Yang Hu, Haoxuan You, ...
- conn username/password@servicename
conn username/password 方式连接的时候,会碰到这样的错误问题 oracle@prd:/home/oracle/impdir$sqlplus /nolog SQL*Plus: Re ...
- nfs客户端的一次处理
为什么要说这个呢,由于节点环境不一致,导致在重建pod时,我们暂且叫该pod为 cxpod,cxpod所在宿主机出现了问题现象如下:一.cxpod始终处于创建中 ContainerCreating [ ...
- go 中 select 源码阅读
深入了解下 go 中的 select 前言 1.栗子一 2.栗子二 3.栗子三 看下源码实现 1.不存在 case 2.select 中仅存在一个 case 3.select 中存在两个 case,其 ...
- Cesium DrawCommand [1] 不谈地球 画个三角形
目录 0. 前言 0.1. 源码中的 DrawCommand 1. 创建 1.1. 构成要素 - VertexArray 1.2. 构成要素 - ShaderProgram 1.3. 构成要素 - W ...