c语言中的链表
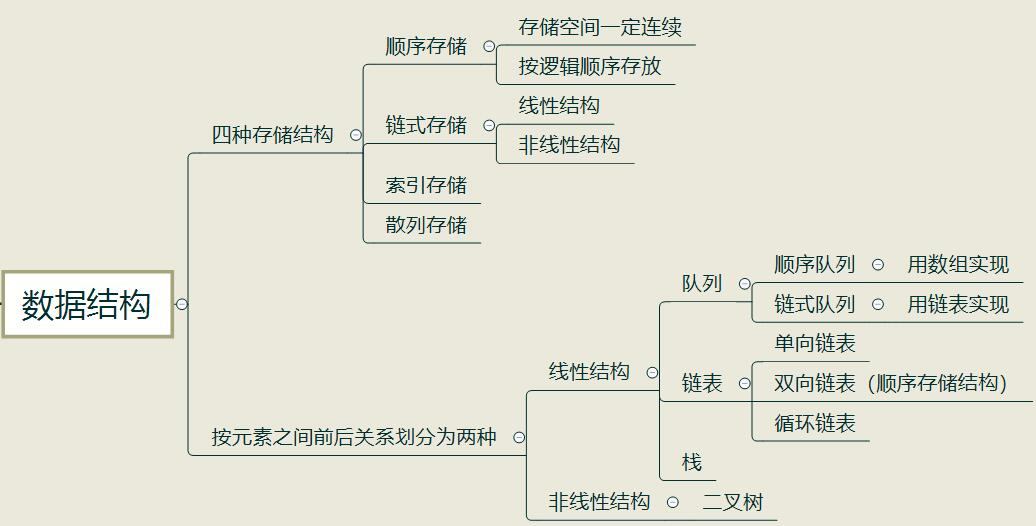
线性结构:有且只有一个根节点,且每个节点最多有一个直接前驱和一个直接后继的非空数据结构
非线性结构:不满足线性结构的数据结构
链表(单向链表的建立、删除、插入、打印)
1、链表一般分为:
单向链表
双向链表
环形链表
2、基本概念
链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性表中的数据,存储单元不一定是连续的,
且链表的长度不是固定的,链表数据的这一特点使其可以非常的方便地实现节点的插入和删除操作
链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构,
除了存储元素本身的信息外,还要存储其直接后继信息,因此,每个节点都包含两个部分,第一部分称为链表的数据区域,用于存储元素本身的数据信息,这里用data表示,
它不局限于一个成员数据,也可是多个成员数据,第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,这里用next表示,
next的值实际上就是下一个节点的地址,当前节点为末节点时,next的值设为空指针
1 struct link
2 {
3 int data;
4 struct link *next;
5 };
像上面这种只包含一个指针域、由n个节点链接形成的链表,就称为线型链表或者单向链表,链表只能顺序访问,不能随机访问,链表这种存储方式最大缺点就是容易出现断链,
一旦链表中某个节点的指针域数据丢失,那么意味着将无法找到下一个节点,该节点后面的数据将全部丢失
3、链表与数组比较
数组(包括结构体数组)的实质是一种线性表的顺序表示方式,它的优点是使用直观,便于快速、随机地存取线性表中的任一元素,但缺点是对其进行 插入和删除操作时需要移动大量的数组元素,同时由于数组属于静态内存分配,定义数组时必须指定数组的长度,程序一旦运行,其长度就不能再改变,实际使用个数不能超过数组元素最大长度的限制,否则就会发生下标越界的错误,低于最大长度时又会造成系统资源的浪费,因此空间效率差
4、单向链表的建立
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 struct link *AppendNode (struct link *head);
5 void DisplyNode (struct link *head);
6 void DeletMemory (struct link *head);
7
8 struct link
9 {
10 int data;
11 struct link *next;
12 };
13
14 int main(void)
15 {
16 int i = 0;
17 char c;
18 struct link *head = NULL; //链表头指针
19 printf("Do you want to append a new node(Y/N)?");
20 scanf_s(" %c", &c);
21 while (c == 'Y' || c == 'y')
22 {
23 head = AppendNode(head);//向head为头指针的链表末尾添加节点
24 DisplyNode(head); //显示当前链表中的各节点的信息
25 printf("Do your want to append a new node(Y/N)");
26 scanf_s(" %c", &c);
27 i++;
28 }
29 printf("%d new nodes have been apended", i);
30 DeletMemory(head); //释放所有动态分配的内存
31
32 return 0;
33 }
34 /* 函数功能:新建一个节点并添加到链表末尾,返回添加节点后的链表的头指针 */
35 struct link *AppendNode(struct link *head)
36 {
37 struct link *p = NULL, *pr = head;
38 int data;
39 p = (struct link *)malloc(sizeof(struct link));//让p指向新建的节点
40 if (p == NULL) //若新建节点申请内存失败,则退出程序
41 {
42 printf("No enough memory to allocate\n");
43 exit(0);
44 }
45 if (head == NULL) //若原链表为空表
46 {
47 head = p; //将新建节点置为头节点
48 }
49 else //若原链表为非空,则将新建节点添加到表尾
50 {
51 while (pr->next != NULL)//若未到表尾,则移动pr直到pr指向表尾
52 {
53 pr = pr->next; //让pr指向下一个节点
54 }
55 pr->next = p; //让末节点的指针指向新建的节点
56 }
57 printf("Input node data\n");
58 scanf_s("%d", &data); //输入节点数据
59 p->data = data; //将新建节点的数据域赋值为输入的节点数据值
60 p->next = NULL; //将新建的节点置为表尾
61 return head; //返回添加节点后的链表的头指针
62 }
63 /* 函数的功能:显示链表中所有节点的节点号和该节点中的数据项的内容*/
64 void DisplyNode (struct link *head)
65 {
66 struct link *p = head;
67 int j = 1;
68 while (p != NULL) //若不是表尾,则循环打印节点的数值
69 {
70 printf("%5d%10d\n", j, p->data);//打印第j个节点数据
71 p = p->next; //让p指向下一个节点
72 j++;
73 }
74 }
75 //函数的功能:释放head所指向的链表中所有节点占用的内存
76 void DeletMemory(struct link *head)
77 {
78 struct link *p = head, *pr = NULL;
79 while (p != NULL) //若不是表尾,则释放节点占用的内存
80 {
81 pr = p; //在pr中保存当前节点的指针
82 p = p->next;//让p指向下一个节点
83 free(pr); //释放pr指向的当前节点占用的内存
84 }
85 }
上面的代码使用了三个函数AppendNode、DisplyNode、DeletMemory
struct link *AppendNode (struct link *head);(函数作用:新建一个节点并添加到链表末尾,返回添加节点后的链表的头指针)
void DisplyNode (struct link *head);(函数功能:显示链表中所有节点的节点号和该节点中的数据项的内容)
void DeletMemory (struct link *head);(函数功能:释放head所指向的链表中所有节点占用的内存)
(还使用了malloc函数和free函数)
5、malloc函数
作用:用于分配若干字节的内存空间,返回一个指向该内存首地址的指针,若系统不能提供足够的内存单元,函数将返回空指针NULL,函数原型为void *malloc(unsigned int size)
其中size是表示向系统申请空间的大小,函数调用成功将返回一个指向void的指针(void*指针是ANSIC新标准中增加的一种指针类型,
具有一般性,通常称为通用指针或者无类型的指针)常用来说明其基类型未知的指针,即声明了一个指针变量,但未指定它可以指向哪一种基类型的数据,
因此,若要将函数调用的返回值赋予某个指针,则应先根据该指针的基类型,用强转的方法将返回的指针值强转为所需的类型,然后再进行赋值
1 int *pi; 2 pi = (int *)malloc(4);
其中malloc(4)表示申请一个大小为4字节的内存,将malloc(4)返回值的void*类型强转为int*类型后再赋值给int型指针变量pi,即用int型指针变量pi指向这段存储空间的首地址
若不能确定某种类型所占内存的字节数,则需使用sizeof()计算本系统中该类型所占的内存字节数,然后再用malloc()向系统申请相应字节数的存储空间
pi = (int *)malloc(sizeof(int));
6、free函数
释放向系统动态申请的由指针p指向的内存存储空间,其原型为:Void free(void *p);该函数无返回值,唯一的形参p给出的地址只能由malloc()和calloc()申请内存时返回的地址,
该函数执行后,将以前分配的指针p指向的内存返还给系统,以便系统重新分配
为什么要用free释放内存
(在程序运行期间,用动态内存分配函数来申请的内存都是从堆上分配的,动态内存的生存期有程序员自己来决定,使用非常灵活,但也易出现内存泄漏的问题,
为了防止内存泄漏的发生,程序员必须及时调用free()释放已不再使用的内存)
7、单向链表的删除操作
删除操作就是将一个待删除的节点从链表中断开,不再与链表的其他节点有任何联系
需考虑四种情况:
1.若原链表为空表,则无需删除节点,直接退出程序
2.若找到的待删除节点p是头节点,则将head指向当前节点的下一个节点(p->next),即可删除当前节点
3.若找到的待删除节点不是头节点,则将前一节点的指针域指向当前节点的下一节点(pr->next = p->next),即可删除当前节点,当待删除节点是末节点时,
由于p->next值为NULL,因此执行pr->next = p->next后,pr->next的值也变成NULL,从而使pr所指向的节点由倒数第2个节点变成了末节点
4.若已搜索到表尾(p->next == NULL),仍未找到待删除节点,则显示“未找到”,注意:节点被删除后,只是将它从链表中断开而已,它仍占用着内存,必须释放其所占的内存,否则将出现内存泄漏
(头结点不是头指针,注意两者区别)
8、头节点和头指针
头指针存储的是头节点内存的首地址,头结点的数据域可以存储如链表长度等附加信息,也可以不存储任何信息
参考链接---头指针和头节点:https://www.cnblogs.com/didi520/p/4165486.html
https://blog.csdn.net/qq_37037492/article/details/78453333
https://www.cnblogs.com/marsggbo/p/6622962.html
https://blog.csdn.net/hunjiancuo5340/article/details/80671298
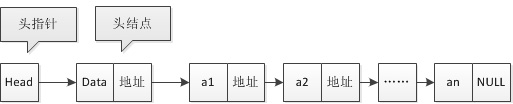
(图片出处:https://blog.csdn.net/hunjiancuo5340/article/details/80671298)
值得注意的是:
1.无论链表是否为空,头指针均不为空。头指针是链表的必要元素
2.链表可以没有头节点,但不能没有头指针,头指针是链表的必要元素
3.记得使用free释放内存
单向链表的删除操作实现

1 struct link *DeleteNode (struct link *head, int nodeData)
2 {
3 struct link *p = head, *pr = head;
4
5 if (head == NULL)
6 {
7 printf("Linked table is empty!\n");
8 return 0;
9 }
10 while (nodeData != p->data && p->next != NULL)
11 {
12 pr = p; /* pr保存当前节点 */
13 p = p->next; /* p指向当前节点的下一节点 */
14 }
15 if (nodeData == p->data)
16 {
17 if (p == head) /* 如果待删除为头节点 (注意头指针和头结点的区别)*/
18 {
19 head = p->next;
20 }
21 else /* 如果待删除不是头节点 */
22 {
23 pr->next = p->next;
24 }
25 free(p); /* 释放已删除节点的内存 */
26 }
27 else /* 未发现节点值为nodeData的节点 */
28 {
29 printf("This Node has not been found");
30 }
31
32 return head;
33 }
9、单向链表的插入
向链表中插入一个新的节点时,首先由新建一个节点,将其指针域赋值为空指针(p->next = NULL),然后在链表中寻找适当的位置执行节点的插入操作,
此时需要考虑以下四种情况:
1.若原链表为空,则将新节点p作为头节点,让head指向新节点p(head = p)
2.若原链表为非空,则按节点值的大小(假设节点值已按升序排序)确定插入新节点的位置,若在头节点前插入新节点,则将新节点的指针域指向原链表的头节点(p->next = head),且让head指向新节点(head =p)
3.若在链表中间插入新节点,则将新节点的指针域之下一节点(p->next = pr -> next),且让前一节点的指针域指向新节点(pr->next = p)
4.若在表尾插入新节点,则末节点指针域指向新节点(p->next = p)
单向链表的插入操作实现
1 /* 函数功能:向单向链表中插入数据 按升序排列*/
2 struct link *InsertNode(struct link *head, int nodeData)
3 {
4 struct link *p = head, *pr = head, *temp = NULL;
5
6 p = (struct link *)malloc(sizeof(struct link));
7 if (p == NULL)
8 {
9 printf("No enough meomory!\n");
10 exit(0);
11 }
12 p->next = NULL; /* 待插入节点指针域赋值为空指针 */
13 p->data = nodeData;
14
15 if (head == NULL) /* 若原链表为空 */
16 {
17 head = p; /* 插入节点作头结点 */
18 }
19 else /* 原链表不为空 */
20 {
21 while (pr->data < nodeData && pr->next != NULL)
22 {
23 temp = pr; /* 保存当前节点的指针 */
24 pr = pr->next; /* pr指向当前节点的下一节点 */
25 }
26 if (pr->data >= nodeData)
27 {
28 if (pr == head) /* 在头节点前插入新节点 */
29 {
30 p->next = head; /* 新节点指针域指向原链表头结点 */
31 head = p; /* 头指针指向新节点 */
32 }
33 else
34 {
35 pr = temp;
36 p->next = pr->next; /* 新节点指针域指向下一节点 */
37 pr->next = p; /* 让前一节点指针域指向新节点 */
38 }
39 }
40 else /* 若在表尾插入新节点 */
41 {
42 pr->next = p; /* 末节点指针域指向新节点*/
43 }
44 }
45
46 return head;
47 }
c语言中的链表的更多相关文章
- C语言中链表怎么删除结点?
第一个方法: /*根据姓名删除链表的中的学生记录*/ void deleteByName(struct STUDENT * head) { struct STUDENT *p,*q; ]; if(he ...
- C语言中的栈和堆
原文出处<http://blog.csdn.net/xiayufeng520/article/details/45956305#t0> 栈内存由编译器分配和释放,堆内存由程序分配和释放. ...
- javascript中的链表结构
1.定义 很多编程语言中数组的长度是固定的,就是定义数组的时候需要定义数组的长度,所以当数组已经被数据填满的时候,需要再加入新的元素就很困难.只能说在部分变成语言中会有这种情况,在javascript ...
- C 语言中的指针和内存泄漏
引言对于任何使用 C 语言的人,如果问他们 C 语言的最大烦恼是什么,其中许多人可能会回答说是指针和内存泄漏.这些的确是消耗了开发人员大多数调试时间的事项.指针和内存泄漏对某些开发人员来说似乎令人畏惧 ...
- C语言中的内存分配与释放
C语言中的内存分配与释放 对C语言一直都是抱着学习的态度,很多都不懂,今天突然被问道C语言的内存分配问题,说了一些自己知道的,但感觉回答的并不完善,所以才有这篇笔记,总结一下C语言中内存分配的主要内容 ...
- C语言实现单链表-03版
在C语言实现单链表-02版中我们只是简单的更新一下链表的组织方式: 它没有更多的更新功能,因此我们这个版本将要完成如下功能: Problem 1,搜索相关节点: 2,前插节点: 3,后追加节点: 4, ...
- C语言实现单链表-02版
我们在C语言实现单链表-01版中实现的链表非常简单: 但是它对于理解单链表是非常有帮助的,至少我就是这样认为的: 简单的不能再简单的东西没那么实用,所以我们接下来要大规模的修改啦: Problem 1 ...
- C语言中的指针和内存泄漏
引言 对于任何使用C语言的人,如果问他们C语言的最大烦恼是什么,其中许多人可能会回答说是指针和内存泄漏.这些的确是消耗了开发人员大多数调试时间的事项.指针和内存泄漏对某些开发人员来说似乎令人畏惧,但是 ...
- C语言中的堆与栈20160604
首先声明这里说的是C语言中的堆与栈,并不是数据结构中的!一.前言介绍:C语言程序经过编译连接后形成编译.连接后形成的二进制映像文件是静态区域由代码段和数据段(由二部分部分组成:只读数据 段,未初始化数 ...
- C语言中堆和栈的区别
原文:http://blog.csdn.net/tigerjibo/article/details/7423728 C语言中堆和栈的区别 一.前言: C语言程序经过编译连接后形成编译.连接后形成的二进 ...
随机推荐
- SDIO接口WIFI&BT之相关常备知识
SDIO接口WIFI&BT之相关常备知识 <VBAT>:>Main Power Voltage Soure Input 主电源输入(SDIO WIFI目前知道的都是 ...
- 强烈推荐的elasticsearch集群连接工具: elasticvue
个人感觉非常棒的es-cluster连接工具, 检查状态什么的, 一目了然, 支持中文超方便, 比elasticSearchHead好用多了. 安装方法打开微软浏览器edge-商城搜索-Elastic ...
- 220327_IDEA调试debug时step into看不了方法内部的解决办法
220327_问题解决_IDEA Debug时stepinto无法进入方法内部的解决方法 File Settings Build,Execution,Deployment Debugger Stepp ...
- C语言中的转义字符\b的含义
\b的含义是,将光标从当前位置向前(左)移动一个字符(遇到\n或\r则停止移动),并从此位置开始输出后面的字符(空字符\0和换行符\n除外) 参考: https://blog.csdn.net/har ...
- Harbor离线安装
一.安装docker-compose 1-1. #安装方式一 curl -SL https://github.com/docker/compose/releases/download/v2.11.2/ ...
- VScode打开文件夹位置技巧
VScode在打开文件夹,弹出对话框的时候,去文件夹(应用)到达该路径,对话框中的路径自动变为当前文件夹(应用)的路径.去文件夹(应用)到达该路径
- Java本地缓存解决方案---使用Google的CacheBuilder
一.背景 当业务实现上需要用到本地缓存,来解决一些数据量相对较小但是频繁访问数据的场景,可以采用Google的CacheBuilder解决方案. 二.代码实现 1. 首先在maven中引入下面的包 & ...
- Operator包的应用
# -*-coding:utf-8-*- import operator print(operator.add(1,1)) # 加 print(operator.sub(2,1)) #减 ...
- 浅谈前端自动化构建(Grunt、gulp。webpack)
前言 现在的前端开发已经不再仅仅只是静态网页的开发了,日新月异的前端技术已经让前端代码的逻辑和交互效果越来越复杂,更加的不易于管理,模块化开发和预处理框架把项目分成若干个小模块,增加了最后发布的困难, ...
- NavicatPremium16破解!!!!!亲测可用!!!!!!!!!!!!!!!!!
前言 Navicat premium是一款数据库管理工具,是一个可多重连线资料库的管理工具,它可以让你以单一程式同时连线到 MySQL.SQLite.Oracle 及 PostgreSQL 资料库,让 ...