JavaEE Day12 Xml
- 标记语言:标签构成的语言
- 可扩展:标签都是自定义的 <user> <student>
- 存储数据
- 作为配置文件使用
- 在网络中传输(web service,纯文本,跨平台,作为数据的载体)
- w3c(World Wide Web Consortium)是xml和html的亲爹,万维网联盟。(万维网联盟创建于1994年,是Web技术领域最具权威和影响力的国际中立性技术标准机构。到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)、可扩展标记语言XML(标准通用标记语言下的一个子集))
- 之前与html竞争,现在不再与html竞争,而是与properties竞争
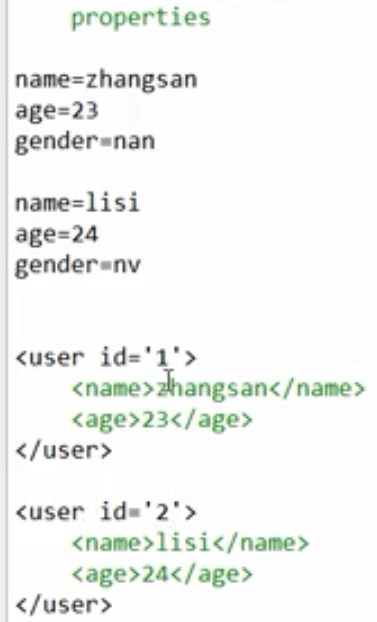
- 区别
- xml标签是自定义的,html的标签是预定义的
- xml的语法严格,html的语法松散
- xml是存储数据的,html是展示数据的
- 基本语法
- xml文档的后缀名是.xml
- xml第一行必须定义为文档声明<?xml version='1.0' ?>

- xml文档中有且仅有一个根标签
- 属性值必须通过引号引起来,单双都可以
- 标签必须正确关闭,要么自闭和,要么是围堵标签
- xml标签名称区分大小写
- 快速入门
<?xml version='1.0' ?>
<users>
<user id='1'>
<name>zhangsan</name>
<age>23</age>
<gender>male</gender>
</user>
<user id='2'>
<name>lisi</name>
<age>18</age>
<gender>female</gender>
</user>
</users>- 组成部分
- 文档声明
- 格式:<?xml 属性列表 ?>
- 属性列表:
- version:版本号1.0,必须的属性,不写报错
- encoding:编码方式。告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1(告诉浏览器解码方式为8859-1,文件真实格式为GBK);如果使用UTF-8,则文件也要为UTF-8编码【IDEA可以根据此值自动修改文件的编码】
- standalone:是否独立,yes / no,是否依赖于其他文件
- 指令(了解):结合css <?xml-stylesheet type="text/css" href="a.css" ?>
- 标签:标签名称自定义的
- 规则:
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
- 属性:
- id属性值唯一
- 文本内容
- CDATA区:在该区域中的数据会被原样展示
- <![CDATA[ 数据 ]]>
- 约束
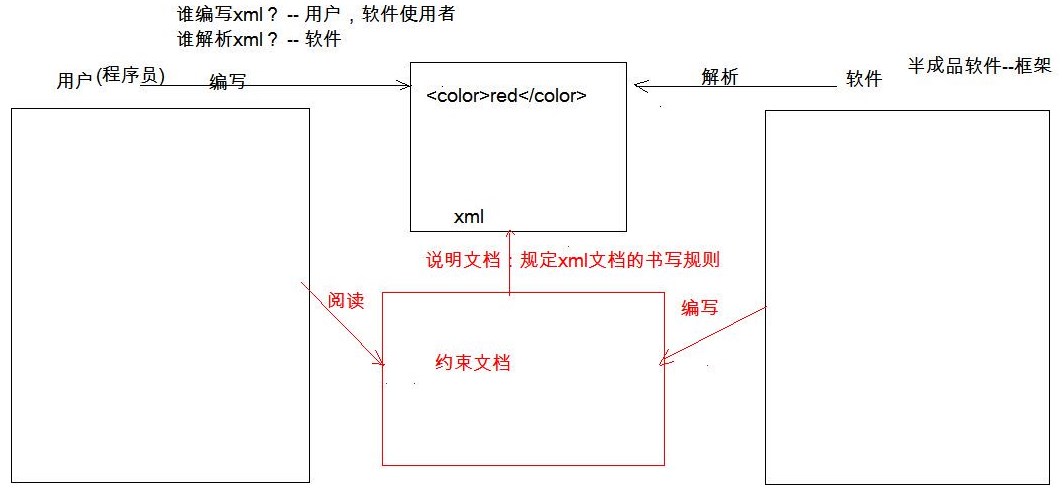
- 能够在xml中引入约束文档
- 能够简单的读懂约束文档
- DTD:一种简单的约束技术
- Schema:一种复杂的约束技术
- 引入dtd文档到xml文档中
- 内部dtd:将约束规则定义在xml文档中
- 外部dtd:将约束的规则定义在外部的dtd文件中
- 本地:<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
- 网络:<!DOCTYPE 根标签名 PUBLIC "dtd文件的名字" "dtd文件的URL位置">
<!ELEMENT students (student*) >
<!--*表示0次或多次,+表示一次或多次-->
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED><?xml version="1.0" encoding="UTF-8" ?>
<!--<!DOCTYPE students SYSTEM "student.dtd">-->
<!--内部DTD-->
<!DOCTYPE students [
<!ELEMENT students (student*) >
<!--*表示0次或多次,+表示一次或多次-->
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
]>
<students>
<student number="s001">
<name>张三</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="s002">
<name>李四</name>
<age>18</age>
<sex>female</sex>
</student>
</students><?xml version="1.0"?>
<xsd:schema xmlns="http://www.itcast.cn/xml"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn/xml" elementFormDefault="qualified">
<xsd:element name="students" type="studentsType"/>
<xsd:complexType name="studentsType">
<xsd:sequence>
<xsd:element name="student" type="studentType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="studentType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element name="age" type="ageType" />
<xsd:element name="sex" type="sexType" />
</xsd:sequence>
<xsd:attribute name="number" type="numberType" use="required"/>
</xsd:complexType>
<xsd:simpleType name="sexType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="male"/>
<xsd:enumeration value="female"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="ageType">
<xsd:restriction base="xsd:integer">
<xsd:minInclusive value="0"/>
<xsd:maxInclusive value="256"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="numberType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="heima_\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
<?xml version="1.0" encoding="UTF-8" ?>
<!--
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
xmlns="http://www.itcast.cn/xml"
>
<!--可以加前缀xmlns:a,适用于多个xsd明明空间起名
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
xsi:schemaLocation="http://www.itcast.cn/xml1 student1.xsd"
-->
<student number="heima_0001">
<name>zhangsan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="heima_0002">
<name>lisi</name>
<age>18</age>
<sex>female</sex>
</student>
</students>- 操作xml文档
- 解析(读取):将文档中的数据读取到内存中【主要】
- 写入:将内存中的数据保存在xml文档中,持久化存储
- DOM思想【服务器端】:document object model,将标记语言 文档一次性加载进 内存,在内存中形成一棵dom树
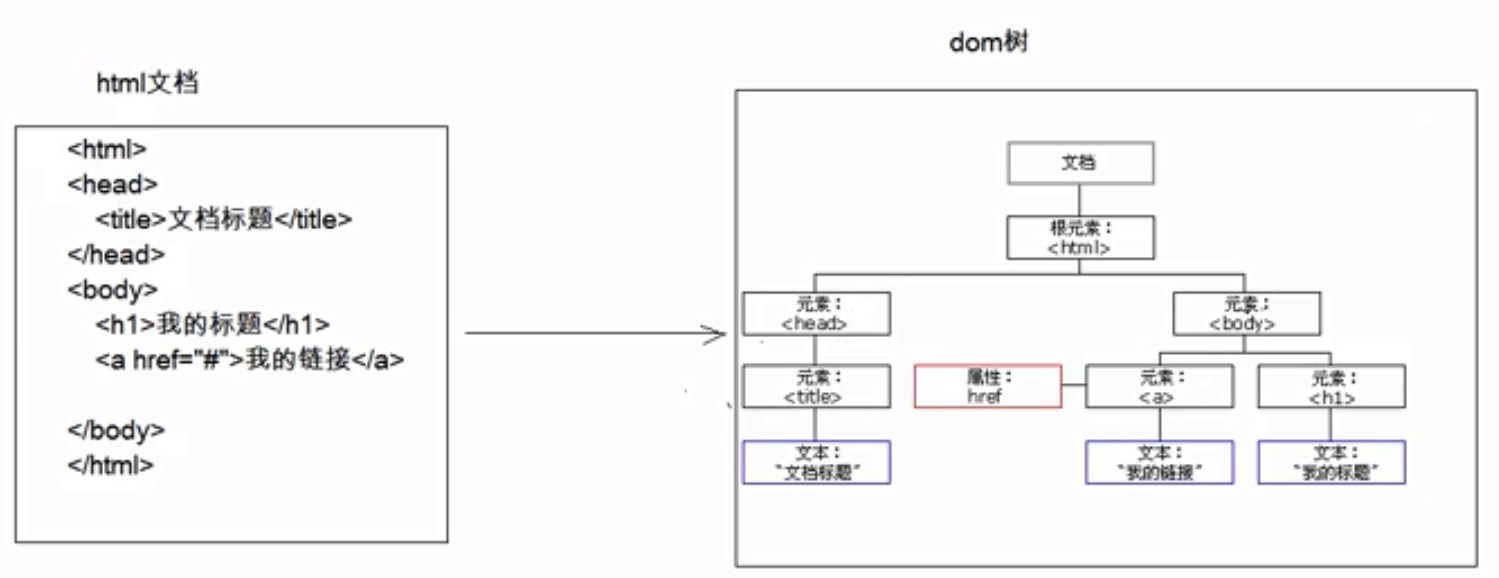
- 优点:操作方便,可以对文档进行CRUD的所有操作(appendChild)
- 缺点:dom树消耗内存较大,不适用于内存较小的设备
- SAX思想【移动端,安卓等】:逐行读取,基于事件驱动,根据指针逐行读取,设置监听器判断标签
- 优点:不占内存,适用于内存较小的设备
- 缺点:只能读取,不能增删改
- JAXP:SUN公司提供的解析器,支持dom和sax两种思想,官方提供,性能差,代码书写麻烦
- DOM4J:一款非常优秀的解析器,基于dom实现
- Jsoup:是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。【也可以用来解析xml】
- PULL:安卓Android内置解析器,sax思想
- 步骤
- 导入jar包
- 获取document对象
- 获取对应的标签element对象
- 获取数据
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/**
* Jsoup快速入门
*/
public class JsoupDemo1 {
public static void main(String[] args) throws IOException {
//2.获取document对象,根据xml文档获取
//2.1获取student.xml的path,通过类加载器
String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();
//2.解析xml文档,加载文档进内存,获取dom树--->Documenr
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象Element标签对象,需求:获取name下的tom值
Elements elements = document.getElementsByTag("name");//当做arraylist
System.out.println(elements.size());
//3.1 获取第一个name的Element对象,可以通过索引拿到
Element element = elements.get(0);
//3.2 获取数据
String name = element.text();
System.out.println(name);
}
}- Jsoup:工具类,可以 解析html文档或xml文档,返回Document
- Document:文档对象:代表内存中的dom树
- Elements:元素Element对象的集合,可以当做ArrayList<Element>来使用
- Element:元素对象,获取名称属性或文本
- Node:节点对象,是上述对象的父亲
- 是Document和Element的父类
- static Document parse(File in, String charsetName) 解析html或xml文档,返回Document
- static Document parse(String html) 解析字符串
- static Document parse(URL url, int timeoutMillis) 通过网络路径获取指定的html文档或xml文档
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/**
* Jsoup对象功能
*/
public class JsoupDemo2 {
public static void main(String[] args) throws IOException {
//2.获取document对象,根据xml文档获取
//2.1获取student.xml的path,通过类加载器
String path = JsoupDemo2.class.getClassLoader().getResource("student.xml").getPath();
//2.解析xml文档,加载文档进内存,获取dom树--->Documenr
/*Document document = Jsoup.parse(new File(path), "utf-8");
System.out.println(document);*/
//第二种方式static Document parse(String html) 解析字符串
/* String str="<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"\n" +
"<students>\n" +
"\t<student number=\"heima_0001\">\n" +
"\t\t<name>zhangsan</name>\n" +
"\t\t<age>23</age>\n" +
"\t\t<sex>male</sex>\n" +
"\t</student>\n" +
"\t<student number=\"heima_0002\">\n" +
"\t\t<name>lisi</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>female</sex>\n" +
"\t</student>\n" +
" </students>";
Document document = Jsoup.parse(str);
System.out.println(document);*/
//第三种方式static Document parse(URL url, int timeoutMillis) 通过网络路径获取指定的html文档或xml文档
//可以进行爬虫
URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin");//代表网络中的资源路径
Document document = Jsoup.parse(url, 5000);
System.out.println(document);
}
}- Document:文档对象:代表内存中的dom树
- 主要用于获取Element 对象 Document extends Node

- 常用方法:
- Elements getElementsByTag(String tagName):根据标签名称获取元素对象集合
- Elements getElementsByAttribute(String key):根据属性名称获取元素对象集合
- Elements getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
- Element getElementById(String id):根据id属性值获取唯一的Element对象
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/**
* Document/Element对象功能
*/
public class JsoupDemo3 {
public static void main(String[] args) throws IOException {
//1获取student.xml的path,通过类加载器
String path = JsoupDemo3.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象
//3.1获取所有student对象
Elements elements = document.getElementsByTag("student");
System.out.println(elements);
System.out.println("_________");
//3.2获取属性名为id的元素对象们
Elements elements1 = document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("_________");
//3.3获取number属性值为heima_0001的元素对象
Elements elements2 = document.getElementsByAttributeValue("number", "heima_0001");
System.out.println(elements2);
//3.3获取id属性值的元素对象
Element itcast = document.getElementById("itcast");
System.out.println(itcast);
}
}- 获取子元素对象【子标签】
- Elements getElementsByTag(String tagName):根据标签名称获取元素对象集合
- Elements getElementsByAttribute(String key):根据属性名称获取元素对象集合
- Elements getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
- Element getElementById(String id):根据id属性值获取唯一的Element对象
- 获取属性值
- public String attr(String attributeKey):根据属性名称获取属性值
- 获取文本内容
- String text():获取文本内容(所有子标签的纯文本内容)
- String html():获取标签提的所有内容,包括子标签的字符串内容(包括子标签的标签和文本 内容)
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/**
* Element对象功能
*/
public class JsoupDemo4 {
public static void main(String[] args) throws IOException {
//1获取student.xml的path,通过类加载器
String path = JsoupDemo4.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
/*
功能
获取子元素对象【子标签】
Elements getElementsByTag(String tagName):根据标签名称获取元素对象集合
Elements getElementsByAttribute(String key):根据属性名称获取元素对象集合
Elements getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
Element getElementById(String id):根据id属性值获取唯一的Element对象
获取属性值
public String attr(String attributeKey):根据属性名称获取属性值
获取文本内容
String text():获取文本内容
String html():获取标签提的所有内容,包括子标签的字符串内容
* */
//通过document对象获取name标签 ,获取所有的name标签
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
System.out.println("____________________________");
//通过Element对象获取子标签对象
Element element_student = document.getElementsByTag("student").get(0);
Elements ele_name = element_student.getElementsByTag("name");
System.out.println(ele_name.size());
//获取属性,如number的属性值
String number = element_student.attr("NUMBER");
System.out.println(number);
//获取name标签的文本内容
String text = ele_name.text();
String html = ele_name.html();
System.out.println(text);
System.out.println(html);
}
}- selector:选择器【Element对象的方法,其子类Document也可以调用】
- 方法:Elements select(String cssQuery)
- 语法:参考Selector中定义的语法
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/**
* 选择器查询
*/
public class JsoupDemo5 {
public static void main(String[] args) throws IOException {
//1获取student.xml的path,通过类加载器
String path = JsoupDemo5.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.查询name标签
/*
之前:
div{
}
* */
Elements elements = document.select("name");
System.out.println(elements);
System.out.println("====================");
//4.查询id值为 itcast的元素
/*
之前:
#itcast{
}
* */
Elements elements1 = document.select("#itcast");
System.out.println(elements1);
System.out.println("====================");
//5.获取student标签且number属性值为heima_0001的age子标签
Elements elements2 = document.select("student[number='heima_0001'] > age");
System.out.println(elements2);
}
}- XPath:w3c提供的xml快捷查询语法【看w3c文档】
- XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
- 根据dom树操作,使用JSoup的XPath,需要 额外导入一个 jar包JsoupXpath-0.3.2
- 查询w3cschool的参考手册,使用xpath的语法完成查询
package cn.itcast.xml.jsoup;
import cn.wanghaomiao.xpath.exception.XpathSyntaxErrorException;
import cn.wanghaomiao.xpath.model.JXDocument;
import cn.wanghaomiao.xpath.model.JXNode;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.util.List;
/**
* XPath查询
*/
public class JsoupDemo6 {
public static void main(String[] args) throws IOException, XpathSyntaxErrorException {
//1获取student.xml的path,通过类加载器
String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.根据Document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4.结合xpath语法查询
//4.1查询所有的student标签
List<JXNode> jxNodes = jxDocument.selN("//student");
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
//Element element = jxNode.getElement();
}
System.out.println("=======================");
//4.2查询所有student标签下的name标签
List<JXNode> jxNodes2 = jxDocument.selN("//student/name");
for (JXNode jxNode : jxNodes2) {
System.out.println(jxNode);
//Element element = jxNode.getElement();
}
System.out.println("=======================");
//4.3查询student下带id的name标签
List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
//Element element = jxNode.getElement();
}
System.out.println("=======================");
//4.4查询student下带id的name标签,并且id属性值为itcast
List<JXNode> jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
//Element element = jxNode.getElement();
}
}
}JavaEE Day12 Xml的更多相关文章
- JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
原 JavaEE实战--XML文档DOM.SAX.STAX解析方式详解 2016年06月22日 23:10:35 李春春_ 阅读数:3445 标签: DOMSAXSTAXJAXPXML Pull 更多 ...
- JavaEE:XML解析
XML解析技术概述1.XML 技术主要企业应用1)存储和传输数据 2)作为框架的配置文件2.使用xml 存储和传输数据涉及到以下两点1)通过程序生成xml2)读取xml 中数据 ---- xml 解析 ...
- [JavaEE] applicationContext.xml配置文件使用合集
配置实例 – 1 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http ...
- JavaEE web.xml 中ContextLoaderListener的解析
ContextLoaderListener监听器的作用就是启动Web容器时,自动装配ApplicationContext的配置信息.因为它实现了ServletContextListener这个接口,在 ...
- 不同servlet版本的web.xml的头部信息
servlet2.5 <?xml version="1.0" encoding="UTF-8"?> <web-app version=&quo ...
- servlet2.3/2.5/3.0/3.1的xml名称空间备忘
The web.xml is a configuration file to describe how a web application should be deployed. Here’re 5 ...
- web.xml不同的头文件
<转自:http://blog.csdn.net/qq_16313365/article/details/53783288> 1. Servlet 3.1 Java EE 7 XML sc ...
- web.xml配置参数context-param和init-param的区别
web.xml配置参数context-param和init-param的区别 (2009-04-13 10:29:01) 转载▼ 标签: 杂谈 分类: JavaEE web.xml里面可以定义两种参数 ...
- JSP自定义不带属性和标签体的简单标签
1. 新建HelloTag类 2. 添加额外的Jar包 (1). 右键项目 -> Build Path -> Configure Build Path -> Libraries -& ...
- SpringMVC整合Mybatis的流程
前提:如何要整合SpringMVC 与Mybatis,首先要会配置SpringMVC 第一部分:配置SpringMVC 第一步:导入jar包 第二步:构建一个请求 <%@ page langua ...
随机推荐
- 【学习笔记】GBDT算法和XGBoost
前言 这一篇内容我学了足足有五个小时,不仅仅是因为内容难以理解, 更是因为前面CART和提升树的概念和算法本质没有深刻理解,基本功不够就总是导致自己的理解会相互在脑子里打架,现在再回过头来,打算好好总 ...
- 在 Traefik 中使用 Kubernetes Gateway API
文章转载自:https://mp.weixin.qq.com/s/QYy8ETBB-xqU0IMI7YuTWw Gateway API(之前叫 Service API)是由 SIG-NETWORK 社 ...
- 在 K8S 上部署以 mysql 数据库作为后端存储的单机版 nacos
Nacos 被用于: 服务发现 微服务配置信息管理 部署 nacos 时,需要用到如下两个镜像,这两个镜像均来自于 nacos 官方发布到 docker hub 的镜像, nacos/nacos-se ...
- 我的 Kafka 旅程 - Producer
原理阐述 Producer生产者是数据的入口,它先将数据序列化后于内存的不同队列中,它用push模式再将内存中的数据发送到服务端的broker,以追加的方式到各自分区中存储.生产者端有两大线程,以先后 ...
- 【前端必会】使用indexedDB,降低环境搭建成本
背景 学习前端新框架.新技术.如果需要做一些数据库的操作来增加demo的体验(CURD流程可以让演示的体验根据丝滑) 最开始的时候一个演示程序我们会调用后台,这样其实有一点弊端,就是增加了开发和维护成 ...
- 了解Pytorch|Get Started with PyTorch
一个开源的机器学习框架,加速了从研究原型到生产部署的路径. !pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple import ...
- PHP全栈开发(八):CSS Ⅴ 超链接 style
CSS里面有专门针对超链接的选择器,也就是他们: a:link - 正常,未访问过的链接 a:visited - 用户已访问过的链接 a:hover - 当用户鼠标放在链接上时 a:active - ...
- POJ3311 Hie with the Pie(状压DP,Tsp)
本题是经典的Tsp问题的变形,Tsp问题就是要求从起点出发经过每个节点一次再回到起点的距离最小值,本题的区别就是可以经过一个节点不止一次,那么先预处理出任意两点之间的最短距离就行了,因为再多走只会浪费 ...
- 洛谷P1120 小木棍 (搜索+剪枝)
搜索的经典题. 我们要求木根的最小长度,就要是木根的数量尽可能多,可以发现木根的长度一定可以整除所有小木棒的总长度,从小到大枚举这个可能的长度,第一次有解的就是答案. 关心的状态:当前正在拼哪根木棍, ...
- Python生成10个八位随机密码
#生成10个八位随机密码 import random lst1=[ chr(i) for i in range(97,123) ] #生成26为字母列表 lst2=[i for i in range( ...