【爬虫】让我沉醉的python爬虫技术
今天终于有机会好好学习我一直梦寐以求想掌握的爬虫技术,其实爬虫技术涉及的面不多,我力求做到精通写在简历上。
1.工程分析流程
(1)需求分析
①目标网站;②抓取内容;③存储格式。
(2)项目实施
分析想要抓取的页面标签特点。
(3)写代码
2.想做到抓取网站,首先要下载目标网页【爬取】,一共有三种方法:
(1)爬取网站地图;(2)遍历每个网页的数据库ID;(3)跟踪网页链接。
3.scraping需要注意的问题
(1)代理问题;(2)下载速度限制【访问间隔】;(3)无限链接的爬虫陷阱。
4.抓取数据的三种方法
(1)正则表达式;
正则表达式虽然提供了抓取数据的快捷方式,但是方法过于脆弱。
(2)beautifulsoup4
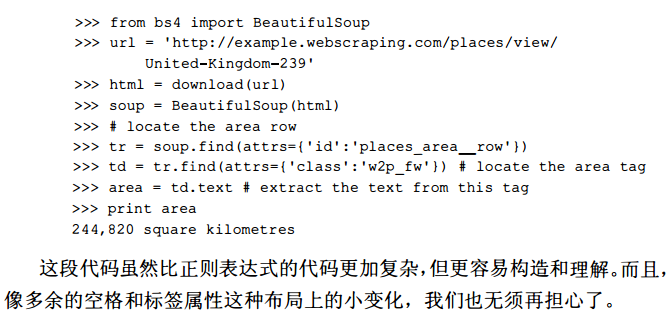
(3)Lxml
性能对比
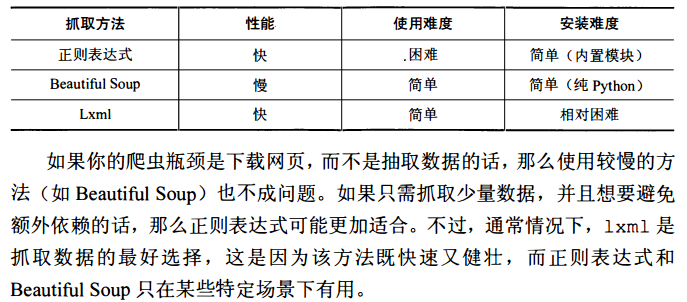
5.下载缓存问题
对于小网站来说,缓存与否并不重要,但是对于大网站来说,重新爬取往往需要花费几周的时间。
【爬虫】让我沉醉的python爬虫技术的更多相关文章
- Python爬虫入门教程 50-100 Python3爬虫爬取VIP视频-Python爬虫6操作
爬虫背景 原计划继续写一下关于手机APP的爬虫,结果发现夜神模拟器总是卡死,比较懒,不想找原因了,哈哈,所以接着写后面的博客了,从50篇开始要写几篇python爬虫的骚操作,也就是用Python3通过 ...
- 【网络爬虫】【python】网络爬虫(一):python爬虫概述
python爬虫的实现方式: 1.简单点的urllib2 + regex,足够了,可以实现最基本的网页下载功能.实现思路就是前面java版爬虫差不多,把网页拉回来,再正则regex解析信息--总结起来 ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python 爬虫入门实战
1. 前言 首先自我介绍一下,我是一个做 Java 的开发人员,从今年下半年开始,一直在各大技术博客网站发表自己的一些技术文章,差不多有几个月了,之前在 cnblog 博客园加了网站统计代码,看到每天 ...
- 小白如何入门 Python 爬虫?
本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫! 想要入门Python 爬虫首先需要解决四个问题 熟悉python编程 了解HTML 了解网络爬虫的基本原理 学习使用python爬虫 ...
- 1,Python爬虫环境的安装
前言 很早以前就听说了Python爬虫,但是一直没有去了解:想着先要把一个方面的知识学好再去了解其他新兴的技术. 但是现在项目有需求,要到网上爬取一些信息,然后做数据分析.所以便从零开始学习Pytho ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- Python爬虫实例:糗百
看了下python爬虫用法,正则匹配过滤对应字段,这里进行最强外功:copy大法实践 一开始是直接从参考链接复制粘贴的,发现由于糗百改版导致失败,这里对新版html分析后进行了简单改进,把整理过程记录 ...
- Python 爬虫个人笔记【目录】
个人笔记,仅供参考 目录 Python爬虫笔记(一) Python 爬虫笔记(二) Python 爬虫笔记(三) Scrapy 笔记(一) Scrapy 笔记(二) Scrapy 笔记(三) Pyth ...
随机推荐
- 解决Vue3使用 Ant Design,出现多个Modal,全是黑屏,导致列表页看不见问题!
尴尬问题 不报错,但是我看着就难受. 求知路上 请教了下强哥,强哥告诉我可能某个样式属性失效引起(无效),建议我F12看下样式. 接着,我F12狂看元素样式,查了一个小时未果,我真抓狂了. 都想明天问 ...
- 马哈鱼间接数据流中的where-group-by子句
马哈鱼间接数据流中的where-group-by子句 本文介绍间接数据流中的where-group-by子句. 1.列在where子句中 WHERE子句中源表中的某些列不影响目标列,但对所选行集至关重 ...
- navicat连接mysql报错1251解决方案
感谢原文作者:XDMFC 原文链接:https://blog.csdn.net/xdmfc/article/details/80263215 问题描述 今天下了个 MySQL8.0,发现Navicat ...
- Redis分布式锁实现原理
关于Redis分布式锁网上有很多优秀的博文,这篇文章仅作为我这段时间遇到的新问题的记录. 1.什么是分布式锁: 在单机部署的情况下,为了保证数据的一致性,不出现脏数据等,就需要使用synchroniz ...
- 类(静态)变量和类(静态)static方法以及main方法、代码块,final方法的使用,单例设计模式
类的加载:时间 1.创建对象实例(new 一个新对象时) 2.创建子类对象实例,父类也会被加载 3.使用类的静态成员时(静态属性,静态方法) 一.static 静态变量:类变量,静态属性(会被该类的所 ...
- Spark算子 - groupBy
释义 根据RDD中的某个属性进行分组,分组后形式为(k, [(k, v1), (k, v2), ...]),即groupBy 后组内元素会保留key值 方法签名如下: def groupBy[K](f ...
- 从零开始, 开发一个 Web Office 套件 (3): 鼠标事件
这是一个系列博客, 最终目的是要做一个基于HTML Canvas 的, 类似于微软 Office 的 Web Office 套件, 包括: 文档, 表格, 幻灯片... 等等. 对应的Github r ...
- Spring IOC-基于注解配置的容器
Spring中提供了基于注解来配置bean的容器,即AnnotationConfigApplicationContext 1. 开始 先看看在Spring家族中,AnnotationConfigApp ...
- Java在算法题中的输入问题
Java在算法题中的输入问题 在写算法题的时候,经常因为数据的输入问题而导致卡壳,其中最常见的就是数据输入无法结束. 1.给定范围,确定输入几个数据 直接使用普通的Scanner输入数据范围,然后使用 ...
- Acwing_蓝桥_递归
一.关于由数据范围反推算法复杂度及其算法 关于输入输出:问题规模小于105:cin,scanf都差不多,但是要是大于105推荐使用scanf和printf. 二.关于递归 1.定义 自己调用自己 2. ...