python 链表、堆、栈
简介
很多开发在开发中并没有过多的关注数据结构,当然我也是,因此,我写这篇文章就是想要带大家了解一下这些分别是什么东西。
链表
概念:数据随机存储,并且通过指针表示数据之间的逻辑关系的存储结构。
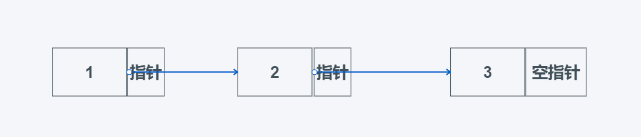
链表由两个部分组成
- 数据域:存放数据的地方
- 指针域:存放指针的地方

需要注意的是,链表无序数据顺序存储,可以随机存储,例如下面:
链表的特性
- 添加和删除元素速度快
添加
如下需要将4添加到1-2中间:
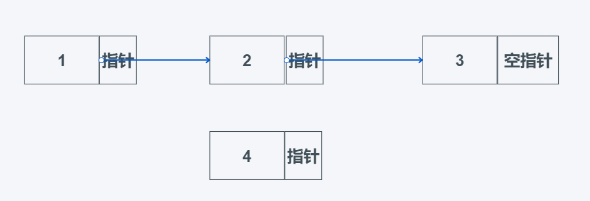
只需要将1的指针指向4的数据域,再将4的指针指向2的数据域即可。详细如下:
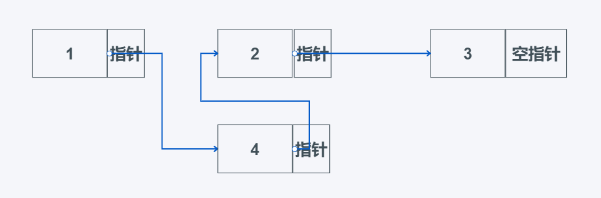
删除
还是上述的链表图,需要将2删除,只需将1的指针指向3的数据域,详细如下:
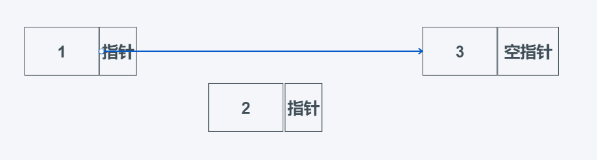
- 查找速度慢
因为是元素一个接着一个,因此查找前面的元素还好,但是如果是最后一个元素的话,则需要遍历整个链表。
栈(stack)
栈是很多数据的集合,支持一端添加或者删除元素的线性表或者说是容器,与此很相似的现实中的常见便是放置盘子时从下往上一个螺着一个放,但是拿盘子时需要从上往下依次去拿,这也就是栈的一个特性先进后出,也可以说是后进先出。
在性能上,当需要对栈的靠前面的元素进行操作是,性能较差,因为需要操作从后到所需元素的所有元素移动,比较适合直接在末尾进行操作。
python的内置栈
其实python内置的列表和栈有着相似之处,例如只能从一端(右端)进行数据的增删;因此列表适合在末尾进行操作,否则性能会稍差,需要移动元素。
列表是基于动态数组创建的,当列表中进行元素的增删时,会创建新的内存空间,将元素迁移``复制过去,然后销毁原有的内存空间,较为耗时。
动态数组
优点:支持随机存取,时间复杂度为O(1)
缺点:虽然动态数组克服了静态数组容量固定的缺点,可以进行扩容,但是扩容的过程要拷贝整个数组,效率不高。另外在头部插入和删除元素需要移动大量的元素,时间复杂度为O(n).
python的双向队列(栈)
collections.deque是python内置的双向队列,可以选择从两边进行操作,由于其基于双向链表实现,因此他的添加、删除性能出色,复杂度为o(1);但访问元素的性能就显得差了些,尤其是查找靠中间的元素,复杂度为o(n)。
from collections import deque
from typing import Iterable
d = deque(maxlen=5)
for i in range(4):
d.append(i)
d.appendleft(5)
print(d)
print(isinstance(d, Iterable))
d.append(10)
print(d)
d.pop()
d.popleft()
print(d)
deque([5, 0, 1, 2, 3], maxlen=5)
True
deque([0, 1, 2, 3, 10], maxlen=5)
deque([1, 2, 3], maxlen=5)
由上述结果可知,deque返回的对象是可迭代对象,并且当设置了最大长度时,添加元素时超过最大长度时会将前面的元素给移除。
堆
由百度百科可知,堆是一种特殊的数据结构,是最高效的优先级队列,可以看作是一个完全二叉树的数据对象。
那么什么是完全二叉树呢?
- 一棵深度为k且有2k次方 - 1 个结点的二叉树称为满二叉树。
- 根据二叉树的性质2, 满二叉树每一层的结点个数都达到了最大值, 即满二叉树的第i层上有 个结点 (i≥1) 。
- 如果对满二叉树的结点进行编号, 约定编号从根结点起, 自上而下, 自左而右。则深度为k的, 有n个结点的二叉树, 当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时, 称之为完全二叉树。
- 从满二叉树和完全二叉树的定义可以看出, 满二叉树是完全二叉树的特殊形态, 即如果一棵二叉树是满二叉树, 则它必定是完全二叉树。
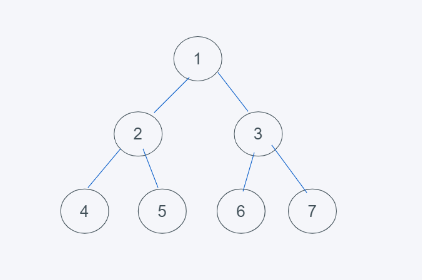
如下是满二叉树
如下则是完全二叉树
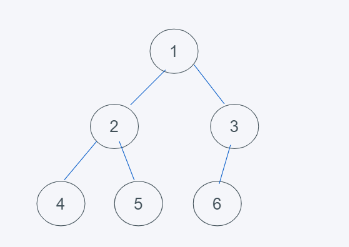
由此可以总结出,完全二叉树的概念,当一个深度为k的二叉树,自上而下,自左向右依次都有对应的元素,且不需要子节点数完全满子节点,只需要保证自上而下、自左向右均存在子节点即可。
堆的特性
- 堆中某个结点的值总是不小于其父结点的值;
- 堆总是一棵完全二叉树。
堆的特性判断
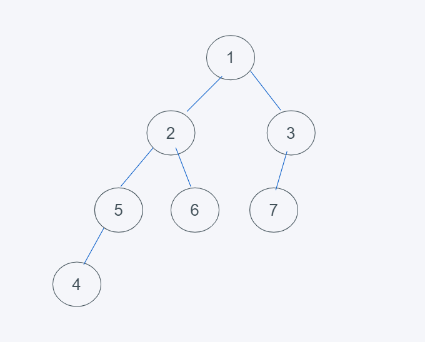
如下有几个堆,判断是否是堆?
如下图,不是堆,因为它不满足完全二叉树并且子节点元素存在不一致
如下图,不是堆,虽然是完全二叉树,但是不满足根节点元素均小于子节点元素
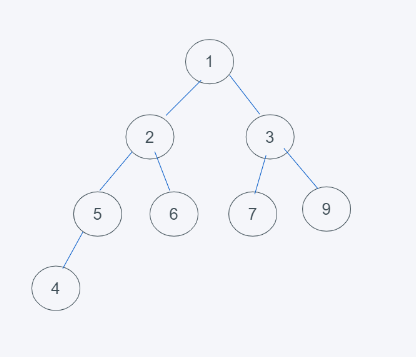
如下图,不是堆,既不是完全二叉树,也不满足根节点元素小于节点元素
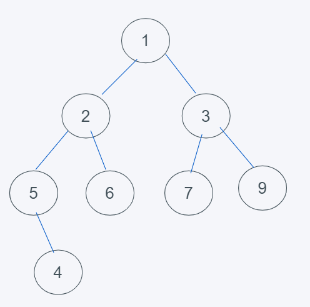
如下图,不是堆,是完全二叉树,但不满足根节点元素小于节点元素
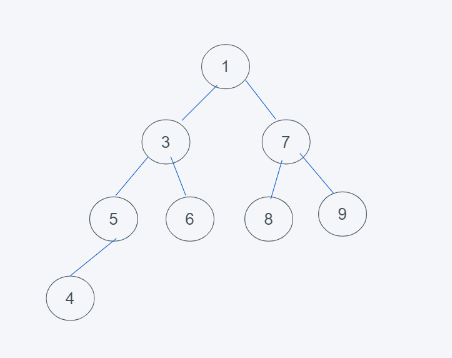
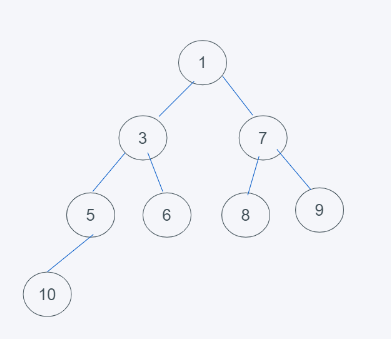
如下图,满足完全二叉树和根节点小于节点元素要求
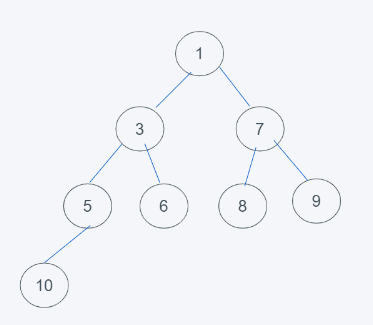
总结,需要是堆的话,需要是完全二叉树,并且根节点与子节点之间的关系必须满足大于等于或者小于等于。
大顶堆
当一个堆,根节点的值均大于两个子节点的值,则称此堆为最大堆,如下:
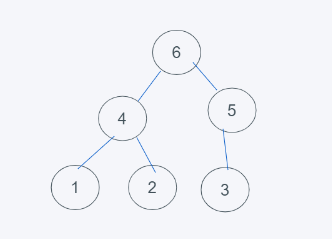
由于根节点都大于子节点,因此最上层的根节点将是最大值。
小顶堆
当一个堆,根节点均小于两个子节点的值,则称此堆为最小堆,如下:
由于根节点都小于子节点,因此最上层的根节点将是最小值。
堆的元素的表示
此处以如下堆为示例,表示方法为从上到下、从左到右,此处的表示为[6, 4, 5, 1, 2, 3]
堆中元素的添加与删除
添加元素
如图,需要将4添加至堆中:
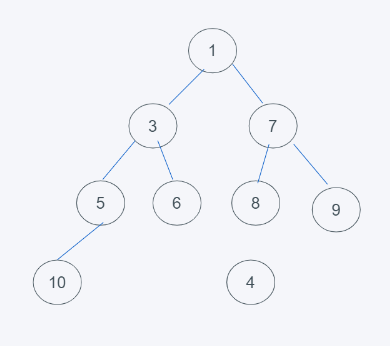
1.首先将4添加至堆的末尾
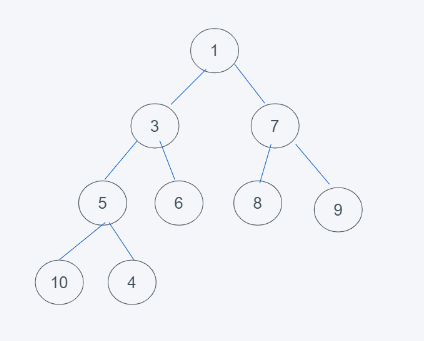
2.由于本堆是子节点元素都大于根节点元素,因此4不大于5,将4与5进行调换,如下
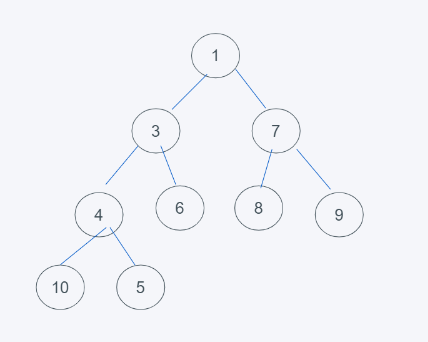
3.由此可见,5大于4并且4大于3,插入完毕,以此类推。
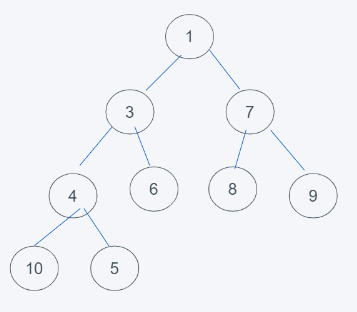
步骤总结就是,依据完全二叉树的定义插入到末尾,依据堆的整体特性进行大小比较位置调换即可。
删除元素
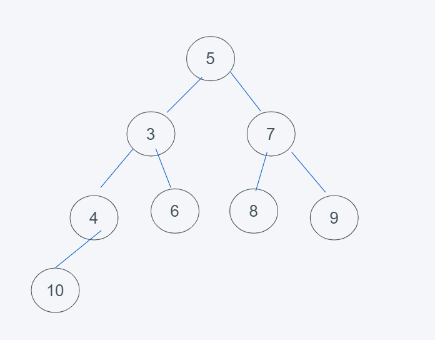
此处以上述插入元素后的堆为例,删除一般删除的都是堆顶元素,那就是1.
1.当堆顶元素删除后,使用末尾元素顶替,就是5.
2.由于堆是根节点小于子节点,因此5与3进行调换
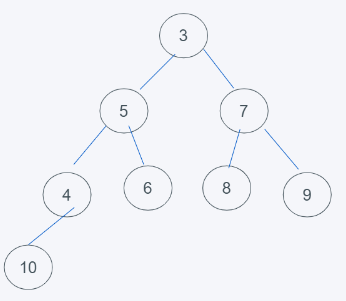
3.调换完成后,发现符合堆的要求了,删除结束。
总结,删除一般都是堆顶元素,删除完成后一般使用末尾元素进行替代,然后依据堆的性质进行调换即可。
python的堆
参考
python 链表、堆、栈的更多相关文章
- 图解堆算法、链表、栈与队列(Mark)
原文地址: 图解堆算法.链表.栈与队列(多图预警) 堆(heap),是一类特殊的数据结构的统称.它通常被看作一棵树的数组对象.在队列中,调度程序反复提取队列中的第一个作业并运行,因为实际情况中某些时间 ...
- [Python] 数据结构--实现顺序表、链表、栈和队列
说明: 本文主要展示Python实现的几种常用数据结构:顺序表.链表.栈和队列. 附有实现代码. 来源主要参考网络文章. 一.顺序表 1.顺序表的结构 一个顺序表的完整信息包括两部分,一部分是表中元素 ...
- 用python 实现一个栈
前言 Python本身已有顺序表(List.Tupple)的实现,所以这里从栈开始. 什么是栈 想象一摞被堆起来的书,这就是栈.这堆书的特点是,最后被堆进去的书,永远在最上面.从这堆书里面取一本书出来 ...
- python基本数据结构栈stack和队列queue
1,栈,后进先出,多用于反转 Python里面实现栈,就是把list包装成一个类,再添加一些方法作为栈的基本操作. 栈的实现: class Stack(object): #初始化栈为空列表 def _ ...
- 堆”,"栈","堆栈","队列"以及它们的区别
如果你学过数据结构,就一定会遇到“堆”,"栈","堆栈","队列",而最关键的是这些到底是什么意思?最关键的是即使你去面试,这些都还会问到, ...
- 数据结构 1 线性表详解 链表、 栈 、 队列 结合JAVA 详解
前言 其实在学习数据结构之前,我也是从来都没了解过这门课,但是随着工作的慢慢深入,之前学习的东西实在是不够用,并且太皮毛了.太浅,只是懂得一些浅层的,我知道这个东西怎么用,但是要优化.或者是解析,就不 ...
- Java数据结构——用链表实现栈
//================================================= // File Name : LinkStack_demo //---------------- ...
- 线性表 及Java实现 顺序表、链表、栈、队列
数据结构与算法是程序设计的两大基础,大型的IT企业面试时也会出数据结构和算法的题目, 它可以说明你是否有良好的逻辑思维,如果你具备良好的逻辑思维,即使技术存在某些缺陷,面试公司也会认为你很有培养价值, ...
- Java用链表实现栈和队列
1.用链表实现栈 package stack; /** * * @author denghb * */ class Link { public long dData; public Link next ...
随机推荐
- kNN-准备数据
在上一小节,我们大概了解了kNN算法的基本原理,现在我们要进行数据的处理 本小节所用数据集来自[机器学习实战]:Machine Learning in Action (manning.com) 下载数 ...
- 『现学现忘』Git基础 — 26、给Git命令设置别名
目录 1.什么是Git命令的别名 2.别名的全局配置 3.别名的局部配置 4.删除所有别名 5.小练习 1.什么是Git命令的别名 Git中命令很多,有些命令比较长,有些命令也不好记,也容易写错. 例 ...
- 一起看 I/O | Flutter 3 正式发布!
作者 / Tim Sneath, Google Flutter 和 Dart 产品组产品经理 Flutter 3 实现了 Flutter 以移动端为中心扩展到多平台的产品规划,并在今年 I/O 大会的 ...
- Jenkins安装详解
一.Jenkins是什么 Jenkins是一个独立的开源自动化服务器,可用于自动执行与构建,测试,交付或者部署软件相关的各种任务,是跨平台持续集成和持续交付应用程序,提高工作效率.使用Jenkins不 ...
- 【多线程】线程创建方式三:实现callable接口
线程创建方式三:实现callable接口 代码示例: import org.apache.commons.io.FileUtils; import java.io.File; import java. ...
- Nginx基本配置与应用
一.准备 1.1 环境准备 CentOS7软件环境 1.2 tomcat多实例 把/etc/profile.d/tomcat.sh中的变量注释了 #export TOMCAT_HOME=/usr/lo ...
- Golang可重入锁的实现
Golang可重入锁的实现 项目中遇到了可重入锁的需求和实现,具体记录下. 什么是可重入锁 我们平时说的分布式锁,一般指的是在不同服务器上的多个线程中,只有一个线程能抢到一个锁,从而执行一个任务.而我 ...
- 一起看 I/O | Flutter 3 更新详解
作者 / Kevin Jamaul Chisholm, Technical Program Manager for Dart and Flutter at Google 又到了 Flutter 稳定版 ...
- django框架11
内容概要 用户登录之后跳转到用户登录之前想要访问的页面 django操作cookie补充 django操作session django操作session补充 CBV添加装饰器 django中间件 自定 ...
- ForEach遍历集合、 集合容器
ForEach遍历集合 foreach循环是一种更加简洁的for循环,也称增强for循环,能用于遍历数组或集合中的元素. 格式: for(容器元素类型 临时变量:容器变量){ 执行语句} 从上面格式可 ...