一类(One-Class)分类器
本文摘自博客和论文,参考文献请看文末。
一类分类技术概念
与传统的分类技术不同,一类分类技术仅采用隶属于一个类别的样本来训练分类器,其通常被用于某种极端场景,即训练样本仅包含正常样本,而异常样本不可得的情况。该技术也已被用于解决极度不平衡分类问题,因为在此类问题上,传统的类不平衡学习方法通常不能取得较好的分类效果。
目前,最为常用的一类分类器包括基于高斯概率密度估计的方法、基于Parzen窗的方法、自编码器法、基于聚类的方法、基于K近邻的方法、一类支持向量机、支持向量数据描述法及一类极限学习机等。无论哪种方法,都是用于刻画一个覆盖关系,从而更好地描述正常样本的分布,使之与异常样本区分开来。
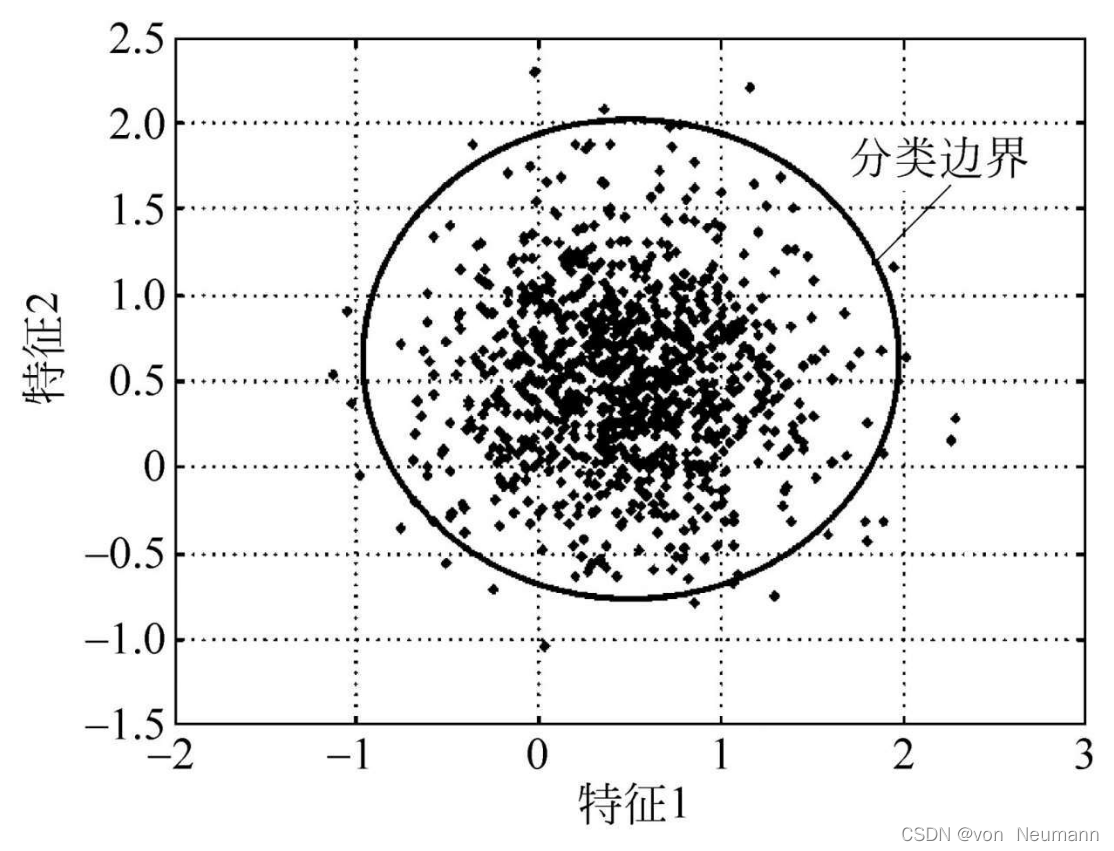
下图给出了一个一类分类器的示意图。从该图中不难看出,训练样本均属于同一类,一类分类技术就要找到一个覆盖模型来区分该类样本与未出现的异常样本。特别需要指出的是,为了保证分类器的泛化性能,可以允许一定比例的离群样本被误分。
应用领域
由于单类分类器的优良特性, 这些模型已经广泛应用于文本分类、入侵检测、手写体识别、图像处理等领域.单类分类器一般可以用于解决如下类别样本数目不平衡问题:
(1) 比如两个训练类别中的样本数目比例高至9∶1, 如医学图像等异常样本数据极少的情况.
(2) 异常类样本获取代价较高的问题:比如某些卫星网络故障诊断, 要获取故障样本所付出的代价太高, 不可能为了获取故障样本而特意让卫星系统出现故障.
(3) 异常类样本数目几乎无穷问题:比如入侵检测中攻击数量和种类层出不穷, 而且有的攻击产生变种, 根本就不清楚该拿哪些攻击样本来训练入侵检测器.
单类分类方法同样可以用于野值与新颖值的检测.在这种场合, 野值与新颖值被看作成异常类数据[31].由于单类分类器只训练正常类的训练数据, 因此在解决方法上不同于传统的两类 (或者多类) 分类问题.在单类分类问题的错误率监测上, 存在着两个标准:正常类错误率与异常类错误率.这两个错误率是相关的, 正常类错误率高的往往导致异常类错误率低, 反之亦然.因此, 在最后评价一个单类分类器的性能, 应从这两个方面综合考虑.
单类分类器由于只需要一类数据作为训练样本, 减化了数据预处理的时间, 在卫星通信系统和大型网络管理系统的故障诊断和入侵检测中都有着极大的应用前景.
参考资料
深入理解机器学习——类别不平衡学习(Imbalanced Learning):常用技术概览
潘志松,陈斌,缪志敏,倪桂强.One-Class分类器研究[J].电子学报,2009,37(11):2496-2503.
一类(One-Class)分类器的更多相关文章
- 深度学习与计算机视觉系列(3)_线性SVM与SoftMax分类器
作者: 寒小阳 &&龙心尘 时间:2015年11月. 出处: http://blog.csdn.net/han_xiaoyang/article/details/49949535 ht ...
- Spark ML源码分析之三 分类器
前面跟大家扯了这么多废话,终于到具体的机器学习模型了.大部分机器学习的教程,总要从监督学习开始讲起,而监督学习的众多算法当中,又以分类算法最为基础,原因在于分类问题非常的单纯直接,几乎 ...
- libsvm java 调用说明
libsvm是著名的SVM开源组件,目前有JAVA.C/C++,.NET 等多个版本,本人使用的是2.9libsvm命名空间下主要使用类:svm_model 为模型类,通过训练或加载训练好的模型文件获 ...
- 【论文笔记】Zero-shot Recognition via semantic embeddings and knowledege graphs
Zero-shot Recognition via semantic embeddings and knowledege graphs 2018-03-31 15:38:39 [Abstrac ...
- RCNN 目标识别基本原理
RCNN- 将CNN引入目标检测的开山之作 from:https://zhuanlan.zhihu.com/p/23006190 前面一直在写传统机器学习.从本篇开始写一写 深度学习的内容. 可能需要 ...
- logistic 回归与线性回归的比较
可以参考如下文章 https://blog.csdn.net/sinat_37965706/article/details/69204397 第一节中说了,logistic 回归和线性回归的区别是:线 ...
- 逻辑斯蒂(logistic)回归深入理解、阐述与实现
第一节中说了,logistic 回归和线性回归的区别是:线性回归是根据样本X各个维度的Xi的线性叠加(线性叠加的权重系数wi就是模型的参数)来得到预测值的Y,然后最小化所有的样本预测值Y与真实值y'的 ...
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤:1.分类,识别物体是什么 2.定位,找出物体在哪里 除了对单个物体进行检测,还要能支持 ...
- 机器学习经典算法之SVM
SVM 的英文叫 Support Vector Machine,中文名为支持向量机.它是常见的一种分类方法,在机器学习中,SVM 是有监督的学习模型. 什么是有监督的学习模型呢?它指的是我们需要事先对 ...
- RCNN,Fast RCNN,Faster RCNN 的前生今世:(2)R-CNN
Region CNN(RCNN)可以说是利用深度学习进行目标检测的开山之作.作者Ross Girshick多次在PASCAL VOC的目标检测竞赛中折桂,2010年更带领团队获得终身成就奖,如今供职于 ...
随机推荐
- 齐博x1背景图如何设置标签
背景图非常特殊,由于不能点击,所以他不能直接添加标签,需要添加一个辅助标签,比如类似下面的代码 {qb:hy name="xxa001" type="image" ...
- Android掌控WiFi不完全指南
前言 如果想要对针对WiFi的攻击进行监测,就需要定期获取WiFi的运行状态,例如WiFi的SSID,WiFi强度,是否开放,加密方式等信息,在Android中通过WiFiManager来实现 WiF ...
- Java:既然有了synchronized,为什么还要提供Lock?
摘要:在Java中提供了synchronized关键字来保证只有一个线程能够访问同步代码块.既然已经提供了synchronized关键字,那为何在Java的SDK包中,还会提供Lock接口呢?这是不是 ...
- Pycharm自定义实时模板
pycharm添加模板 添加装饰器模板 # 1.file-->Setting-->Editor-->Code Style -->Live Templates# 2." ...
- Vue2基础知识学习
Vue2基础知识学习 01.初识 new Vue({ el: '#root', //用于指定当前Vue实例为哪个容器服务,值通常为css选择器符 data () { return { } } }); ...
- 云实例初始化工具cloud-init源码分析
源码分析 代码结构 cloud-init的代码结构如下: cloud-init ├── bash_completion # bash自动补全文件 │ └── cloud-init ├── Chan ...
- C#结构体大小问题
using System; using System.Collections.Generic; using System.Linq; using System.Runtime.InteropServi ...
- 在 Solidity 中 ++i 为什么比 i++ 更省 Gas?
前言 作为一个初学者,"在 Solidity 中 ++i 为什么比 i++ 更省 Gas?" 这个问题始终在每个寂静的深夜困扰着我.也曾在网上搜索过相关问题,但没有得到根本性的解答 ...
- npm卸载"Tracker idealTree already exists"
问题 使用npm卸载babel插件的时候执行命令npm uninstall babel...出现如下报错 npm ERR! Tracker "idealTree" already ...
- 自动增加 Android App 的版本号
一般的 C# 应用程序中都有一个 AssemblyInfo.cs 文件,其中的 AssemblyVersion attribute 就可以用来设置该应用程序的版本号.譬如, [assembly: As ...