Python爬取网页上想要的数据
1、源代码如下
from urllib.request import urlopen,Request
import urllib.request
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall url ='http://movie.douban.com/top250?format=text'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'}
ret = Request(url,headers=headers)
page = urllib.request.urlopen(ret)
contents = page.read()
# print(contents)
soup = BeautifulSoup(contents, "html.parser")
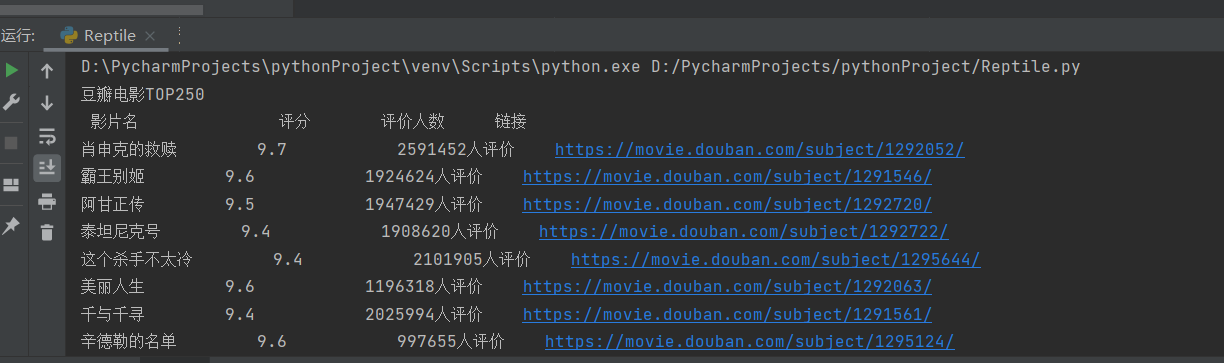
print("豆瓣电影TOP250" + "\n" + " 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span', class_='rating_num').get_text())
m_people = tag.find('div', class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url = tag.find('a').get('href')
print(m_name + " " + str(m_rating_score) + " " + m_peoplecount + " " + m_url)
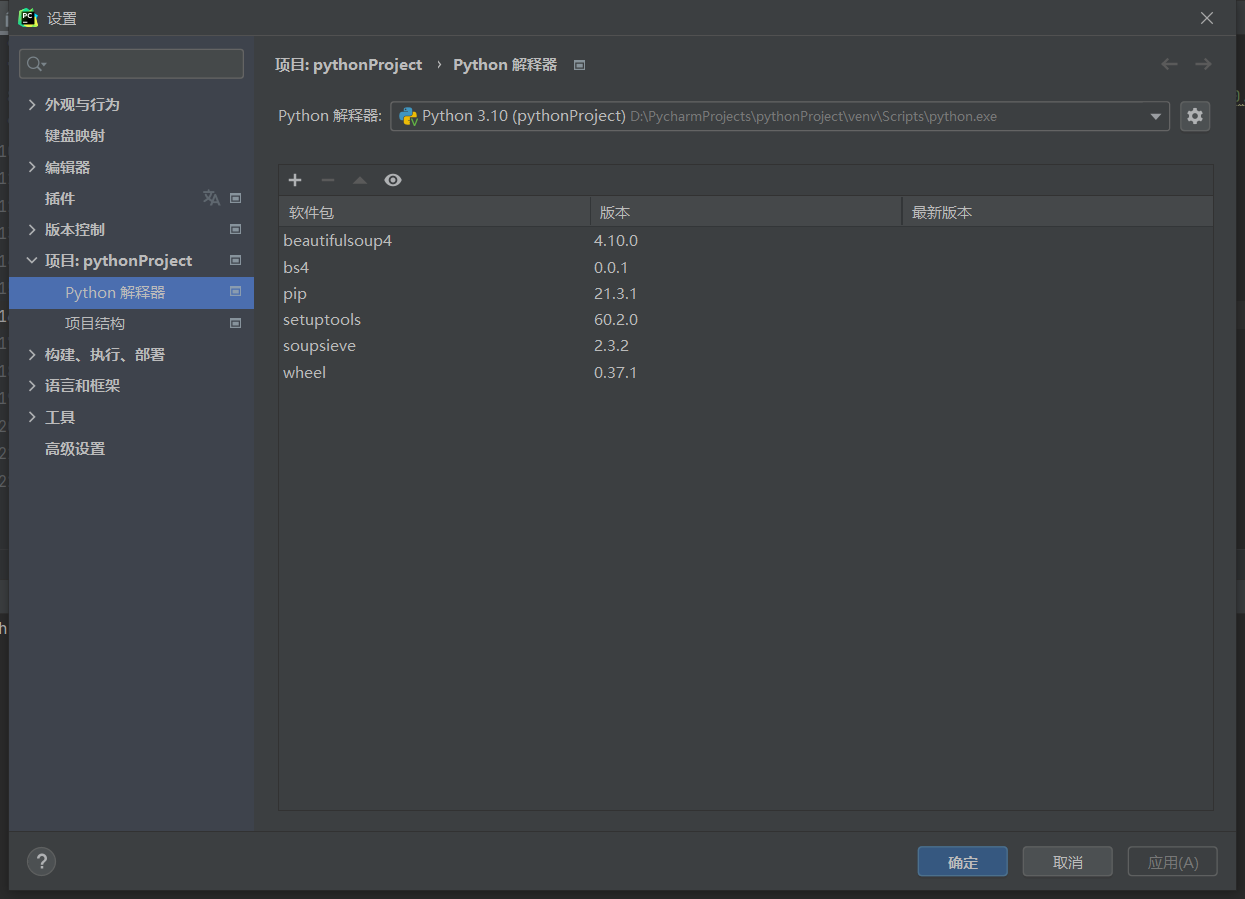
2、安装bs4
在文件-设置-python Project-搜索ps4并点击安装,安装完成以后会提示安装成功
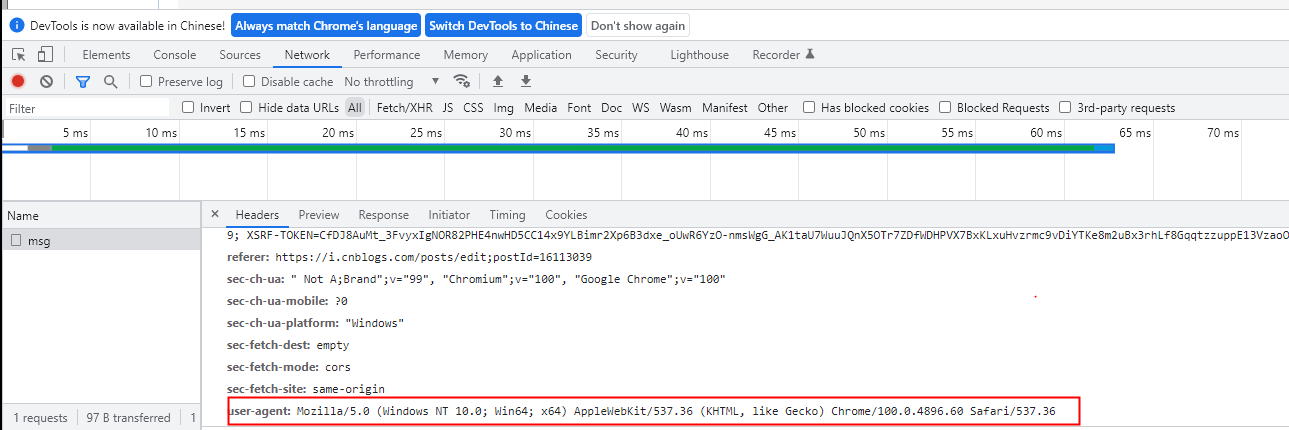
3、URLLIB.ERROR.HTTPERROR: HTTP ERROR 418错误
需要模拟浏览器访问,直接爬取会被拦截。打开浏览器按F12,随便访问一个网站,选中连接,找Headers,往下拉找到其中user-agent代表用的哪个请求的浏览器。
Python爬取网页上想要的数据的更多相关文章
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 如何使用python爬取网页动态数据
我们在使用python爬取网页数据的时候,会遇到页面的数据是通过js脚本动态加载的情况,这时候我们就得模拟接口请求信息,根据接口返回结果来获取我们想要的数据. 以某电影网站为例:我们要获取到电影名称以 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
随机推荐
- dapr本地托管的服务调用体验与Java SDK的Spring Boot整合
1 简介 之前在文章<dapr入门与本地托管模式尝试>中介绍了dapr和本地托管,本文我们来介绍如果在代码中使用dapr的服务调用功能,并把它整合到Spring Boot中. Dapr服务 ...
- ReentrantLock介绍及源码解析
ReentrantLock介绍及源码解析 一.ReentrantLock介绍 ReentrantLock是JUC包下的一个并发工具类,可以通过他显示的加锁(lock)和释放锁(unlock)来实现线程 ...
- TCP与UDP、socket模块
1.传输层之TCP与UDP协议 1.TCP协议 1.传输控制协议(也称为TCP协议或可靠协议)是为了在不可靠的互联网络上提供可靠的端到端字节流而专门设计的一个传输协议,(数据不容易丢失);造成数据不容 ...
- 不用Blazor WebAssembly,开发在浏览器端编译和运行C#代码的网站
本文中,我将会为大家分享一个如何用.NET技术开发"在浏览器端编译和运行C#代码的工具",核心的技术就是用C#编写不依赖于Blazor框架的WebAssembly以及Roslyn技 ...
- docker05-dockerfile
1.dockerfile是什么 Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本.可以理解为docker自己的语言编写的脚本. 2.Dockerfile内容基础 ...
- 2.3.pages.json文件的页面配置与全局配置
新建页面 # pages uni-app 通过 pages 节点配置应用由哪些页面组成,pages 节点接收一个数组,数组每个项都是一个对象,其属性值如下: 属性 类型 默认值 描述 path Str ...
- Kinsoku jikou desu新浪股票接口变动
1.问题原因 新浪股票接口返回如标题所示值:Kinsoku jikou desu! http://hq.sinajs.cn/list=code 新浪股票的接口变动,需要在请求头中添加Referer值. ...
- JZOJ 100149. 一道联赛A题
\(\text{Solution}\) 一眼 \(ODT\) 为避免每次都数颜色数量,提前记录下来,每次修改更新下 \(\text{Code}\) #include <cstdio> #i ...
- JZOJ 3527.迷宫花坛(garden)
题面 思路 考场想到 \(tarjan\) 缩点 然而忘了缩点怎么打 于是甩了个暴力 改题时学了个圆方树 发现挺好用 于是······注意重边 \(Code\) #include<cstdio& ...
- CF1372D Omkar and Circle
题目传送门 思路 这是一道非常简单的 \(\mathcal *2100\). 既然他样例给的那么简单,说明这是一道结论题. 于是我们可以手玩几组数据试试. 例如 \(3,5,9,8,12\) 这组,发 ...