Python爬取网页上想要的数据
1、源代码如下
from urllib.request import urlopen,Request
import urllib.request
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall url ='http://movie.douban.com/top250?format=text'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'}
ret = Request(url,headers=headers)
page = urllib.request.urlopen(ret)
contents = page.read()
# print(contents)
soup = BeautifulSoup(contents, "html.parser")
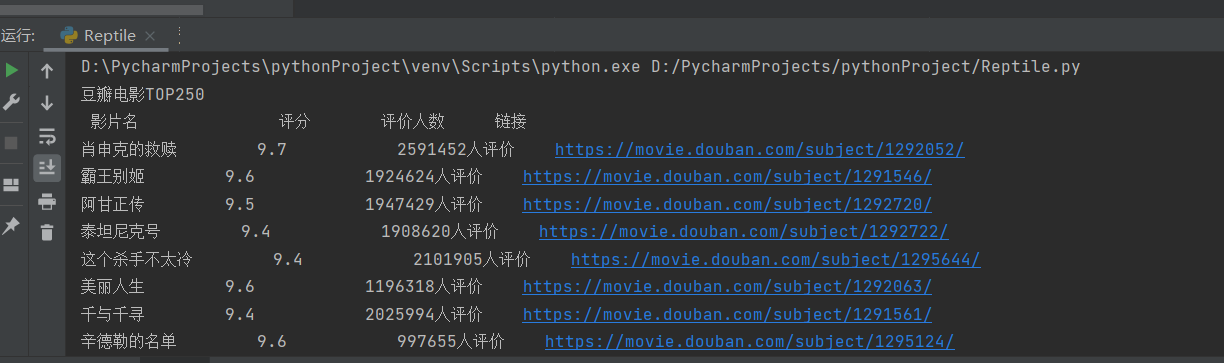
print("豆瓣电影TOP250" + "\n" + " 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span', class_='rating_num').get_text())
m_people = tag.find('div', class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url = tag.find('a').get('href')
print(m_name + " " + str(m_rating_score) + " " + m_peoplecount + " " + m_url)
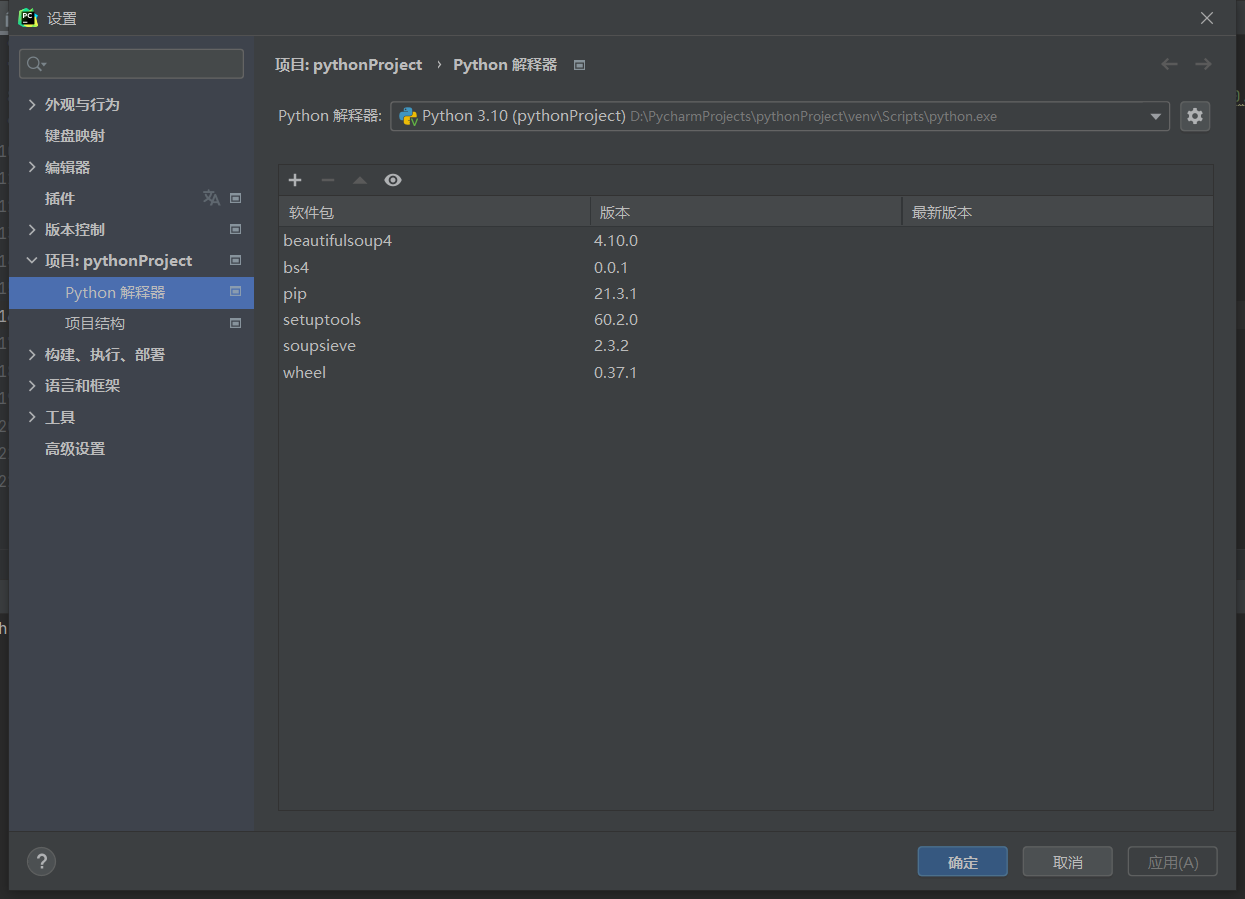
2、安装bs4
在文件-设置-python Project-搜索ps4并点击安装,安装完成以后会提示安装成功
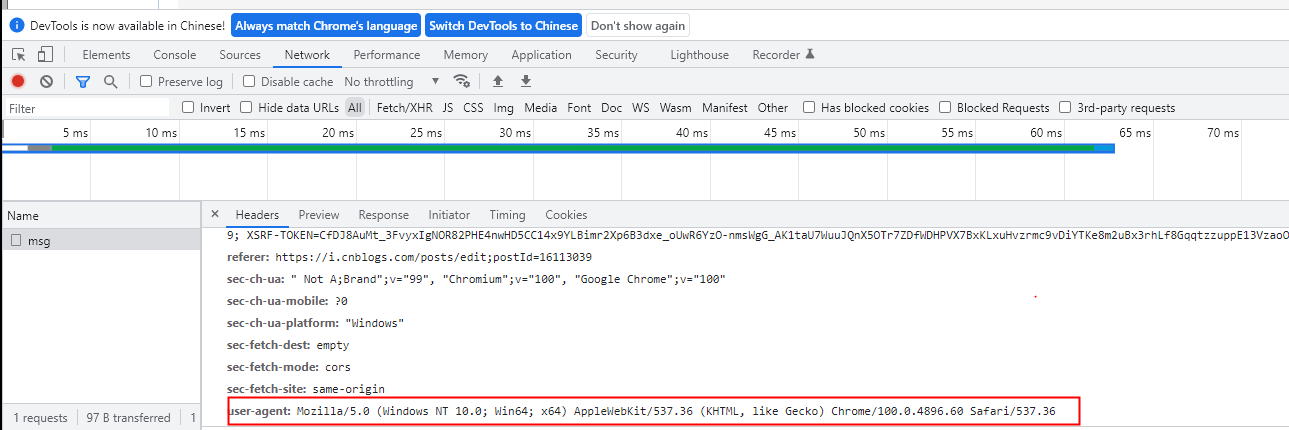
3、URLLIB.ERROR.HTTPERROR: HTTP ERROR 418错误
需要模拟浏览器访问,直接爬取会被拦截。打开浏览器按F12,随便访问一个网站,选中连接,找Headers,往下拉找到其中user-agent代表用的哪个请求的浏览器。
Python爬取网页上想要的数据的更多相关文章
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 如何使用python爬取网页动态数据
我们在使用python爬取网页数据的时候,会遇到页面的数据是通过js脚本动态加载的情况,这时候我们就得模拟接口请求信息,根据接口返回结果来获取我们想要的数据. 以某电影网站为例:我们要获取到电影名称以 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
随机推荐
- GraalVM和Spring Native尝鲜,一步步让Springboot启动飞起来,66ms完成启动
简介 GraalVM是高性能的JDK,支持Java/Python/JavaScript等语言.它可以让Java变成二进制文件来执行,让程序在任何地方运行更快.这或许是Java与Go的一场战争? 下载安 ...
- 字符编码和字符集-FileReader读取jbk格式的文件
字符编码和字符集 字符编码 计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字.英文.标点符号.汉字等字符是二进制数转换之后的结果.按照某种规则,将字符存储到计算机中,称为编码.反之,将 ...
- 【分析笔记】全志平台 gpio-keys 驱动应用和 stack crash 解决
内核配置 内核版本:Linux version 4.9.56 make ARCH=arm64 menuconfig Device Drivers ---> Input device suppor ...
- Python标准库pathlib及实例操作
Python标准库pathlib及实例操作 https://docs.python.org/zh-cn/3.9/library/pathlib.html 官网 讲的比较好的文章 https://zhu ...
- Grafana 系列文章(十四):Helm 安装Loki
前言 写或者翻译这么多篇 Loki 相关的文章了, 发现还没写怎么安装 现在开始介绍如何使用 Helm 安装 Loki. 前提 有 Helm, 并且添加 Grafana 的官方源: helm repo ...
- mysql17-sql优化-慢查询日志
1.什么是慢查询日志MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,会被记录到慢查询日 ...
- 关于异常处理的return
无论try代码块中是否有异常,finally里的代码都会执行 当try和catch代码块中有return语句时,finally仍然会执行 如果try-catch-finally都有return语句,则 ...
- vim之YouCompleteMe插件问题:The ycmd server SHUT DOWN (restart with ...low the instructions in the documen
cd ~/.vim/plugged/YouCompleteMe 然后运行./install.py 1.因为我是单独下载的Youcompleteme,所以要将整个文件夹拷贝到上述目录下,再运行
- 30道四则运算java
package test4; import java.util.Scanner;import java.util.Random;public class Test4 { public static v ...
- vant ui rem配置流程
参考地址 https://www.cnblogs.com/WQLong/p/7798822.html 1.下载lib-flexible 使用的是vue-cli+webpack,通过npm来安装的 n ...