logback.xml详解
介绍
之前博文有专门介绍过基于Log4j Appender 实现大数据平台组件日志的采集, 本篇主要对java项目中经常会接触到的logback.xml文件的配置做一个介绍和总结.
logback.xml 配置
下面是一个logback配置demo, 常用的配置都有, 一一介绍下每个配置的作用.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="d:/opt/module/logs" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.bigdata.logger.LoggerExample"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" additivity="false">
<appender-ref ref="console" />
</root>
</configuration>
配置说明:
property
定义属性,类似全局变量, 比如上面我们定义的LOG_HOME 日志写入路径文件路径, 下面的appender 可以直接引用appender
追加器,描述如何写入到文件中(写在哪,格式,文件的切分)
ConsoleAppender--追加到控制台
RollingFileAppender--滚动追加到文件
encoder: 对日志进行格式化。
rollingPolicy:当发生滚动时,决定RollingFileAppender的行为,涉及文件移动和重命名.TimeBasedRollingPolicy 是根据时间制定滚动策略,
fileNamePattern:文件输出格式logger
控制器,描述如何选择追加器
注意:要是单独为某个类指定的时候,要修改类的全限定名
appender-ref: 引用前面定义的appender
level="error": 定义输出的日志级别, 低于此日志级别的日志不会输出
additivity="false": 这个稍微不太好理解, 下面我写个代码, 实操下.日志级别
TRACE->DEBUG ->INFO -> WARN -> ERROR -> FATAL
从左到右, 由到高root
根级别日志
实战code
项目结构:
maven 配置:
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.6</version>
</dependency>
</dependencies>
测试代码:
public class LoggerExample {
private static final Logger logger = LoggerFactory.getLogger(LoggerExample.class);
public static void main(String[] args) {
logger.info("Example log from {}", LoggerExample.class.getSimpleName());
logger.error("Error log");
}
}
直接运行的结果:
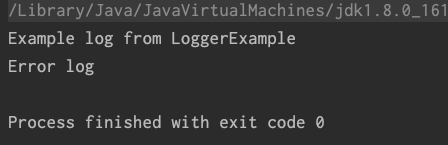
console和app.log文件的结果一样
修改 additivity="true
<logger name="com.bigdata.logger.LoggerExample" level="INFO" additivity="true">
再次运行结果:
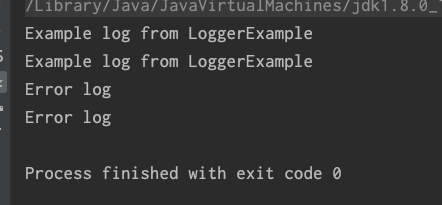
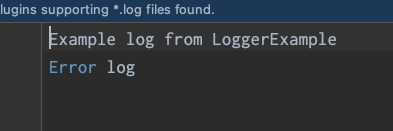
可以看出app.log正常, 但是cosole 上打印了重复的日志, 说明命中了console appender两次, log和root 各一次, 但是奇怪的是, 第一条info日志为什么会重复, 因为root level="ERROR", 理论上info 日志级别比ERROR级别要低, 不应该在console里出现才对.
我们看下logback相关的源码是如何处理的.
/**
* Invoke all the appenders of this logger.
*
* @param event The event to log
*/
public void callAppenders(ILoggingEvent event) {
int writes = 0;
for (Logger l = this; l != null; l = l.parent) {
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
从代码我们可以看出, logback 的整个输出是从logger子节点开始往上遍历, 如果additive = false, 就直接break 循环直接结束, 如果break = true, 会继续往上寻找父节点,直到最终 l == null. 同时会记录writes, writes == 0,认为没有定义appender输出源
代码没有关于日志级别的控制. 所以以后如果只希望打印日志到子节点的appeder, 父节点的appender忽略, 就设置additivity = false, 默认值为true, 这样日志就不会重复了.
总结
主要对logback.xml 常用配置的作用介绍, 通过logback 的相关源码对additivity参数有了更深的认识. additivity 默认值为true, 如果不希望在某些场景下打印重复的日志, 可以设置为false, additivity 配置不受level配置的影响.
logback.xml详解的更多相关文章
- logback的使用和logback.xml详解,在Spring项目中使用log打印日志
logback的使用和logback.xml详解 一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分 ...
- 转载 logback的使用和logback.xml详解 http://www.cnblogs.com/warking/p/5710303.html
logback的使用和logback.xml详解 一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前 ...
- Logback简介及配置文件logback.xml详解
logback简介及配置文件说明 @author:wangyq @date:2021年3月31日 logback简介 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: htt ...
- logback的使用和logback.xml详解
一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两 ...
- (网页)logback的使用和logback.xml详解(转)
转自博客园:行走在云端的愚公: 一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分为下面下个模块: ...
- logback的使用和logback.xml详解[转]
一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两 ...
- java日志 -logback的使用和logback.xml详解(转)
一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两 ...
- logback配置文件---logback.xml详解
一.参考文档 1.官方文档 http://logback.qos.ch/documentation.html 2.博客文档 http://www.cnblogs.com/warking/p/57103 ...
- 转:logback的使用和logback.xml详解
一.logback的介绍 Logback是由log4j创始人设计的另一个开源日志组件,官方网站: http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两 ...
随机推荐
- SQL及常见的三种类型注释
SQL(Structure Query Language)语言是数据库的核心语言. SQL的发展是从1974年开始的,其发展过程如下:1974年-----由Boyce和Chamberlin提出,当时称 ...
- 完整代码:安卓小软件“CSV联系人导入导出工具”
完整代码:安卓小软件"CSV联系人导入导出工具" 开发了一个安卓小软件"CSV联系人导入导出工具",欢迎测试.本软件可以帮你快速备份和恢复联系人,不用担心号码遗 ...
- 【面试题】纯css实现三角形,你知道如何实现吗?
纯css实现三角形 点击打开视频教程 <template> <div id="app"> <!-- 纯css实现三角形书写 --> <di ...
- Luogu5367 【模板】康托展开 (康拓展开)
\(n^2\)暴力 #include <iostream> #include <cstdio> #include <cstring> #include <al ...
- a 标签 rel 属性值 opener 的作用
<a> 元素,原英文单词为 anchor 的缩写,所以又称之为锚点元素.锚点元素的 href 属性用来创建通向其他网页.文件.同一页面内的位置.电子邮件地址或任何其他 URL 的超链接. ...
- 自动化选课(Python + selenium
前几天听到朋友说自己选课事情,突发奇想想要搞这样一个东西,但是由于各种原因只做到以下的完成度,具体的情况也会在解释的最后留下.这个只适用于曲师大的教务系统,因为用的这个系统来进行的一个调试,对于其 ...
- python九周周末总结
python九周周末总结 UDP协议 udp协议的交互模式服务端不需要考虑客户端是否退出,你发多少那么他就会按照你发的东西直接去传输给客户端不存在黏包现象 服务端: import socket ser ...
- node前后端交互(Express)
1. Express框架是什么 1.1 Express是一个基于Node平台的web应用开发框架,它提供了一系列的强大特性,帮助你创建各种Web应用.我们可以使用 npm install expres ...
- 手把手教你搭建JAVA分布式爬虫
在工作中,我们经常需要去获取一些数据,但是这些数据可能需要从第三方平台才可以获取到.这个时候,爬虫系统就可以帮助我们来完成这些事情. 提到爬虫系统,很多人都会想到使用python.但实际上,语言只是一 ...
- 存储更弹性,详解 Fluid “ECI 环境数据访问” 新功能
近期,Fluid 支持了阿里云 ECI 应用,并将 JuiceFS Runtime Controller 设置为默认安装:JuiceFS 也就此功能与 Fluid 完成了集成和测试工作. 用户可以在 ...