AdaBoost:自适应提升算法的原理及其实现
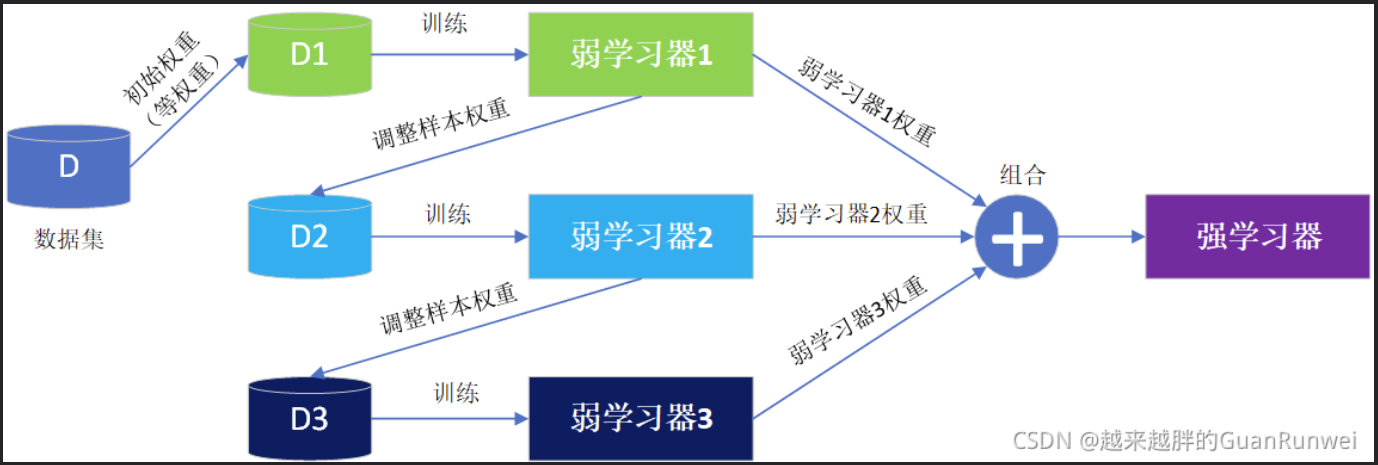
具体过程:
- 对原始数据集初始化权重
- 用带权值数据集训练弱学习器
- 根据弱学习器的误差计算弱学习器的权重
- 调整数据集的权重
- 重复第2-4步K-1次
- 将K-1个弱学习器的结果进行加权组合
对于AdaBoost的数学说明,请见Adaboost算法讲解 - 知乎 (zhihu.com)
代码实现:
首先导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
然后来制造一些假数据:
# 生成数据并查看
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs # 导入sklearn模拟二分类数据生成模块
X, y = make_blobs(n_samples=150, n_features=2, centers=2, cluster_std=1.2, random_state=40) # 生成模拟二分类数据集
# 将标签转换为1/-1
y_ = y.copy()
y_[y_==0] = -1
y_ = y_.astype(float)
X_train, X_test, y_train, y_test = train_test_split(X, y_, test_size=0.3, random_state=43) # 训练/测试数据集划分
colors = {0:'r', 1:'g'} # 设置颜色参数
plt.scatter(X[:,0], X[:,1], marker='o', c=pd.Series(y).map(colors)) # 绘制二分类数据集的散点图
plt.show();
创建一个决策弱分类器的函数:
class DecisionStump():
def __init__(self):
# 基于划分阈值决定样本分类为1还是-1
self.label = 1
# 特征索引
self.feature_index = None
# 特征划分阈值
self.threshold = None
# 指示分类准确率的值
self.alpha = None
定义整体model:
### 定义AdaBoost算法类
class Adaboost:
# 弱分类器个数
def __init__(self, n_estimators=5):
self.n_estimators = n_estimators # Adaboost拟合算法
def fit(self, X, y):
m, n = X.shape
# (1) 初始化权重分布为均匀分布 1/N
w = np.full(m, (1/m))
# 处初始化基分类器列表
self.estimators = []
for _ in range(self.n_estimators):
# (2.a) 训练一个弱分类器:决策树桩
estimator = DecisionStump()
# 设定一个最小化误差
min_error = float('inf')
# 遍历数据集特征,根据最小分类误差率选择最优划分特征
for i in range(n):
# 获取特征值
values = np.expand_dims(X[:, i], axis=1)
# 特征取值去重
unique_values = np.unique(values)
# 尝试将每一个特征值作为分类阈值
for threshold in unique_values:
p = 1
# 初始化所有预测值为1
pred = np.ones(np.shape(y))
# 小于分类阈值的预测值为-1
pred[X[:, i] < threshold] = -1
# 2.b 计算误差率
error = sum(w[y != pred]) # 如果分类误差大于0.5,则进行正负预测翻转
# 例如 error = 0.6 => (1 - error) = 0.4
if error > 0.5:
error = 1 - error
p = -1 # 一旦获得最小误差则保存相关参数配置
if error < min_error:
estimator.label = p
estimator.threshold = threshold
estimator.feature_index = i
min_error = error # 2.c 计算基分类器的权重
estimator.alpha = 0.5 * np.log((1.0 - min_error) / (min_error + 1e-9))
# 初始化所有预测值为1
preds = np.ones(np.shape(y))
# 获取所有小于阈值的负类索引
negative_idx = (estimator.label * X[:, estimator.feature_index] < estimator.label * estimator.threshold)
# 将负类设为 '-1'
preds[negative_idx] = -1
# 2.d 更新样本权重
w *= np.exp(-estimator.alpha * y * preds)
w /= np.sum(w) # 保存该弱分类器
self.estimators.append(estimator) # 定义预测函数
def predict(self, X):
m = len(X)
y_pred = np.zeros((m, 1))
# 计算每个弱分类器的预测值
for estimator in self.estimators:
# 初始化所有预测值为1
predictions = np.ones(np.shape(y_pred))
# 获取所有小于阈值的负类索引
negative_idx = (estimator.label * X[:, estimator.feature_index] < estimator.label * estimator.threshold)
# 将负类设为 '-1'
predictions[negative_idx] = -1
# 2.e 对每个弱分类器的预测结果进行加权
y_pred += estimator.alpha * predictions # 返回最终预测结果
y_pred = np.sign(y_pred).flatten()
return y_pred
最后,让我们借助sklearn中的准确率函数来测试一下:
##### 计算准确率
from sklearn.metrics import accuracy_score # 导入sklearn准确率计算函数
clf = Adaboost(n_estimators=5) # 创建Adaboost模型实例
clf.fit(X_train, y_train) # 模型拟合
y_pred = clf.predict(X_test) # 模型预测
accuracy = accuracy_score(y_test, y_pred) # 计算模型预测准确率
print("Accuracy of AdaBoost by numpy:", accuracy)
AdaBoost:自适应提升算法的原理及其实现的更多相关文章
- 【机器学习算法】AdaBoost自适应提升算法
前言 AdaBoost的算法步骤比较容易理解,可以参考李航老师的<统计学习方法>和July的blog. 对博主而言,最主要的是迭代部分的第二步骤是如何如何确定阈值呢,也就是说有一个特征就有 ...
- Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在"强可学习"和"弱科学习"的概念上来说就是我们通过对多个弱可学习的算法进行"组合 ...
- [机器学习]-Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在”强可学习”和”弱可学习”的概念上来说就是我们通过对多个弱可学习的算法进行”组合提升或者说是强化”得到一个性能赶超强可学习算法的算 ...
- 机器学习之Adaboost (自适应增强)算法
注:本篇博文是根据其他优秀博文编写的,我只是对其改变了知识的排序,另外代码是<机器学习实战>中的.转载请标明出处及参考资料. 1 Adaboost 算法实现过程 1.1 什么是 Adabo ...
- Adaboost 算法的原理与推导——转载及修改完善
<Adaboost算法的原理与推导>一文为他人所写,原文链接: http://blog.csdn.net/v_july_v/article/details/40718799 另外此文大部分 ...
- [转]Adaboost 算法的原理与推导
看了很多篇解释关于Adaboost的博文,觉得这篇写得很好,因此转载来自己的博客中,以便学习和查阅. 原文地址:<Adaboost 算法的原理与推导>,主要内容可分为三块,Adaboost ...
- 机器学习第5周--炼数成金-----决策树,组合提升算法,bagging和adaboost,随机森林。
决策树decision tree 什么是决策树输入:学习集输出:分类觃则(决策树) 决策树算法概述 70年代后期至80年代初期,Quinlan开发了ID3算法(迭代的二分器)Quinlan改迚了ID3 ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
随机推荐
- 论文解读(soft-mask GNN)《Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks》
论文信息 论文标题:Soft-mask: Adaptive Substructure Extractions for Graph Neural Networks论文作者:Mingqi Yang, Ya ...
- ebook下载 | 《 企业高管IT战略指南——企业为何要落地DevOps》
"当下,企业DevOps转型不仅是IT部门的事情,更是企业高管必须关注的焦点.DevOps是一项需要自上而下推动的变革运动,只有从顶层实施,才能获得成功.本书将介绍企业高管必须了解的,Dev ...
- LuoguP3690 【模板】Link Cut Tree (LCT)
勉强算是结了个大坑吧或者才开始 #include <cstdio> #include <iostream> #include <cstring> #include ...
- 重看Java教学视频时的查漏补缺
数据类型 1.基本数据类型:四类八种. 2.数据范围与字节数不一定相关.如float为4字节表示范围比long的8字节要大. 3.浮点数默认double类型,如要用float,需加F. 4.boole ...
- docker compose搭建redis7.0.4高可用一主二从三哨兵集群并整合SpringBoot【图文完整版】
一.前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群. redis有两种高可用的方案: High availability with Re ...
- UI自动化框架搭建之Python3
UI自动化框架搭建--unittest 使用的代码是Python3版本,与时俱进哈哈 解释一下我的框架目录接口(每个人框架的目录接口不一样,根据实际要求) common目录:公共模块,这个地方可以存放 ...
- Spring源码-Bean生命周期总览
- UVA1306 The K-League(最大流)
题面 有 n n n 支队伍进行比赛,每支队伍需要打的比赛数目相同. 每场比赛恰好一支队伍胜,另一支败. 给出每支队伍目前胜的场数 w i w_i wi 和败的场数(没用),以及每两个队伍还剩下的比 ...
- Math_Music
查看代码 #REmoo的优化任务 #1.公式写在<formula_set>类中,统一管理 --- Finished 2022.8.15 12:39 #2.建立<sample_set& ...
- 【java】学习路线15-接口interface、匿名内部类、接口继承
class Learn03{ public static void main(String[] aa){ A b = new B(); //接口也可以用多态 b.me ...