CVPR2022 Oral OGM-GE阅读笔记
标题:Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR 2022 Oral)
论文:https://arxiv.org/abs/2203.15332
领域:多模态学习
解决本质问题
在某些多模态模型的训练过程中,性能更好的模态(主导模态)会对其他模态的优化产生抑制作用,因此导致的模态间训练的不平衡现象,单一模态存在欠优化。
方法
文章主要从不同模态的梯度传播上入手,根据模态间的效果差异自适应地调制梯度,并结合高斯噪声的泛化性增强能力,提出了具有较强适用性的OGM-GE优化方法。
优点
- 即插即用,很通用直观的工作
- 实验详实,各项实验指标表明该方法的灵活有效性,应用在不同的encoder、fusion method以及优化器中都有一定提升,并且相比其他调节策略提升优势显著
缺点
- 模态间的融合方式不仅只有论文中所详细阐述的concat方式,融合的阶段也不一定要在各自模态的encoder提完特征后,在某些任务中,不同模态的地位是不相同的,分清主次模态也是一个方法,因此本文的做法有一定局限性。
- 本文动态调节梯度中的动态系数\(k_t\)的设置方法是比较handmade的,模态差异率\(\rho_t^u\)的定义符合intuition但也缺乏一定的数学解释证明,仅仅只是实验表明比较work。
- 为了弥补因为动态减少强势模态梯度所造成的泛化性减小问题而再引入高斯噪声(GN)的方式感觉不够elegant,既然这样为啥不直接增强弱势模态梯度,加强随机梯度噪声,甚至不需要添加GN?
进一步思考
如果是我,我该如何解决这个问题?这也是我一直以来在试着培养的科研思维,当然,idea is cheap,以下思路都尚待实验证明~
method1:gradient decent
如上述缺点中提到的,既然可以减少强势模态梯度,同时增加GN,相反的,也可以尝试增强弱势模态梯度,加强随机梯度噪声,甚至不需要添加GN。
method2:multi task learning
为啥会想到这个,因为我觉得思想差不多!只不过多模态是multiple in,而多任务是multiple out。
首先多任务学习可以通过不同子任务的互相约束,可以使网络减少归纳偏置、帮助收敛、提取共性特征来取得更好的性能,但是loss权重人为设定相当困难,为什么不让网络自己学习?
一种可行的方式
参考论文:Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics (CVPR 2018)
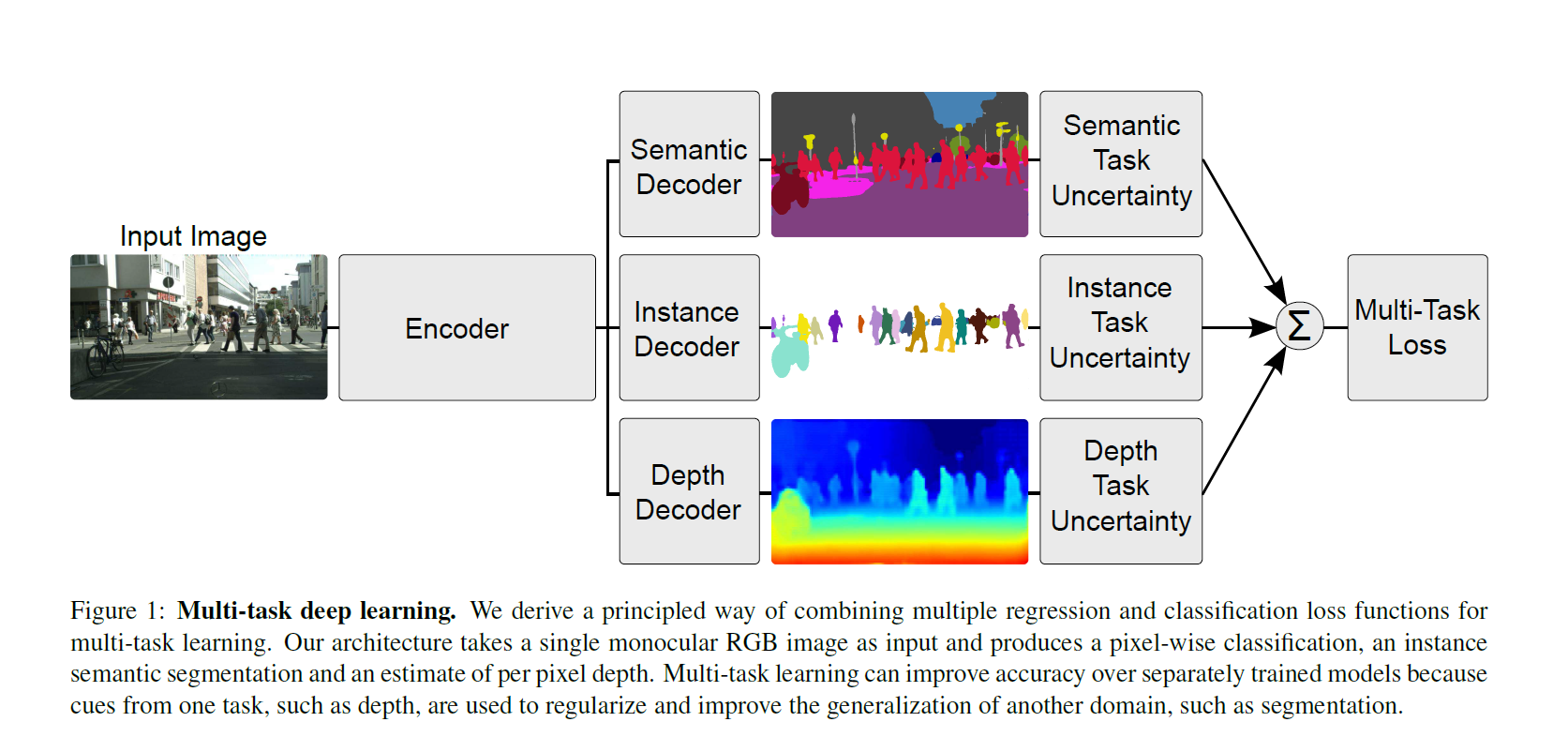
本文通过建立贝叶斯模型,基于同方差不确定性建立了多任务的联合loss如下
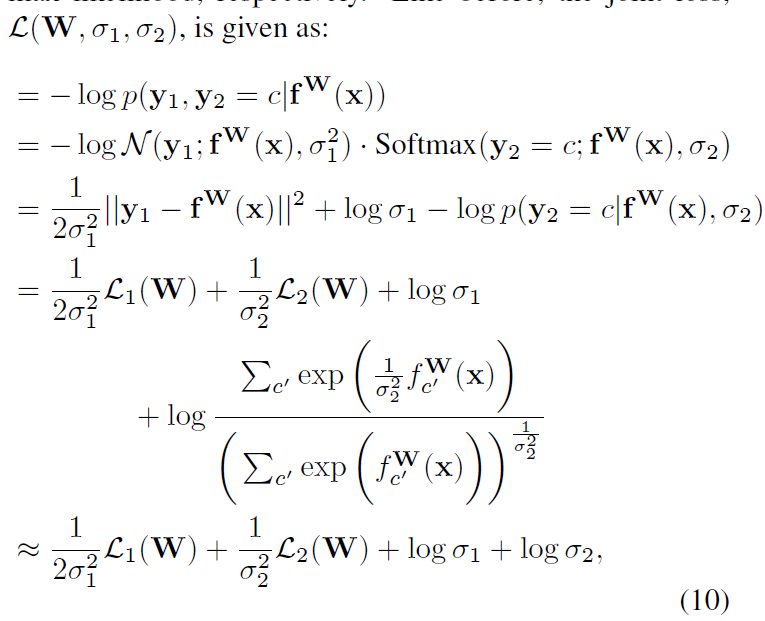
对于更多任务的模型,根据任务类型也很容易拓展,网络将自动学习权重~
本任务中的应用流程
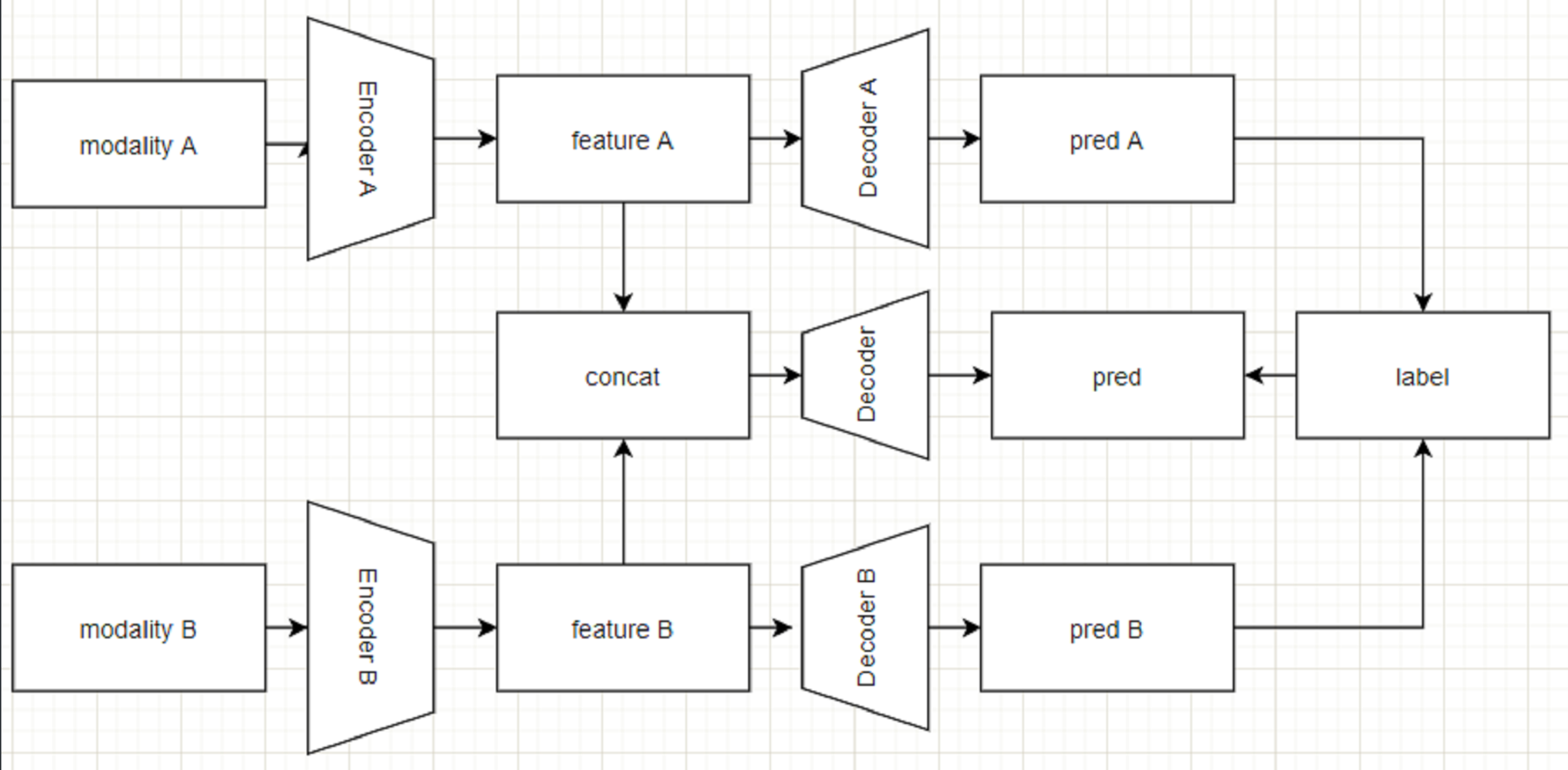
通过多任务加强整体任务性能,相对应的提升弱势模态优化效果。
method3:knowledge distill
由于强弱模态之间,存在学习和优化上的差异,可以类比老师和学生,一个学的好,一个学的不好,因此考虑知识蒸馏~
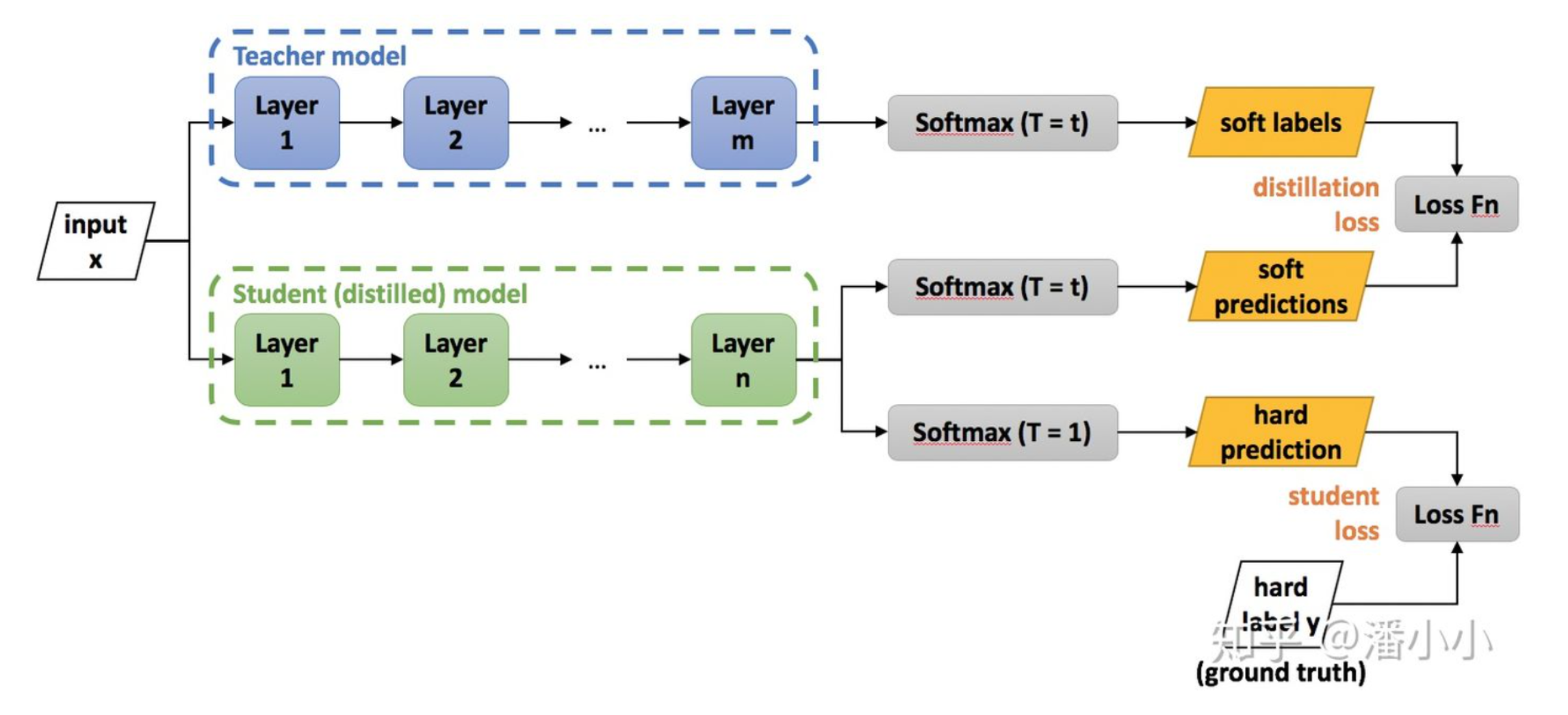
KD整体架构如下:
参考论文:Distilling the Knowledge in a Neural Network
一种可行的方式
参考论文:There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge (CVPR 2021)
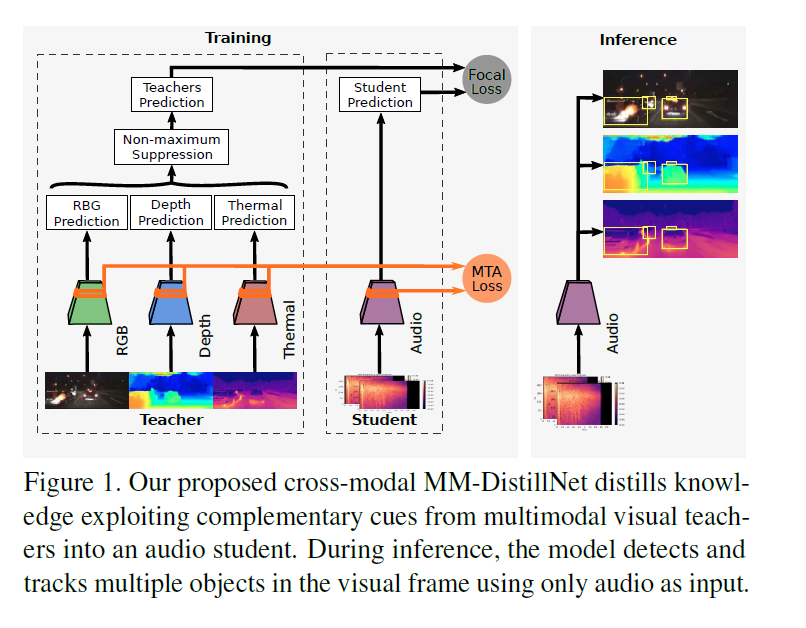
让teacher net(含有RGB、Depth、Themal多个模态)训练student net(Audio)然后让student net单独实现定位,MTA损失来对齐学生的中间表示与教师的中间表示。
本任务中的应用流程
- gt教强模态train一个teacher net
- 强模态教弱模态, 使用强模态的输出概率值而不是onehot向量对弱模态进行训练,train student net
- 一般知识蒸馏的做法是单独用student去预测的,但这里可以进行模态fusion实现共同预测。
解决的问题本质都是模态不均衡,但思路不同,这个方法侧重于使弱模态从本质上变强。
该方法可能存在的问题:模态差异性太大,无法对齐导致效果不好。。。
method4:self-supervised learning
原先的动态系数\(k_t\)只对encoder部分进行动态调节,来使得弱势模态优化得到提升,这种方法是有点后天培养的意思,那么为啥不能直接就让encoder先天就比较厉害呢?这样我不怎么需要优化就perform well了~于是就想到了利用自监督,自监督是目前比较火的方向,通过在上游任务中先进行预训练然后应用到下游任务中往往效果比较好。
一种可行的方式
参考论文::Unsupervised learning of visual representations by solving jigsaw puzzles(ECCV 2016)

为了恢复原始的小块,Noroozi等人提出了一个称为上下文无关网络(CFN)的神经网络,如下图所示。在这里,各个小块通过相同的共享权值的siamese卷积层传递。然后,将这些特征组合在一个全连接的层中。在输出中,模型必须预测在64个可能的排列类别中使用了哪个排列,如果我们知道排列的方式,我们就能解决这个难题。
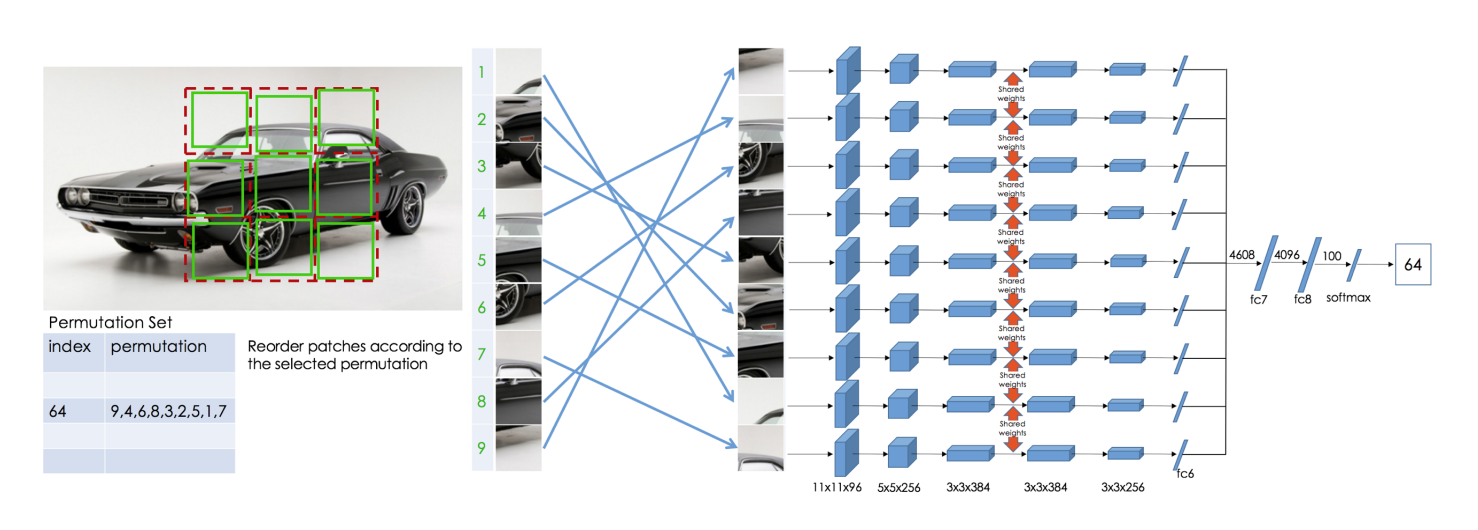
为了解决拼图问题,模型需要学习识别零件是如何在一个物体中组装的,物体不同部分的相对位置和物体的形状。因此,这些表示对于下游的分类和检测任务是有用的。
本任务中的应用流程
- 自监督预训练好各自模态的encoderA和encoderB
- 按OGM-GE实验进行的架构进行Fine-tune
method5:bilnearl pooling
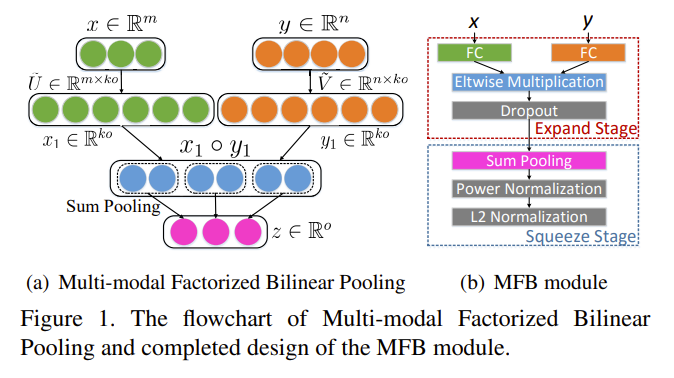
OGM-GE架构中存在的另一个问题是concat的方式模态之间融合还不够充分,哪怕实验中所展示的其他fusion方式也是比较的简单的,算是一阶融合,这样就导致互相之间不同模态特征之间融合太少,学习不够充分,也可能间接导致弱势模态学的不够好,因此可以改变融合策略考虑用二阶融合,比如二阶双线性池化
由于二阶双线性池化存在维度过高,计算量过大的问题,后续的很多work都对它进行降维处理,比较的典型的就是表征能力较强的MFB方法,由于本人对于vqa领域了解不深,故不在此展开。
CVPR2022 Oral OGM-GE阅读笔记的更多相关文章
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- [阅读笔记]Software optimization resources
http://www.agner.org/optimize/#manuals 阅读笔记Optimizing software in C++ 7. The efficiency of differe ...
- 《uml大战需求分析》阅读笔记05
<uml大战需求分析>阅读笔记05 这次我主要阅读了这本书的第九十章,通过看这章的知识了解了不少的知识开发某系统的重要前提是:这个系统有谁在用?这些人通过这个系统能做什么事? 一般搞清楚这 ...
- <<UML大战需求分析>>阅读笔记(2)
<<UML大战需求分析>>阅读笔记(2)> 此次读了uml大战需求分析的第三四章,我发现这本书讲的特别的好,由于这学期正在学习设计模式这本书,这本书就讲究对uml图的利用 ...
- uml大战需求分析阅读笔记01
<<UML大战需求分析>>阅读笔记(1) 刚读了uml大战需求分析的第一二章,读了这些内容之后,令我深有感触.以前学习uml这门课的时候,并没有好好学,那时我认为这门课并没有什 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
随机推荐
- Matplotlib(基本用法)
Matplotlib 是数据分析绘图的常见模块,可以算是 2D-绘图(Python)领域使用最广泛的套件,可以将数据图形化,并且提供多样化的输出格式,利于数据的显示并分析. 接下来展示的是Matplo ...
- Spark: Cluster Computing with Working Sets
本文是对spark作者早期论文<Spark: Cluster Computing with Working Sets>做的翻译(谷歌翻译),文章比较理论,阅读起来稍微有些吃力,但读完之后总 ...
- 10. 选主算法、多版本兼容性及滚动升级 | 深入浅出MGR
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 目录 1. 选主算法 2. 多版本兼容性 3. MGR 5.7滚动升级至8.0 4. 小结 参考资料.文档 免责声明 文章 ...
- LuoguP1799 数列_NOI导刊2010提高 (动态规划)
$ f[j]=max(f[i−1][j],f[i−1][j−1]+(x == j) $ #include <iostream> #include <cstdio> #inclu ...
- 微信小程序创建组件的流程,以及组件 properties 和 slot
组件定义流程 1)为了方便管理组件文件,创建一个目录来存放组件(可省略该步骤) 组件与页面都有相同的配置,包括的文件有:wxml.wxss.js.json 四个文件. 2)编写组件 编写组件与编写页面 ...
- Jira使用浅谈篇一
本篇参考: https://www.jianshu.com/u/9dd427d9ad94 Salesforce 生命周期管理(二)Agile & Scrum 浅谈 我们都知道 salesfor ...
- dentry的引用计数不对导致的crash
[17528853.189372] python invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=-998[17528853.189 ...
- 2022CISCN-satool
2022CISCN-satool 打国赛的时候自己还并不了解LLVM PASS pwn,前几天正好学习了一下LLVM PASS pwn,于是就顺便来复现一下这道题目. 首先找到二进制文件的重写函数的主 ...
- 彻底搞懂C#异步编程 async和await的原理
1.前提 熟练掌握Task并行编程. 2.用Task并行解释async和await异步 因为控制台有多线程操作的优化,因此这里选择winform来做示例. 测试代码如下所示: 有三个textbox,一 ...
- Openstack Neutron:三层技术和实现
目录 - 1.Neutron 三层技术简介 - 2.集中式router - 1.在节点上安装L3 agent - 2.配置外部网络 - 3.通过CLI或者Horizon 来创建路由 - 4.连接租户网 ...