Oracle归档日志暴增排查优化
1、ORACLE归档日志介绍
- 归档日志暴增一般都是应用或者人为引起的
- 理解归档日志存储的是什么
- 如何排查归档日志暴增原因
- 如何优化归档日志暴增
1.1 归档日志是什么
归档日志(Archive Log)是非活动的重做日志(redo)备份.
通过使用归档日志,可以保留所有重做历史记录,当数据库处于ARCHIVELOG模式并进行日志切换式,后台进程ARCH会将重做日志的内容保存到归档日志中.
当数据库出现介质失败时,使用数据文件备份,归档日志和重做日志可以完全恢复数据库。
1.2 归档日志存储的是什么
所有重做的历史记录,包括DML语句、数据改变等
1.3 归档日志暴增的原因
一般是DML操作大量的数据,导致归档日志暴增
1.4 排查归档日志暴增的方法
1.SQL语句
2.AWR
3.挖掘归档日志
2、归档日志暴增排查实战
2.1 制造归档日志暴增
create table scott.object as select * from dba_objects; -- 执行10次
-- insert
insert into scott.object select * from scott.object;
select count(1) from scott.object;
-- 49384448 -- update
update SCOTT.object set owner='aa'; -- delete
delete from SCOTT.object;
truncate table SCOTT.object;
2.2 查看归档日志切换
SELECT
THREAD# id,SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) DAY
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'00',1,0)) H00
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'01',1,0)) H01
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'02',1,0)) H02
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'03',1,0)) H03
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'04',1,0)) H04
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'05',1,0)) H05
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'06',1,0)) H06
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'07',1,0)) H07
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'08',1,0)) H08
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'09',1,0)) H09
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'10',1,0)) H10
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'11',1,0)) H11
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'12',1,0)) H12
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'13',1,0)) H13
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'14',1,0)) H14
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'15',1,0)) H15
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'16',1,0)) H16
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'17',1,0)) H17
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'18',1,0)) H18
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'19',1,0)) H19
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'20',1,0)) H20
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'21',1,0)) H21
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'22',1,0)) H22
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'23',1,0)) H23
FROM
v$log_history a
GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5),THREAD#
ORDER BY id,SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5)
/
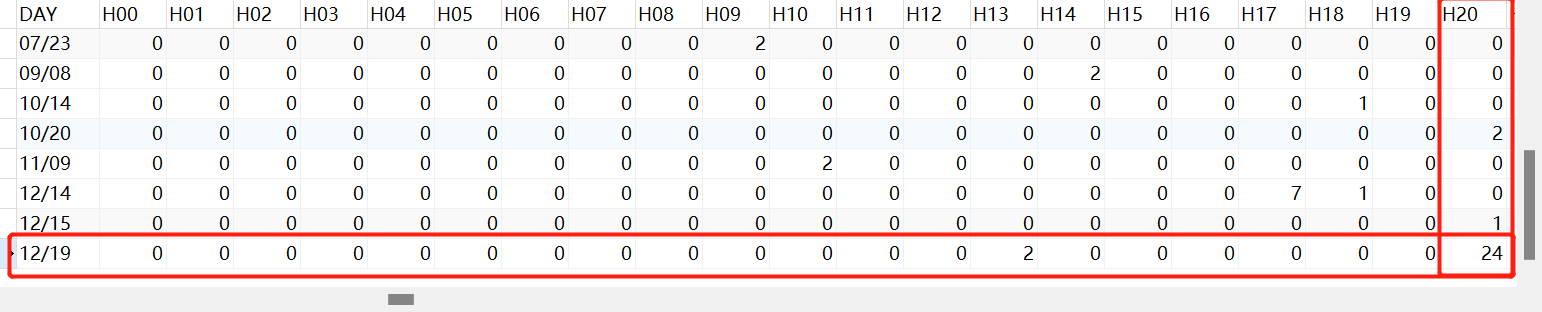
代表12月19号,H20(20-21时),共切换24个归档日志,如果每一个500M,那么总共约500M*24,对比其余时间,可以说该时间产生异常的归档日志,目标排查改时间段
2.3 SQL语句判断
with aa as
(SELECT IID,
USERNAME,
to_char(BEGIN_TIME,'mm/dd hh24:mi') begin_time,
SQL_ID,
decode(COMMAND_TYPE,3,'SELECT',2,'INSERT',6,'UPDATE',7,'DELETE',189,'MERGE INTO','OTH') "SQL_TYPE",
executions "EXEC_NUM",
rows_processed "Change_NUM"
FROM (SELECT s.INSTANCE_NUMBER IID,
PARSING_SCHEMA_NAME USERNAME,COMMAND_TYPE,
cast(BEGIN_INTERVAL_TIME as date) BEGIN_TIME,
s.SQL_ID,
executions_DELTA executions,
rows_processed_DELTA rows_processed,
(IOWAIT_DELTA) /
1000000 io_time,
100*ratio_to_report(rows_processed_DELTA) over(partition by s.INSTANCE_NUMBER, BEGIN_INTERVAL_TIME) RATIO,
sum(rows_processed_DELTA) over(partition by s.INSTANCE_NUMBER, BEGIN_INTERVAL_TIME) totetime,
elapsed_time_DELTA / 1000000 ETIME,
CPU_TIME_DELTA / 1000000 CPU_TIME,
(CLWAIT_DELTA+APWAIT_DELTA+CCWAIT_DELTA+PLSEXEC_TIME_DELTA+JAVEXEC_TIME_DELTA)/1000000 OTIME,
row_number() over(partition by s.INSTANCE_NUMBER,BEGIN_INTERVAL_TIME order by rows_processed_DELTA desc) TOP_D
FROM dba_hist_sqlstat s, dba_hist_snapshot sn,dba_hist_sqltext s2
where s.snap_id = sn.snap_id
and s.INSTANCE_NUMBER = sn.INSTANCE_NUMBER
and rows_processed_DELTA is not null
and s.sql_id = s2.sql_id and COMMAND_TYPE in (2,6,7,189)
and sn.BEGIN_INTERVAL_TIME > sysdate - nvl(180,1)/1440 and PARSING_SCHEMA_NAME<>'SYS')
WHERE TOP_D <= nvl(20,1)
)
select aa.*,s.sql_fulltext "FULL_SQL" from aa left join v$sql s on aa.sql_id=s.sql_id ORDER BY IID, BEGIN_TIME desc,"Change_NUM" desc
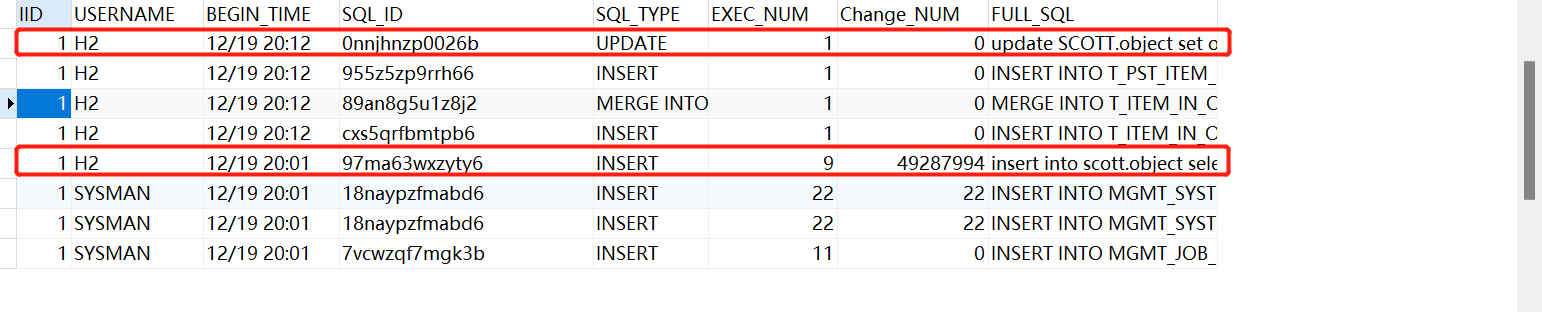
查看2小时的数据该变量,可以看出Change_NUM数据该变量和执行次数EXEC_NUM和SQL语句,update回滚了,所以没有该变量。
此时可以判断大量插入数据导致归档日志暴增,此时并不能判断update。此语句不一定有数据,只能做参考。
2.4 AWR
创建AWR报告
@?/rdbms/admin/awrrpt.sql
SQL> @?/rdbms/admin/awrrpt.sql Current Instance
~~~~~~~~~~~~~~~~ DB Id DB Name Inst Num Instance
----------- ------------ -------- ------------
3830097027 ..... 1 ..... Specify the Report Type
~~~~~~~~~~~~~~~~~~~~~~~
Would you like an HTML report, or a plain text report?
Enter 'html' for an HTML report, or 'text' for plain text
Defaults to 'html'
Enter value for report_type: html Type Specified: html Instances in this Workload Repository schema
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ DB Id Inst Num DB Name Instance Host
------------ -------- ------------ ------------ ------------
* 3830097027 1 ..... ..... dbserver01 Using 3830097027 for database Id
Using 1 for instance number Specify the number of days of snapshots to choose from
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Entering the number of days (n) will result in the most recent
(n) days of snapshots being listed. Pressing <return> without
specifying a number lists all completed snapshots. Enter value for num_days: 1 Listing the last day's Completed Snapshots Snap
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
..... ..... 36 19 Dec 2021 14:03 1
37 19 Dec 2021 15:00 1
38 19 Dec 2021 16:00 1
39 19 Dec 2021 17:00 1
40 19 Dec 2021 18:00 1 41 19 Dec 2021 20:12 1
42 19 Dec 2021 21:03 1 Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for begin_snap: 41
Begin Snapshot Id specified: 41 Enter value for end_snap: 42
End Snapshot Id specified: 42 Specify the Report Name
~~~~~~~~~~~~~~~~~~~~~~~
The default report file name is awrrpt_1_41_42.html. To use this name,
press <return> to continue, otherwise enter an alternative. Enter value for report_name: /tmp/awrrpt_1_41_42.html
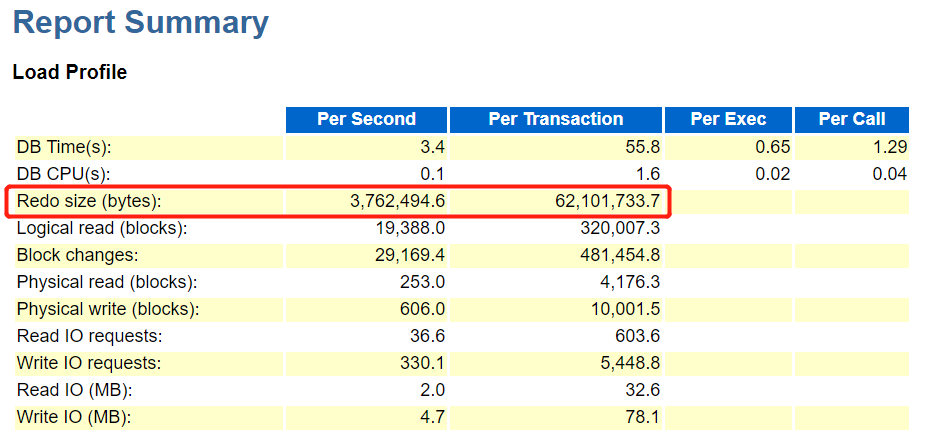
可以看出大量redo,该时间段总该变量3762494/1024/1024=3674,每秒约产生3.5M
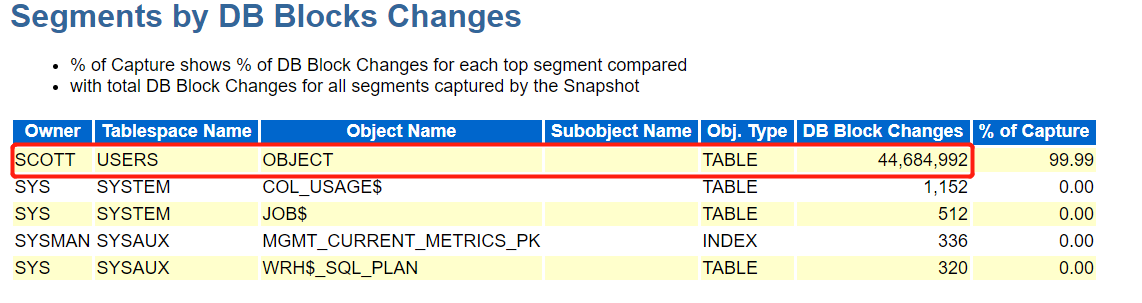
产生块最多的是scott用户,object对象,改变量是44684992,占比99%,说明是该对象产生的
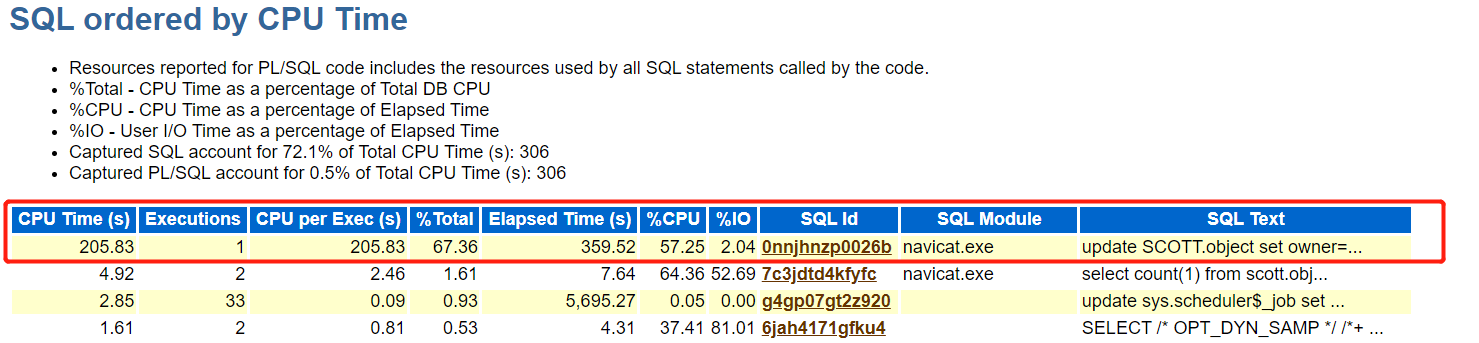
根据对象可以在AWR报告中查看是否有怀疑的SQL,发现update语句。
其实根据SQL语句和AWR报告可以排查出大部分归档日志暴增的问题,如果无法排查可以继续进行挖掘归档日志。
2.5 挖掘归档日志
-rw-r-----. 1 oracle oinstall 794697216 Dec 19 20:37 1_66_1077902149.dbf
-rw-r-----. 1 oracle oinstall 794697216 Dec 19 20:37 1_67_1077902149.dbf
-rw-r-----. 1 oracle oinstall 794697216 Dec 19 21:03 1_68_1077902149.dbf
-rw-r-----. 1 oracle oinstall 733794304 Dec 19 21:03 1_69_1077902149.dbf
-rw-r-----. 1 oracle oinstall 756531200 Dec 19 21:03 1_70_1077902149.dbf
-rw-r-----. 1 oracle oinstall 761492480 Dec 19 21:14 1_71_1077902149.dbf
-rw-r-----. 1 oracle oinstall 794697216 Dec 19 21:14 1_72_1077902149.dbf
-rw-r-----. 1 oracle oinstall 265107968 Dec 19 21:14 1_73_1077902149.dbf
-- 最好sys或相关权限的用户,也可以使用toad工具
-- 第一次
@?/rdbms/admin/dbmslm.sql
@?/rdbms/admin/dbmslmd.sql -- 开始执行
execute dbms_logmnr.add_logfile(logfilename=>'../../1_66_1077902149.dbf',options=>dbms_logmnr.new);
execute dbms_logmnr.add_logfile(logfilename=>'../../1_67_1077902149.dbf',options=>dbms_logmnr.new);
execute dbms_logmnr.add_logfile(logfilename=>'../../1_68_1077902149.dbf',options=>dbms_logmnr.new);
execute dbms_logmnr.add_logfile(logfilename=>'../../1_69_1077902149.dbf',options=>dbms_logmnr.new);
execute dbms_logmnr.add_logfile(logfilename=>'../../1_70_1077902149.dbf',options=>dbms_logmnr.new);
execute dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);
-- 依次类推小批量解析归档日志 -- 保存记录
create table scott.logmnr_contents as select * from v$logmnr_contents; -- 分批执行...循环执行上面记录
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'; -- 最后释放pga
execute dbms_logmnr.end_logmnr;
select sql_redo from scott.logmnr_contents where table_name='OBJECT';
select count(*) from scott.logmnr_contents where table_name='OBJECT';
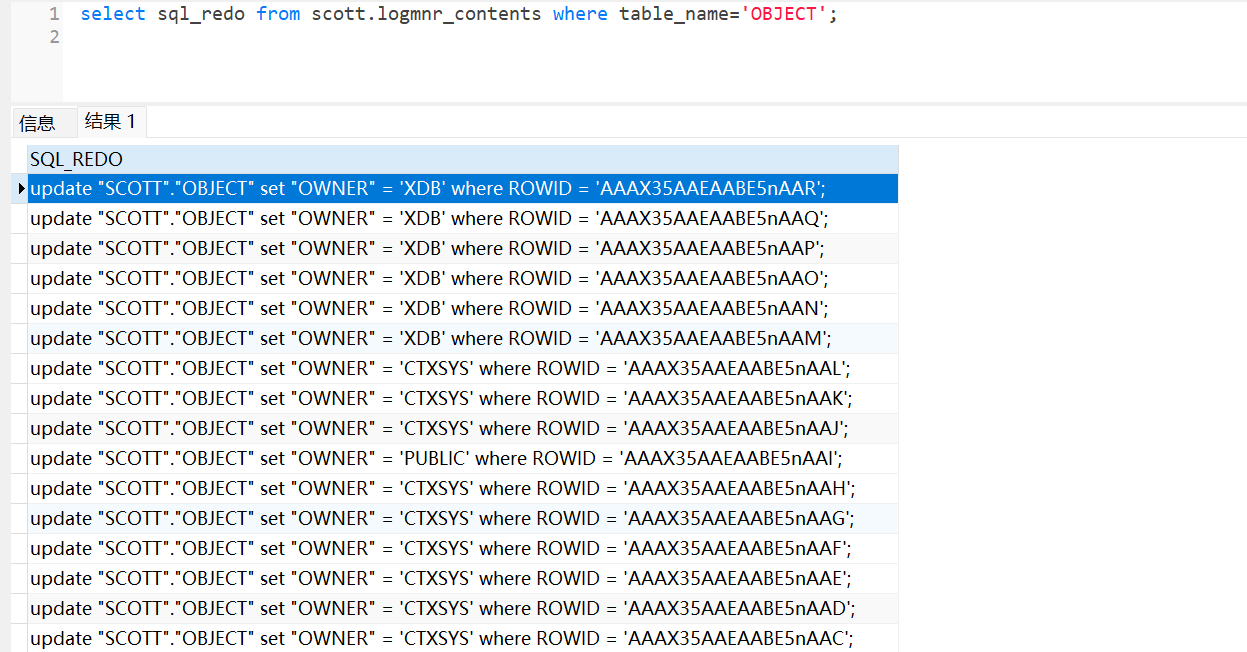
可以从归档日志中查看大量的update语句,此时基本可以排查出归档日志暴增原因
2.6 归档日志暴增优化
1.delete是否可以改造成truncate分区表(ps: truncate需谨慎,无法恢复相关数据)
2.dml可以适量使用临时表
3.避免大事务
4.避免大量for循环dml
Oracle归档日志暴增排查优化的更多相关文章
- oracle归档日志增长过快处理方法
oracle归档日志一般由dml语句产生,所以增加太快应该是dml太频繁 首先查询以下每天的归档产生的情况: SELECT TRUNC(FIRST_TIME) "TIME", SU ...
- ORACLE归档日志比联机重做日志小很多的情况总结
ORACLE归档日志比联机重做日志小很多的情况 前几天一网友在群里反馈他遇到归档日志比联机重做日志(redo log)小很多的情况,个人第一次遇到这种情况,非常感兴趣,于是在一番交流沟通后,终于弄 ...
- oracle归档日志关闭和打开
查询归档日志状态 方法一 SQL> archive log list; 方法二 SQL> select name,log_mode from V$database; 打开归档日志 orac ...
- 修改Oracle归档日志方法
修改Oracle归档日志的方法 Oracle默认安装的归档日志只有50M,在做大量操作的时候会经常切换日志文件,造成性能问题,下面是具体操作方法 1. 下面是查看现有归档日志大小: SQL> ...
- Oracle归档日志与非归档日志的切换及路径设置
--==================== -- Oracle 归档日志 --==================== Oracle可以将联机日志文件保存到多个不同的位置,将联机日志转换为归档日志的 ...
- 清除oracle归档日志
清除oracle归档日志 1. 连接oracle报如下错误 ORA-00257: archiver error. Connect internal only, until freed 产生原因:出现O ...
- ORACLE归档日志满了之后,如何删除归档日志
当ORACLE归档日志满后如何正确删除归档日志 版权声明:本文为博主原创文章,未经博主允许不得转载. 当ORACLE 归档日志满了后,将无法正常登入ORACLE,需要删除一部分归档日志才能正常登入OR ...
- Oracle归档日志所在目录时间不对&&Oracle集群日志时间显示错误
Oracle归档日志所在目录时间不对&&Oracle集群日志时间显示错误 前言 这个问题在18年的时候遇到了,基本不注意并且集群或者数据库运行正常是很难注意到的. 忘记当时怎么发现的了 ...
- 查看oracle归档日志路径
转至:https://blog.csdn.net/u010098331/article/details/50729896/ 查看oracle归档日志路径 1.修改归档日志的格式 默认格式是:" ...
随机推荐
- url路径匹配类
AntPathMatcher 1.AntPathMatcher类匹配URL规则如下 ?匹配一个字符 * 匹配0个或多个字符 * *匹配0个或多个目录 2.例子 /trip/api/*x 匹配 / ...
- day02 真正的高并发还得看IO多路复用
教程说明 C++高性能网络服务保姆级教程 首发地址 day02 真正的高并发还得看IO多路复用 本节目的 使用epoll实现一个高并发的服务器 从单进程讲起 上节从一个基础的socket服务说起我们实 ...
- HashMap中红黑树插入节点的调整过程
如果有对红黑树的定义及调整过程有过研究,其实很容易理解HashMap中的红黑树插入节点的调整过程. "红黑树定义及调整过程"的参考文章:<红黑树原理.查找效率.插入及变化规则 ...
- css3常用动画
//有道云笔记链接 http://note.youdao.com/s/72qbBVyv
- 爬取百度页面代码写入到文件+web请求过程解析
一.爬取百度页面代码写入到文件 代码示例: from urllib.request import urlopen #导入urlopen包 url="http://www.baidu.com& ...
- Vue路由实现之通过URL中的hash(#号)来实现不同页面之间的切换(图表展示、案例分析、附源码详解)
前言 本篇随笔主要写了Vue框架中路由的基本概念.路由对象属性.vue-router插件的基本使用效果展示.案例分析.原理图解.附源码地址获取. 作为自己对Vue路由进行页面跳转效果知识的总结与笔记. ...
- Go中rune类型浅析
一.字符串简单遍历操作 在很多语言中,字符串都是不可变类型,golang也是. 1.访问字符串字符 如下代码,可以实现访问字符串的单个字符和单个字节 package main import ( &qu ...
- CXP 协议中upconnection 与downconnection的说明及其区别
概述 CXP定义了一个DEVICE和HOST之间点对点的连接协议.CXP的一个连接包含了一个MASTER物理连接和若干可选的SLAVE连接,每一个连接都定义了一组逻辑通道用于传输图像数据.实时触发.设 ...
- consul系列文章02---替换掉.netcore的配置文件
如果是开发微服务的项目,多个服务的配置管理起来比较麻烦,需要集中管理,也就是需要有配置中心: consul集成配置中心的思路:读取配置文件时不在从本地的应用中读取,而是从consul的KEY/valu ...
- 存储器、I/O组织、微处理器
重点知识 存储器的内部结构及访问方法 存储器分段以及存储器中的逻辑地址和物理地址 I/O端口组织及编址方式 时序和总线操作以及系统的工作方式和特点. 存储器组织 8086有20根地址线,可寻址的存储器 ...