python爬虫,beatifulsop获取标签属性值(取值)案例
前面的案例里,均采用正则匹配的方式取值
title = re.findall('">(.*?)</a>', i, re.S)[0]#标题
url = re.findall('="(.*?)" target', i, re.S)[0]#地址
这么写的容错能力有限,爬取的数据越多,越容易出现匹配不到内容的情况
这次采用获取属性值的方式取值,除非属性变化,否则基本不会出现错误
爬取下图内链接红色框内文章标题和链接
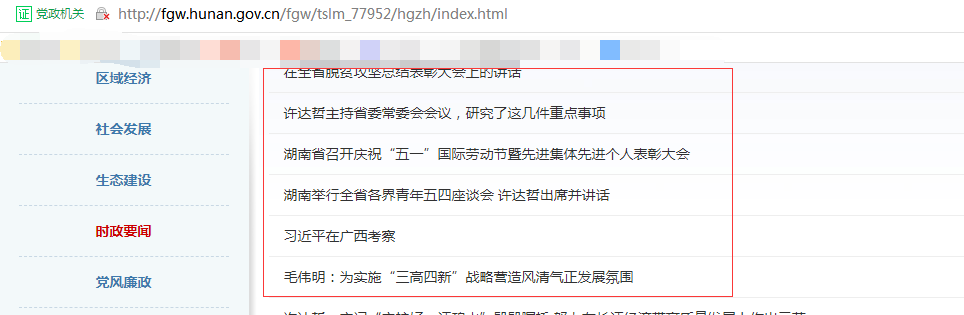
目标内容html结构如下图
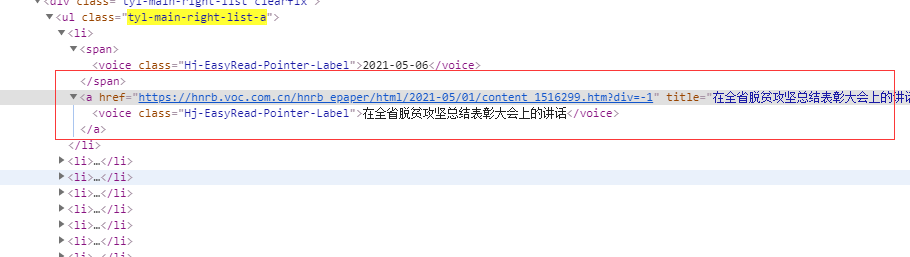
可见,href的值是链接,title的值是标题,所以,获取对应内容的写法如下
title = i.get("title")#地址
url = i.get("href")#地址
因为目标数据是通过匹配所有“a”标签来获取的,所有有一部分数据并不是本次案例需要的,为了使爬取的内容更加精简,所以对soup.find_all的匹配规则进行的补充
以前是直接写成“results = soup.find_all('a')”,后发现目标数列里有共同的“target='_blank'”内容,其他“a”内没有,所可以写成“results = soup.find_all('a', target='_blank')”

上面两处修改,使脚本爬取更加精准有效,容错能力得到提升
附全部代码
from bs4 import BeautifulSoup
import requests
import time fgwurl = 'http://fgw.hunan.gov.cn/fgw/tslm_77952/hgzh/index.html' def fgw(fgwurl):
response = requests.get(fgwurl)
response.encoding='utf-8'
soup = BeautifulSoup(response.text,'lxml')
results = soup.find_all('a', target='_blank')for i in results:
h=str(i)
if "title" in h:
#title = i.get_text()#标题
title = i.get("title")#地址
url = i.get("href")#地址
print(title +" "+ "详情请点击" + " " + url)
else:
None fgw(fgwurl)
参考链接:
https://blog.csdn.net/jaray/article/details/106604362
https://www.cnblogs.com/kaibindirver/p/9927297.html
http://blog.sina.com.cn/s/blog_166ae58120102xomk.html
python爬虫,beatifulsop获取标签属性值(取值)案例的更多相关文章
- python学习之----获取标签属性
到目前为止,我们已经介绍过如何获取和过滤标签,以及获取标签里的内容.但是,在网 络数据采集时你经常不需要查找标签的内容,而是需要查找标签属性.比如标签<a> 指向 的URL 链接包含在hr ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python中如何获取类属性的列表
这篇文章主要给大家介绍了在Python中如何获取类属性的列表,文中通过示例代码介绍的很详细,相信对大家的学习或者工作具有一定的参考借鉴价值,有需要的朋友可以参考借鉴,下面来一起看看吧. 前言 最近工作 ...
- UI自动化之特殊处理四(获取元素属性\爬取页面源码\常用断言)
获取元素属性\爬取页面源码\常用断言,最终目的都是为了验证我们实际结果是否等于预期结果 目录 1.获取元素属性 2.爬取页面源码 3.常用断言 1.获取元素属性 获取title:driver.titl ...
- Java循环一个对象的所有属性,并通过反射给这些属性赋值/取值
Java循环一个对象的所有属性,并通过反射给这些属性赋值/取值 说到循环遍历,最常见的遍历数组/列表.Map等.但是,在开发过程中,有时需要循环遍历一个对象的所有属性.遍历对象的属性该如何遍历呢?查了 ...
- Entity Framework 6 Recipes 2nd Edition(12-8)译 -> 重新获取一个属性的原始值
12-8. 重新获取一个属性的原始值 问题 在实体保存到数据库之前,你想重新获取属性的原始值 解决方案 假设你有一个模型 (见 Figure 12-11) 表示一个员工( Employee),包含工资 ...
- Cascade属性的取值
Cascade属性的取值有:1.none:忽略其他关联的对象,默认值.2.save-update:当session通过save(),update(),saveOrUpdate()方法来保存或更新对象时 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- spring scope 属性的取值
Spring 容器是通过单例模式创建 Bean 对象的,也就是说,默认情况下,通过调用 ac.getBean("mybean")方法获得的对象都是同一个 mybean 对象 使用单 ...
随机推荐
- HTTP劫持
HTTP劫持 想了解什么是HTTPS,要先知道什么是HTTP HTTP HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML文件,图片文件,查询结果等,一般基于B/S架构, ...
- ESP32 VScode环境问题
vsdcode esp-idf插件安装 报错: Espressif\tools\idf-python\3.11.2\python.exe -m pip" is not valid. (ERR ...
- 小程序之confirm-type改变键盘右下角的内容和input按钮详解
confirm-type的介绍 confirm-type 在什么时候使用呢? 如果说搜索框的时候,当用户输入完了之后,我们就需要 将confirm-type="search"的值设 ...
- C# 深度学习框架 TorchSharp 原生训练模型和图像识别-自定义网络模型和识别手写数字
目录 使用 Torch 训练模型 定义神经网络 加载数据集 创建网络模型 定义损失函数 训练 识别手写图像 教程名称:使用 C# 入门深度学习 作者:痴者工良 教程地址:https://torch.w ...
- 从“技术宅”到"机器人教父",那个用机器人改变世界的年轻人
写在前面 随着民营企业座谈会的召开,有一位年轻的企业家王兴兴映入了我们的视野.没错就是那个让机器人从实验室走向舞台中央的年轻人. 大家对今年春晚的机器人扭秧歌应该都还印象深刻吧,它就出自于王兴兴创办的 ...
- es5经典数组去重
es5经典数组去重 for (var i = 0; i < arr.length; i++) { for (var j = 1; j < arr.length; j++) { if (ar ...
- window本地部署deepseek
window本地部署deepseek 学习自[[教程]DeepSeek本地免费部署教程,丝滑不卡顿!带你解锁隐藏功能!]https://www.bilibili.com/video/BV1viFaeB ...
- STC内部扩展RAM的应用
RAM是用来在程序运行中存放随机变量的数据空间,51单片机默认的内部RAM只有128字节,52单片机增加至256字节,STC89C52增加到512字节,STC89C54.55.58.516等增加到12 ...
- 【小技巧】如何使上线前初始化数据的SQL脚本可测试?
背景 有时候,我们在上线某些特性时,可能需要提前初始化数据,才能使功能正常运作. 初始化数据,常用的有以下两种途径: 单纯为了这个初始化数据,开发一个Excel文件导入功能 开发人员维护SQL语句初始 ...
- kalibr标定单相机,自用指南,防忘记
1. 标定环境 1.1 从源码编译(linux环境,建议ubuntu 18或20) 步骤见 kalibr wiki 1.2 Docker 如果实体机为Ubuntu,则见official docker ...