数栈产品预告丨您的指标管理平台——EasyIndex即将上线
一、写在前面
2016年,数栈开始正式投入研发,发展至今,已经拥有了:实时开发、离线开发、算法开发这些开发平台;数据资产、数据质量这些资产平台;以及数据服务、智能标签这些服务平台,这些不同类型的产品,见证了我们产品体系逐步走向多样性、完整性的过程。
从开始到现在,积极的迭代新功能,推出新产品,完善整体的产品体系架构,满足越来越多的客户需求场景,一直是我们不变的目标。
今天我们为大家带来数栈产品的重磅预告,没错,数栈的新产品,指标管理平台EasyIndex就要来了!小伙伴们速速敲锣打鼓,奔走相告啦~
二、背景
随着社会的不断发展,大数据、云计算等现代信息技术带来的变革不言而喻。高效准确及时的数据统计方式逐渐替代传统统计工作,成为大数据市场环境下,管理部门掌握业务现状、辅助分析决策的主流方式。
这里我们引入一个名词——“指标”,指标是衡量目标的参数,指的是预期中打算达到的指数、规格、标准。
在现代市场应用中,指标是业务和数据的结合,快速准确的指标结果,使得业务目标可描述、可度量、可拆解,有助于更好地发挥数据的价值。目前指标作为量化实际业务效果的重要依据,正方方面面地充斥在工作生活中:
1、统计报表

(图源网络,侵删)
2、分析报告
(图源网络,侵删)
不管是报表也好,还是统计分析报告,都需要大量的数据指标去支撑验证其结论的可信度,这时候,快速准确的指标结果就显得尤为重要。
指标管理平台就在这种背景下应运而生。
三、EasyIndex是什么
因为是新产品,带着平台是做什么的、为什么做、为什么是EasyIndex这些问题,在开始前,先为大家简单介绍一下这个产品。
数栈指标管理平台EasyIndex,作为数据指标的综合管理中心,它承载了指标的业务需求、技术需求以及管理需求。通过指标的规范化定义、标准化开发,搭建企业数据指标体系,落地指标数据结果,同时提供指标的查询、服务等应用,消除数据二义性,降低业务与技术的沟通成本,最终实现指标数据的可视、可用、可管。
通俗地讲:就是有了咱们产品后,不管是开发指标、查询指标、计算指标还是管理指标,都能够通过平台在线实现,简单、快捷、灵活、易上手。
四、为什么要做EasyIndex
作为开发人员和业务分析人员,在对接指标数据计算需求,完成需求的过程中,可能都会遇到以下问题:
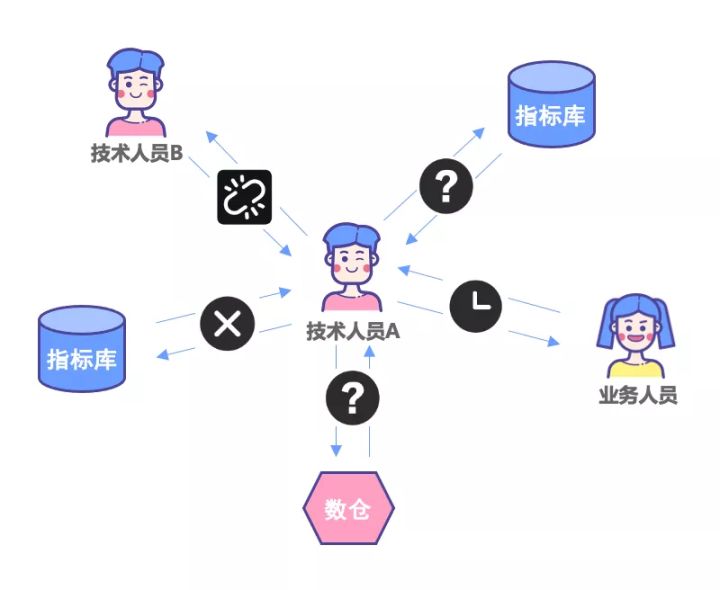
1、指标开发和使用分离
既懂业务又懂数据分析技术的人员不多,技术人员和业务人员需要不断地去对接需求,周期长、响应慢、效率低。
2、指标名称口径不一致
同样的指标名称,当技术人员去指标库中查询时,发现存在名称的指标,但是计算口径和需求不一致,还是需要重新开发。
3、指标计算逻辑不清晰
技术人员基于数仓环境开发指标的过程中,由于涉及到的表以及逻辑不清晰,导致开发出来的指标可信度不高。
4、大量指标重复开发:
相同的指标需求,可能存在另一个技术人员已经开发过了,因为两者互相之间的信息孤岛,所以存在重复开发的情况。
五、EasyIndex能带来什么
指标管理平台,就是为解决上述的这些场景而生:
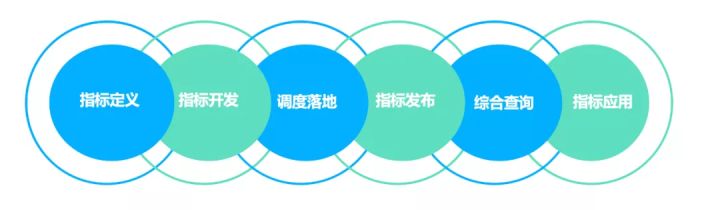
1、一站式的指标开发服务
覆盖指标管理从定义、开发、调度、落地、发布、应用的全过程,提供一站式的指标开发服务,通过平台能够实现指标管理中的各个过程,落地指标管理全流程,统一指标管理规范,沉淀指标资产。
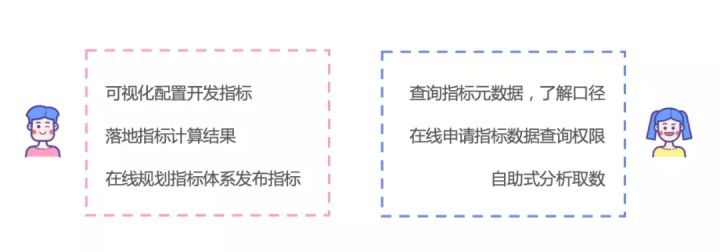
2、双视角精准服务
针对传统指标开发方式技术和业务不互通的情况,平台分别提供面向业务人员和技术人员双视角的指标管理服务。
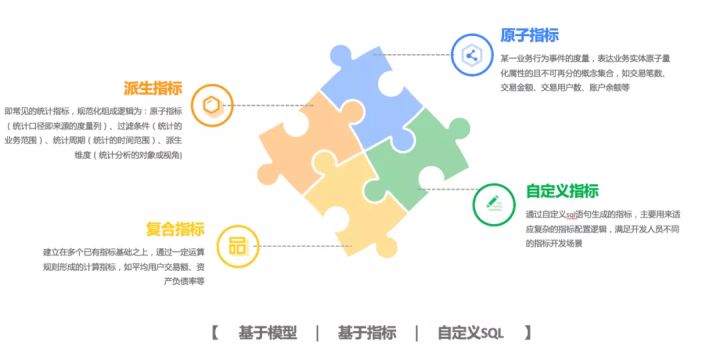
3、指标管理标准方法论
通过指标的分类,结合指标的开发方式搭建企业标准指标体系。
4、可视化轻代码开发
可视化的指标操作配置界面,方便在线开发配置指标,降低指标开发的技术门槛,让不懂统计sql的用户也能够依据业务逻辑,通过平台简单的操作实现指标的开发生成。
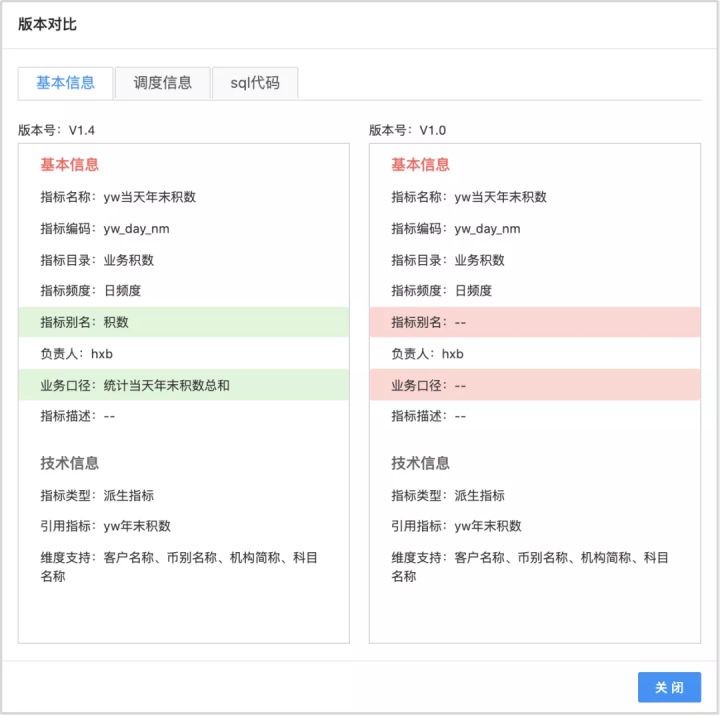
5、版本历史留痕
维护每个指标的历史版本记录,方便溯源获取历史版本的信息,了解指标变更的生命周期。
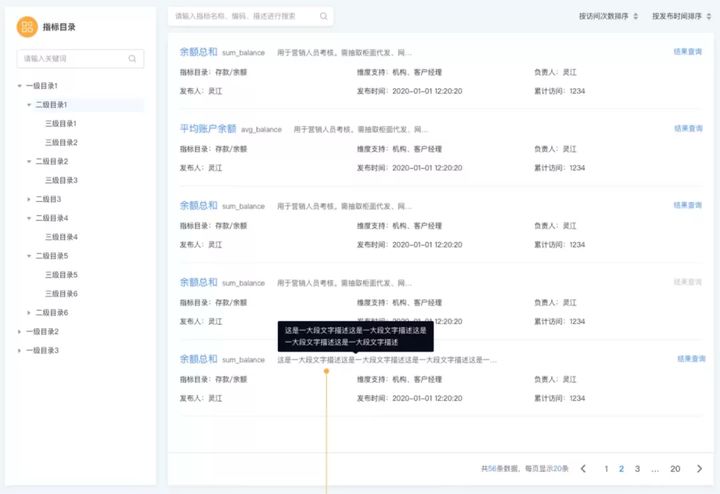
6、在线综合查询
在线综合查询所有指标,获取指标的详细信息,同时支持选中指标进行结果查询,在线查询获取结果数据。
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
数栈产品预告丨您的指标管理平台——EasyIndex即将上线的更多相关文章
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- 袋鼠云出品!数栈UI 5.0全新体验升级,设计背后的故事
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 前言 数栈作为云原⽣⼀站式⼤数据开发平台,从2016年发布第⼀个版本 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- 最佳实践丨使用Rancher轻松管理上万资源不是梦!
前 言 Rancher 作为一个开源的企业级 Kubernetes 集群管理平台.你可以导入现有集群,如 ACK.TKE.EKS.GKE,或者使用 RKE.RKE2.K3s 自定义部署集群. 作为业界 ...
- 简单设计一个onedata指标管理体系
以阿里云的maxcompute的数据仓库架构为例, 从上往下定义, dwp的数据,来源是dws+dim,最主要是dws.这里不讨论dim的作用. dws的数据来源于dwd. dwd的数据来源于ods. ...
- 转载:/etc/security/limits.conf 控制文件描述符,进程数,栈大小
原文地址:http://ilikedo.iteye.com/blog/1554822 linux下安装Oracle 一般都会修改/etc/security/limits.conf这个文件,但是这里面的 ...
- 活动预告丨易盾CTO朱浩齐将出席2018 AIIA大会,分享《人工智能在内容安全的应用实践》
本文来自网易云社区 对于很多人来讲,仿佛昨天才燃起来的人工智能之火,转眼间烧遍了各个角落,如今我们的生活中,处处渗透着人工智能.10月16日,2018年 AIIA人工智能开发者大会在苏州举办,网易云易 ...
- 技术分享预告丨k3s在边缘计算中的应用实践
技术分享是在[Rancher官方微信技术交流群]里以图文直播+QA实时互动的方式,邀请国内已落地经验的公司或团队负责人分享生产落地的最佳实践.记得添加微信小助手(微信号:rancher2)入群,实时参 ...
随机推荐
- BUUCTF---Cipher1(playfair)
playfair Playfair密码原理以及该题解题步骤 Playfair密码(Playfair cipher 或 Playfair square)一种替换密码,1854年由查尔斯·惠斯通(Char ...
- 【SpringCloud】SpringCloud Sleuth分布式链路跟踪
SpringCloud Sleuth分布式链路跟踪 概述 为什么会出现这个技术?需要解决哪些问题? 问题:在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后 ...
- TensorFlow重新导入restore报错: OP_REQUIRES failed at save_restore_v2_ops.cc:184 : Not found: Key Variable not found in checkpoint
最近在解决TensorFlow模型重新导入时遇到下面这个问题,发现网上很多解决办法都在误导,其实报错已经很明显说明问题的根源,只是我们不一定找到问题的根源.报错显示 不能在快照中找到 对应的键值. 报 ...
- 探秘Transformer系列之(25)--- KV Cache优化之处理长文本序列
探秘Transformer系列之(25)--- KV Cache优化之处理长文本序列 目录 探秘Transformer系列之(25)--- KV Cache优化之处理长文本序列 0x00 概述 0x0 ...
- python之random函数,随机取值
如 a =['辣椒炒肉','红烧肉','剁椒鱼头','酸辣土豆丝','芹菜香干'] 需要从a数组中随机取出一个值打印出来 具体脚本 import random a =['辣椒炒肉','红烧肉','剁椒 ...
- 为什么 MySQL 选择使用 B+ 树作为索引结构?
为什么 MySQL 选择使用 B+ 树作为索引结构? MySQL 选择 B+ 树作为其索引结构的主要原因是它具有以下几个优势,这些优势使得 B+ 树非常适合用于数据库系统中的索引实现. 1. 高效的范 ...
- java.security.provider.getservice blocked
JDK版本: JDK8u192 bug: https://bugs.openjdk.org/browse/JDK-8206333 堆栈: "Common-Business-Thread-57 ...
- 36条技巧优化PHP代码(总结)
原文:38条技巧优化PHP代码 1.如果一个方法能被静态,那就声明他为静态的,速度可提高1/4; 2.echo的效率高于print,因为echo没有返回值,print返回一个整型; 3.在循环之前设置 ...
- Android启动页正确的打开姿势
在App启动的时候需要加载一些东西,期间我们的App会是一片空白,强迫症,没办法---加个启动页吧!!! 1.首先写一个Activity,不需要写布局文件 public class SplashAct ...
- 在鸿蒙NEXT中开发一个2048小游戏
本项目是基于api12开发的2048游戏,游戏的逻辑是当用户向某个方向滑动时,将该方向相邻且相等的数字相加,同时在空白区域的随机位置生成一个随机数字.游戏中的数字越大,分数越高. 首先,游戏的界面布局 ...