selenium自动化测试-获取网页截图
今天学习下使用selenium自动化测试工具获取网页截图。
1,如果是简单获取当前屏幕截图只需要使用方法:
driver.get_screenshot_as_file('screenshot.png')
2,如果想获取完整网页长宽的截图需要设置参数后使用该方法:
首先打开驱动方式设置为无界面显示模式
# 打开驱动
def open_driver():
try:
# 连接浏览器web驱动全局变量
global driver
# Linux系统下浏览器驱动无界面显示,需要设置参数
# “–no-sandbox”参数是让Chrome在root权限下跑
# “–headless”参数是不用打开图形界面 chrome_options = Options()
# 设为无头模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
# 连接Chrome浏览器驱动,获取驱动
driver = webdriver.Chrome(chrome_options=chrome_options)
''' # 此步骤很重要,设置chrome为开发者模式,防止被各大网站识别出来使用了Selenium
options = Options()
# 静默模式(加载浏览器的静默模式,让它在后台偷偷运行)
# options.add_argument('headless')
# 去掉提示:Chrome正收到自动测试软件的控制
options.add_argument('disable-infobars')
# 以键值对的形式加入参数,打开浏览器开发者模式
# options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 打开浏览器开发者模式
# options.add_argument("--auto-open-devtools-for-tabs")
driver = webdriver.Chrome(chrome_options=options)
'''
# driver = webdriver.Chrome()
print('连接Chrome浏览器驱动')
# 浏览器窗口最大化
driver.maximize_window()
'''
1, 隐式等待方法
driver.implicitly_wait(最大等待时间, 单位: 秒)
2, 隐式等待作用
在规定的时间内等待页面所有元素加载;
3,使用场景:
在有页面跳转的时候, 可以使用隐式等待。
'''
driver.implicitly_wait(3)
# 强制等待,随机休眠 暂停0-3秒的整数秒,时间区间:[0,3]
time.sleep(random.randint(0, 3)) except Exception as e:
driver = None
print(str(e))
然后设置网页长宽最大化,保证截图是完整的,不会出现滚动条
S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)
driver.set_window_size(S('Width'), S('Height'))
driver.get_screenshot_as_file('screenshot.png')
3,编写代码
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块,代码中缺少的封装方法代码,详情参考之前的《selenium自动化测试》文章。
def spider_screenshot_image(req_dict):
'''
@方法名称: 爬取网页内容截图文件
@中文注释: 爬取网页内容截图文件
@入参:
@param req_dict dict 请求容器
@出参:
@返回状态:
@return 0 失败或异常
@return 1 成功
@返回错误码
@返回错误信息
@param rsp_dict dict 响应容器
@作 者: PandaCode辉
@weixin公众号: PandaCode辉
@创建时间: 2023-09-26
@使用范例: spider_screenshot_image(req_dict)
''' try:
if (not type(req_dict) is dict):
return [0, "111111", "请求容器参数类型错误,不为字典", [None]] # 截图目录
screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir) print('打开浏览器驱动')
open_driver() # 打开网址网页
print('打开网址网页')
driver.get(req_dict['url'])
# 等待6秒启动完成
driver.implicitly_wait(6)
print('随机休眠')
# 随机休眠 暂停0-2秒的整数秒
time.sleep(random.randint(0, 2)) # 保存当前网页屏幕快照PNG图像文件,截图不保证完整网页内容都截取到
page_file_1 = os.path.join(screenshot_dir, 'page1.png')
isprint = driver.get_screenshot_as_file(page_file_1)
print(isprint) # 网页长宽最大化,保证截图是完整的,不会出现滚动条
S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)
driver.set_window_size(S('Width'), S('Height')) # 保存当前网页屏幕快照PNG图像文件
page_file_2 = os.path.join(screenshot_dir, 'page2.png')
isprint = driver.get_screenshot_as_file(page_file_2)
print(isprint) # 章节内容截图
image_file = os.path.join(screenshot_dir, 'content.png')
# 元素定位
elem = driver.find_element(By.ID, req_dict['elem_id'])
print(elem)
# 元素截图
isprint = elem.screenshot(image_file)
print(isprint) print('关闭浏览器驱动')
close_driver() print("爬取网页内容截图文件成功")
# 返回容器
return [1, '000000', '爬取网页内容截图文件成功', [None]] except Exception as e:
print('关闭浏览器驱动')
close_driver()
print("爬取网页内容截图文件异常," + str(e))
return [0, '999999', "爬取网页内容截图文件异常," + str(e), [None]]
4,运行效果
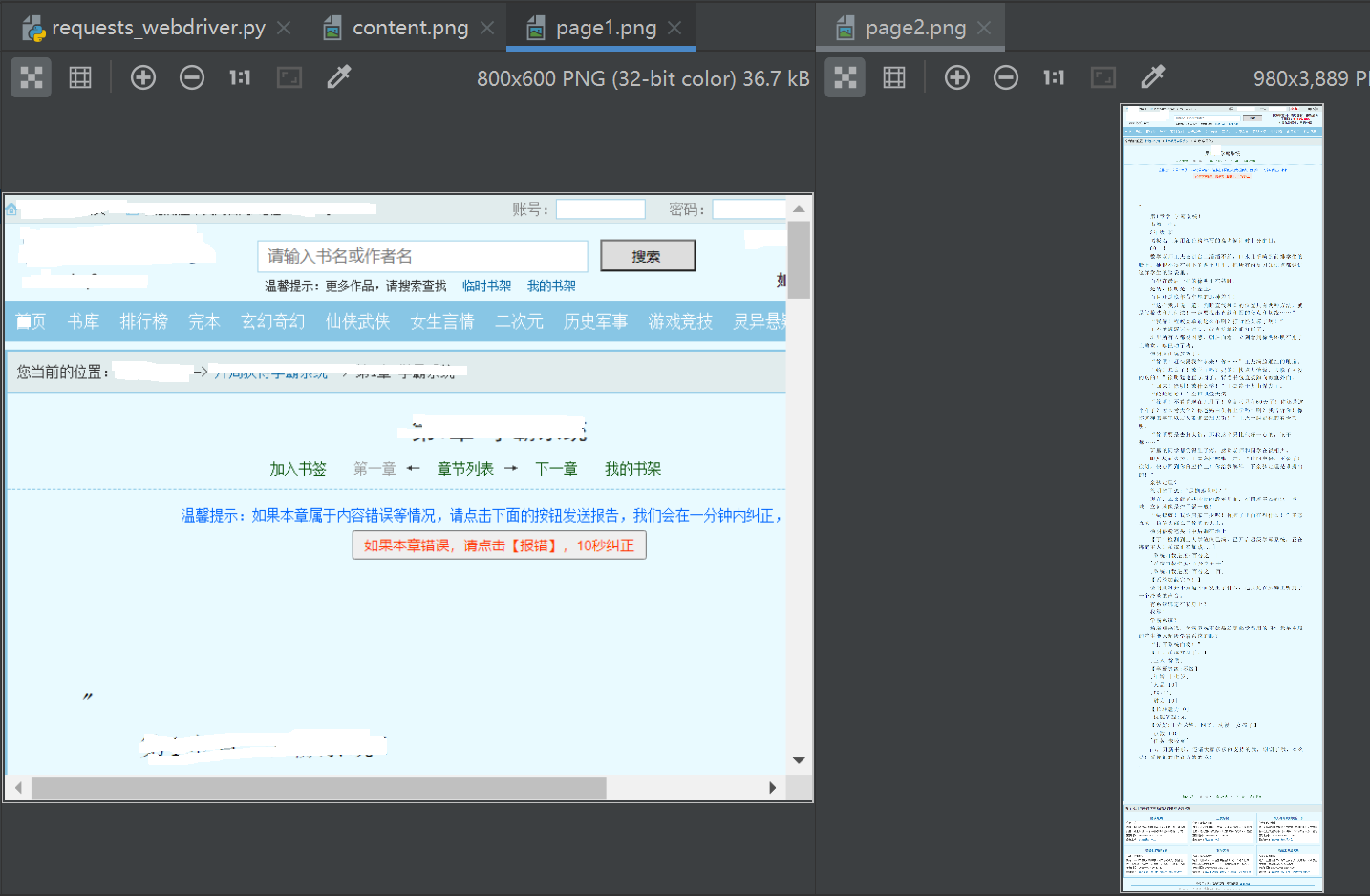
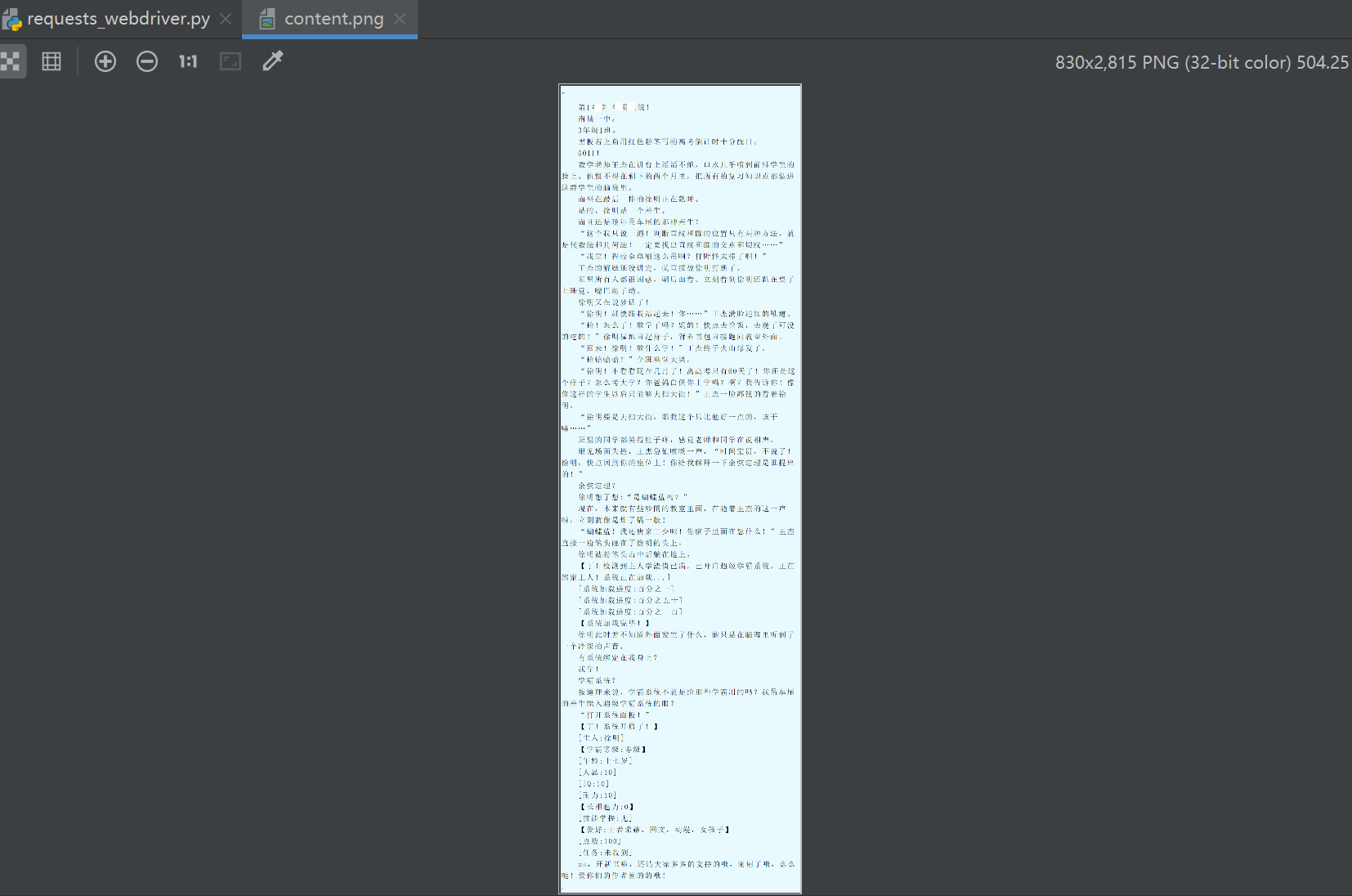
最后说明:上述文章仅供学习参考,请勿用于商业用途,感谢阅读。
selenium自动化测试-获取网页截图的更多相关文章
- 大型情感剧集Selenium:8_selenium网页截图的四种方法
有时候,有时候,你会相信一切有尽头-当你的代码走到了尽头,那么保留最后一刻的状态尤为重要,此时你该如何操作?记录日志-没有将浏览器当前的状态进行截图来的直观! 那么,selenium截取截屏,有哪些方 ...
- Python3.X Selenium 自动化测试中如何截图并保存成功
在selenium for python中主要有三个截图方法,我们挑选其中最常用的一种. 挑最常用的:get_screenshot_as_file() 相关代码如下:(下面的代码可直接复制) # co ...
- Python+Selenium 自动化测试获取测试报告内容并发送邮件
这里封装一个send_mail()方法,用于测试完成后读取测试报告内容,并将测试结果通过邮件发送到接收人 # coding: utf-8 import smtplib from email.mime. ...
- Python中使用 Selenium 实现网页截图实例
Selenium 是一个可以让浏览器自动化地执行一系列任务的工具,常用于自动化测试.不过,也可以用来给网页截图.目前,它支持 Java.C#.Ruby 以及 Python 四种客户端语言.如果你使用 ...
- 记一个Selenium自动化测试网页
今天想跟大家分享的是Selenium自动化测试网页,就是关于selenium的自动化测试一些基础的东西,如有不对的地方请多多指教. 一.安装环境 1.Python环境 安装完成后通过Windows命令 ...
- 《手把手教你》系列技巧篇(五十九)-java+ selenium自动化测试 - 截图三剑客 -上篇(详细教程)
1.简介 今天本来是要介绍远程测试的相关内容的,但是宏哥在操作服务器的时候干了件糊涂的事,事情经过是这样的:本来申请好的Windows服务器用来做演示的,可是服务器可能是局域网的,连百度都不能访问,宏 ...
- 《手把手教你》系列技巧篇(六十一)-java+ selenium自动化测试 - 截图三剑客 -下篇(详细教程)
1.简介 按照计划宏哥今天将介绍java+ selenium自动化测试截图操作实现的第三种截图方法,也就是截图的第三剑客 - 截取某个元素(或者目标区域)的图片.在测试的过程中,有时候不需要截取整个屏 ...
- Python3 Selenium WebDriver网页的前进、后退、刷新、最大化、获取窗口位置、设置窗口大小、获取页面title、获取网页源码、获取Url等基本操作
Python3 Selenium WebDriver网页的前进.后退.刷新.最大化.获取窗口位置.设置窗口大小.获取页面title.获取网页源码.获取Url等基本操作 通过selenium webdr ...
- 使用selenium的方式获取网页中图片的链接和网页的链接,来判断是否是死链(二)
上一篇使用Java正则表达式来判断和获取图片的链接以及跳转的网址,这篇使用selenium的自带的API(getAttribute)来获取网页中指定的内容 实现内容:获取下面所有图片的链接地址以及跳转 ...
- Selenium WebDriver-网页的前进、后退、刷新、最大化、获取窗口位置、设置窗口大小、获取页面title、获取网页源码、获取Url等基本操作
通过selenium webdriver操作网页前进.后退.刷新.最大化.获取窗口位置.设置窗口大小.获取页面title.获取网页源码.获取Url等基本操作 from selenium import ...
随机推荐
- Qt安卓开发经验011-020
安卓中一个界面窗体对应一个Activity,多个界面就有多个Activity,而在Qt安卓程序中,Qt这边只有一个Activity那就是QtActivity(包名全路径 org.qtproject.q ...
- hhhhhhomework 验证码界面(非全部自己完成)
import javax.swing.*;//import 代表"引入" //javax.swing 代表"路径" (在javax文件夹下的swing文件夹) ...
- _findnext()调试中断,发生访问错误,错误定位到ntdll.dll
问题: 采用_findfirst和_findnext获取指定的文件夹下的文件时,_findnext()函数在调试时发生中断,发生访问错误,错误定位到ntdll.dll.错误提示如下所示: _findn ...
- ArchLinux安装后常见问题的解决
Q:UEFI引导grub-install报错:variables are not support on this system A:进入安装u盘的时候是传统引导模式,传统模式下无法安装UEFI启动,解 ...
- Java中的值类型
在打算了解Java的时候,根据C#的经验,了解一下Java中有哪一些值类型,如何判断某个类型为值类型还是引用类型是一件值得做的事情. 在C#中,值类型存放在栈中,不需要垃圾回收,引用类型存放在堆中,需 ...
- 隐私集合求交(PSI)-多方
本文主要讲解一个多方的PSI协议,文章转载:隐私计算关键技术:多方隐私集合求交(PSI)从原理到实现以及多方隐私求交--基于OPPRF的MULTI-PARTY PSI:原论文:Practical Mu ...
- HashMap的底层实现原理? HashMap 和 Hashtable的异同? 负载因子值的大小,对HashMap有什么影响?
1. HashMap的底层实现原理 HashMap的底层:数组+链表 (jdk7及之前) 数组+链表+红黑树 (jdk 8)HashMap的底层实现原理?以jdk7为例说明: HashMap map ...
- RoboMaster- RDK X5能量机关实现案例(一)识别
作者:SkyXZ CSDN:https://blog.csdn.net/xiongqi123123 博客园:https://www.cnblogs.com/SkyXZ 在RoboMaster的25赛季 ...
- LeetCode刷题小白必看!如何科学地刷题,从0到1建立你的算法体系?
大家好,我是忍者算法的作者,今天想和大家聊聊如何科学地刷题.如果你是一个刚开始刷题的小白,面对LeetCode上密密麻麻的题目感到无从下手,或者刷了一段时间却发现自己进步缓慢,那么这篇文章就是为你准备 ...
- 如何让JS代码变的安全?
本文分享自天翼云开发者社区<如何让JS代码变的安全?>,作者:温****双 前端JS代码,直接暴露在浏览器中,任何访问者,都可以随意查看代码.这就导致代码可以被分析.复制.盗用等,进而引发 ...