Transformer架构介绍+从零搭建预训练模型项目
Transformer架构详解
1. 架构概述
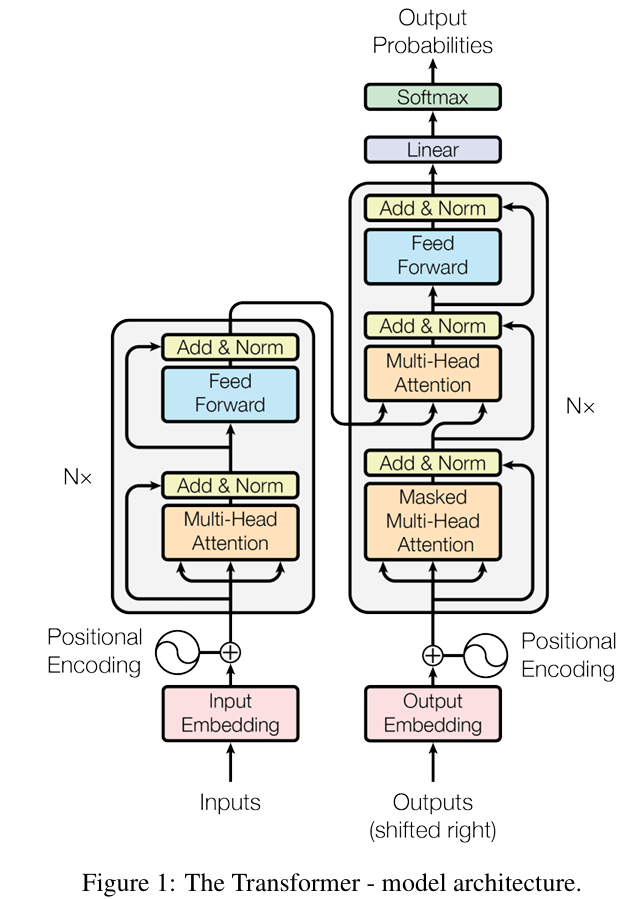
Transformer是一种基于自注意力机制的神经网络架构,由Vaswani等人在2017年的论文《Attention Is All You Need》中首次提出。它彻底改变了自然语言处理领域,逐步取代了传统的RNN和CNN架构。
主要特点
- 完全基于注意力机制:摒弃了传统的循环和卷积结构
- 并行计算能力强:克服了RNN的顺序计算限制
- 长距离依赖捕捉能力:通过自注意力机制有效捕捉任意距离的依赖关系
- 模块化设计:编码器-解码器结构清晰,易于扩展
2. 核心组件详解
2.1 编码器(Encoder)
结构组成
输入嵌入层(Input Embedding)
- 将输入的token转换为稠密向量表示
- 通常维度为512(d_model)或更大
- 包含可学习的参数矩阵
位置编码(Positional Encoding)
- 解决Transformer缺少位置信息的问题
- 使用正弦和余弦函数的固定模式:
PE(pos,2i) = sin(pos/10000^(2i/d_model))
PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
- 与输入嵌入相加而非拼接
编码器层堆叠(Encoder Layers)
- 通常6层或更多(原始论文使用6层)
- 每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network)
- 每个子层都有残差连接和层归一化
自注意力机制细节
计算过程:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
- Q(Query), K(Key), V(Value)来自同一输入
- √d_k缩放防止点积过大导致梯度消失
多头注意力:
- 将Q,K,V投影到h个不同子空间(h通常为8)
- 并行计算h个注意力头
- 拼接所有头的结果并通过线性变换
2.2 解码器(Decoder)
结构组成
输出嵌入层(Output Embedding)
- 与编码器嵌入层类似但独立
- 通常共享编码器嵌入层的权重(可选)
位置编码
- 与编码器使用相同的实现方式
解码器层堆叠(Decoder Layers)
- 通常6层(与编码器层数相同)
- 每层包含三个子层:
- 掩码多头自注意力(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力(Encoder-Decoder Attention)
- 前馈神经网络
- 每个子层都有残差连接和层归一化
关键机制
掩码自注意力:
- 防止解码器"偷看"未来信息
- 通过添加负无穷掩码(-∞)实现
- 确保位置i只能关注位置≤i的token
编码器-解码器注意力:
- Q来自解码器前一层的输出
- K,V来自编码器的最终输出
- 允许解码器关注输入序列的相关部分
2.3 词表与分词器(Tokenizer)
主流分词方法
Byte Pair Encoding (BPE)
- 通过合并频繁出现的字节对逐步构建词表
- 平衡词表大小与token序列长度
- 被GPT系列模型采用
WordPiece
- 类似BPE但基于概率合并
- 被BERT等模型采用
SentencePiece
- 直接从原始文本训练
- 支持Unicode字符级处理
- 不依赖预处理分词
词表设计考量
- 大小通常在30k-100k之间
- 包含特殊token([CLS],[SEP],[MASK]等)
- 处理未知token的方式(如[UNK]或字节级回退)
2.4 位置编码的演进
原始正弦编码:
- 固定模式,无需学习
- 理论上可外推到任意长度
可学习位置编码:
- 将位置视为可学习的嵌入
- 被BERT等模型采用
- 但受限于训练时见过的最大长度
相对位置编码:
- 关注token之间的相对距离而非绝对位置
- 多种变体(T5, Transformer-XL等)
- 更好的长度外推能力
旋转位置编码(RoPE):
- 通过旋转矩阵注入位置信息
- 被LLaMA等最新模型采用
- 保持相对位置关系的线性特性
3. 训练机制
3.1 优化目标
语言建模目标:
- 自回归模型(GPT风格):最大化下一个token的似然
- 自编码模型(BERT风格):预测被掩码的token
损失函数:
- 交叉熵损失(Cross-Entropy Loss)
- 可选项:标签平滑(Label Smoothing)
3.2 优化策略
Adam优化器变种:
- 原始Transformer使用Adam(β1=0.9, β2=0.98, ε=1e-9)
- 现代变种:AdamW(解耦权重衰减)
学习率调度:
- 预热学习率(Warmup):
lrate = d_model^-0.5 * min(step_num^-0.5, step_num*warmup_steps^-1.5)
- 余弦衰减
- 线性衰减
- 预热学习率(Warmup):
正则化技术:
- Dropout(原始论文使用0.1)
- 权重衰减(通常0.01)
- 梯度裁剪(通常1.0)
4. 架构演进与变体
4.1 经典变体
BERT (2018)
- 仅使用编码器
- 双向自注意力
- 掩码语言建模目标
GPT (2018)
- 仅使用解码器(带掩码)
- 自回归语言建模
T5 (2019)
- 编码器-解码器完整结构
- 将所有任务统一为文本到文本格式
4.2 效率优化方向
稀疏注意力:
- Longformer(2020):局部+全局注意力
- BigBird(2020):随机+局部+全局注意力
混合架构:
- FNet(2021):用傅里叶变换替代注意力
- Hyena(2023):结合CNN与注意力
状态空间模型:
- Mamba(2023):选择性状态空间
4.3 现代大语言模型架构
GPT-3/4:
- 纯解码器架构
- 旋转位置编码
- 极深(96层以上)和极宽(12288维度)
LLaMA:
- RMSNorm替代LayerNorm
- SwiGLU激活函数
- 旋转位置编码
PaLM:
- 并行注意力与前馈计算
- 共享QKV投影
5. 实践建议
5.1 超参数选择
维度关系:
- d_model(模型维度):通常512-12288
- d_ff(前馈层维度):通常4*d_model
- h(注意力头数):通常d_model/64
深度选择:
- 基础模型:6-12层
- 大型模型:24-96层
- 极深模型:100+层
5.2 训练技巧
初始化策略:
- 注意力层:Xavier/Glorot初始化
- 残差连接:初始化为1/√N(N为层数)
精度选择:
- FP32:传统选择
- FP16/BF16:现代标准
- 混合精度训练:常用实践
批处理策略:
- 动态批处理
- 梯度累积
6. 关键数学原理
6.1 注意力机制数学
缩放点积注意力:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
- Q ∈ ℝ^{n×d_k}, K ∈ ℝ^{m×d_k}, V ∈ ℝ^
- 计算复杂度:O(nmd_k + nmd_v)
多头注意力:
MultiHead(Q,K,V) = Concat(head_1,...,head_h)W^O
其中:
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
6.2 前馈网络
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
- 通常d_ff = 4*d_model
- 现代变体使用GELU或SwiGLU
6.3 层归一化
LayerNorm(x) = γ ⊙ (x - μ)/σ + β
- μ,σ为均值和标准差
- γ,β为可学习参数
7. 典型应用场景
文本生成:
- 自回归采样策略(贪心、beam search、top-k/p采样)
- 温度控制
机器翻译:
- 编码器处理源语言
- 解码器生成目标语言
文本分类:
- 使用[CLS]token或平均池化
- 接分类头
问答系统:
- 编码问题与上下文
- 预测答案起始/结束位置
项目实例
项目实例:https://github.com/toke648/SimpleLLM

一个基于Transformer架构实现的简易LLM大语言模型,完全自定义Transformer,通过大量的问答数据训练实现,支持自定义训练流程以及超参数等
从最基础的训练词表开始到构建Transformer、训练模型、推理,完全从代码上完整的大模型训练全流程
详细介绍了训练流程以及操作方法,并且持续更新
感兴趣的点个star,Ciallo~(∠・ω< )⌒★
欢迎贡献代码
相关文章
Attention Is All You Need:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Attention Is All You Need 解读:https://blog.csdn.net/chengyq116/article/details/106065576/
Attention as Energy Minimization Visualizing Energy Landscapes(大佬博客):https://mcbal.github.io/post/attention-as-energy-minimization-visualizing-energy-landscapes/
.......
(正在施工)
Transformer架构介绍+从零搭建预训练模型项目的更多相关文章
- 从零搭建一个SpringCloud项目之Feign搭建
从零搭建一个SpringCloud项目之Feign搭建 工程简述 目的:实现trade服务通过feign调用user服务的功能.因为trade服务会用到user里的一些类和接口,所以抽出了其他服务需要 ...
- 从零搭建一个IdentityServer——项目搭建
本篇文章是基于ASP.NET CORE 5.0以及IdentityServer4的IdentityServer搭建,为什么要从零搭建呢?IdentityServer4本身就有很多模板可以直接生成一个可 ...
- 从零搭建react hooks项目(github有源代码)
前言 首先这是一个react17的项目,包含项目中常用的路由.状态管理.less及全局变量配置.UI等等一系列的功能,开箱即用,是为了以后启动项目方便,特地做的基础框架,在这里分享出来. 这里写一下背 ...
- 从零搭建vue3.0项目架构(附带代码、步骤详解)
前言: GitHub上我开源了vue-cli.vue-cli3两个库,文章末尾会附上GitHub仓库地址.这次把2.0的重新写了一遍,优化了一下.然后按照2.0的功能和代码,按照vue3.0的语法,完 ...
- Ionic01 简单介绍、环境搭建、创建项目、项目结构、创建组件、创建页面、子页面跳转
1 Ionic 基本介绍 Ionic 是一款基于 Angular.Cordova 的强大的 HTML5 移动应用开发框架 , 可以快速创建一个跨平台的移动应用.可以快速开发移动 App.移动端 WEB ...
- 使用Vue脚手架(vue-cli)从零搭建一个vue项目(包含vue项目结构展示)
注:在搭建项目之前,请先安装一些全局的工具(如:node,vue-cli等) node安装:去node官网(https://nodejs.org/en/)下载并安装node即可,安装node以后就可以 ...
- 从零搭建一个SpringCloud项目之Config(五)
配置中心 一.配置中心服务端 新建项目study-config-server 引入依赖 <dependency> <groupId>org.springframework.cl ...
- 从零搭建一个SpringCloud项目之Zuul(四)
整合Zuul 为什么要使用Zuul? 易于监控 易于认证 减少客户端与各个微服务之间的交互次数 引入依赖 <dependency> <groupId>org.springfra ...
- 从零搭建一个IdentityServer——目录(更新中...)
从零搭建一个IdentityServer--项目搭建 从零搭建一个IdentityServer--集成Asp.net core Identity 从零搭建一个IdentityServer--初识Ope ...
- 从零搭建Pytorch模型教程(三)搭建Transformer网络
前言 本文介绍了Transformer的基本流程,分块的两种实现方式,Position Emebdding的几种实现方式,Encoder的实现方式,最后分类的两种方式,以及最重要的数据格式的介绍. ...
随机推荐
- tf.keras.layers.Attention: Dot-product attention layer, a.k.a. Luong-style attention.
tf.keras.layers.Attention( View source on GitHub ) Dot-product attention layer, a.k.a. Luong-style a ...
- POLIR-Society-Organization-Politics-Self- Identity:Qualities + Habits:To-Be List + Behaviors:To-Do List + Prioritize: ProblemsResolving
POLIR-Society-Organization-Political Habits:To-Be List Behaviors:To-Do List when it comes to habits, ...
- SciTech-BigDataAIML-LLM-Transformer Series- transformer-explainer
transformer-explainer: https://github.com/poloclub/transformer-explainer
- SciTech-BigDataAIML-Adam动量自适应的梯度快速收敛
http://faculty.bicmr.pku.edu.cn/~wenzw/optbook/pages/stograd/Adam.html 版权声明 此页面为<最优化:建模.算法与理论> ...
- 06Java基础之方法
什么是方法 Java方法是语句的集合,他们在一起执行一个功能. 方法是解决一类问题的步骤的有序组合 方法包含于类或者对象中 方法在程序中被创建,在其他地方被吸引 设计方法的原则:方法的本意是功能块,就 ...
- Web前端入门第 82 问:JavaScript cookie 有大小限制吗?溢出会怎样?
面试时候经常会被问及 Cookie 大小限制,但一直没尝试写一些 demo 测试下溢出极限值会怎样~~ 本文就来看看各种极限情况! 英文 测试代码: (() => { const maxSize ...
- Windows下MySQL5.7免安装版配置
一.软件下载 mysql5.7 64位下载地址:https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.19-winx64.zip 二.操作步骤 ...
- Adobe2024全家桶大更新, 包含Win/Mac M1 M2 ,安装教程分享
按照以往的惯例每年的10月份下旬将会迎来Adobe一年一度的软件大更新,大家期待已久的 Adobe 2024 全家桶终于来了,这次可以说是不痛不痒的大更新,喜欢尝鲜的小伙伴赶紧安排上! Adobe 2 ...
- CH3 初识 TensorFlow
了解引入的需要神经网络解决的问题 学习用神经网络的基本结构.表达方式和编程实现 学习训练神经网络的基本方法 三好学生成绩问题 总分 = 德育分 * 60% + 智育分 * 60% + 体育分 * 60 ...
- 如何正确使用SetThreadExecutionState来阻止Windows进入睡眠
最近产品有个需求,需要在升级的时候阻止Windows系统进入自动睡眠.需求到手后,小搜了一下,搜到SetThreadExecutionState这个函数,相关的博客挺多,官方文档也挺清晰,想必应该是手 ...