一次生产 KubeSphere 日志无法正常采集事件解决记录
作者:宇轩辞白,运维研发工程师,目前专注于云原生、Kubernetes、容器、Linux、运维自动化等领域。
前言
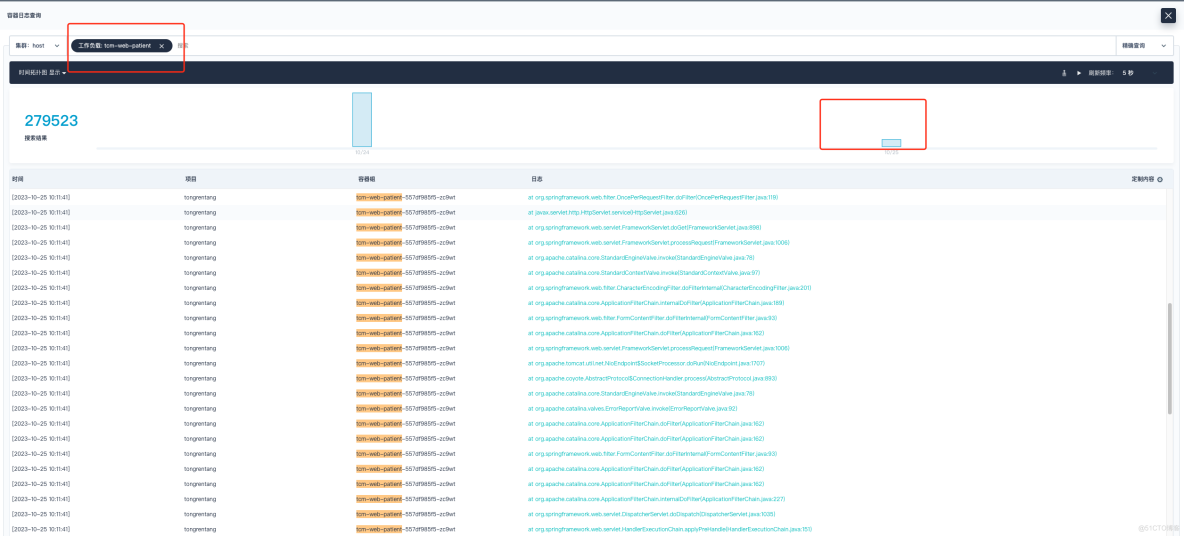
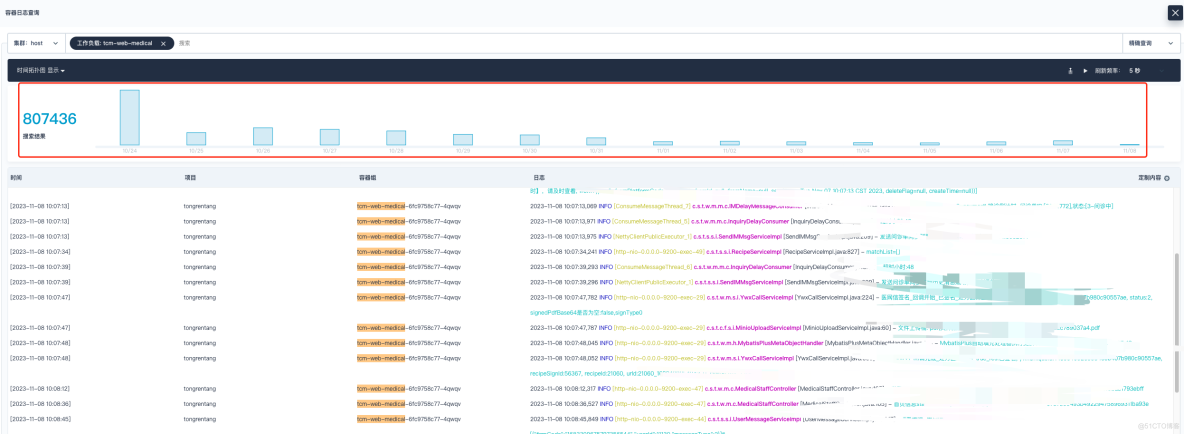
2023 年 11 月 7 号下午,研发同事反馈,项目线上日志平台某个服务无法查看近期的日志。我登上 KubeSphere 平台进行查看,发现日志收集展示停留在 10 月 15 号那天,而其它的服务是正常的。
问题跟踪定位分析
结合已有的经验积累,我做了如下猜想:
- 一种原因,是不是日志系统对应的 PVC 存储卷被打满了,导致日志索引被锁定,间接影响服务的日志采集呢?
- 另一种原因,日志采集工具 Fluent Bit 缓冲区资源配置无法满足当前的日志输出量,也会导致该问题的出现。
为了验证上述的猜想,我展开了详细排查:
- 把 es 的接口放开,查询索引状态,看看有没有被锁定的。
- 确认无法收集日志容器所在的 node 节点,并找与之对应同 node 节点的 Fluent Bit 容器服务,查看 Fluent Bit 日志输出是否存在异常信息。
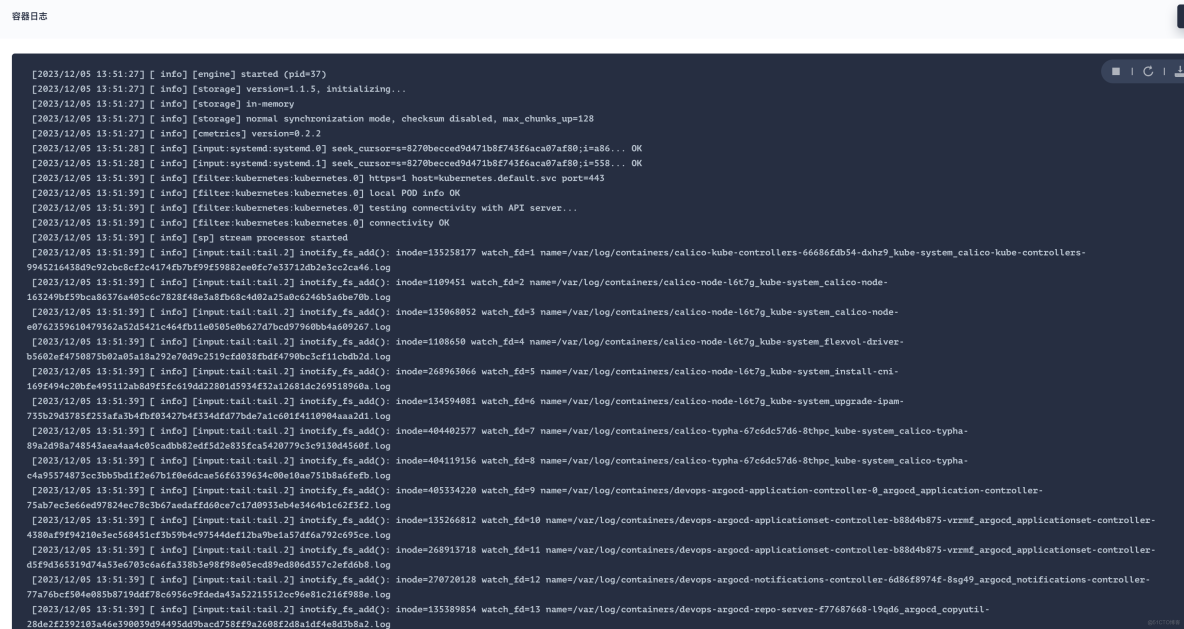
登录到 node 节点查看 Fluent Bit 服务日志信息,关键信息如下:
[2023/07/23 00:15:37][ warn] [http_client] cannot increase buffer: current=512000 requested=544768 max=512000
{"log":"[2023/11/08 10:26:33][ warn] [input] tail.2 paused (mem buf overlimit)\n","stream":"stderr","time":"2023-11-08T10:26:33.406030339Z"}

报错问题分析 1
tail.2 paused (mem buf overlimit) 表示 tail 输入插件在 Fluent Bit 中的实例 tail.2 因为内存缓冲区超出限制而被暂停。 这个告警信息意味着 Fluent Bit 的内存缓存区超过了先前设置的"memBuflimit"限制的大小,导致插件被暂停。之后,存储缓冲区超过限制时被恢复,这可能代表着 Fluent Bit 尝试将一些缓冲数据写入目标存储介质。
这通常是由于日志产生的速度过快,而内存缓冲区无法及时处理并写入到输出目标中,结合问题现象来看,那就不难说明日志为啥在 10 月 25 号之后就没有采集展示了。
报错问题分析 2
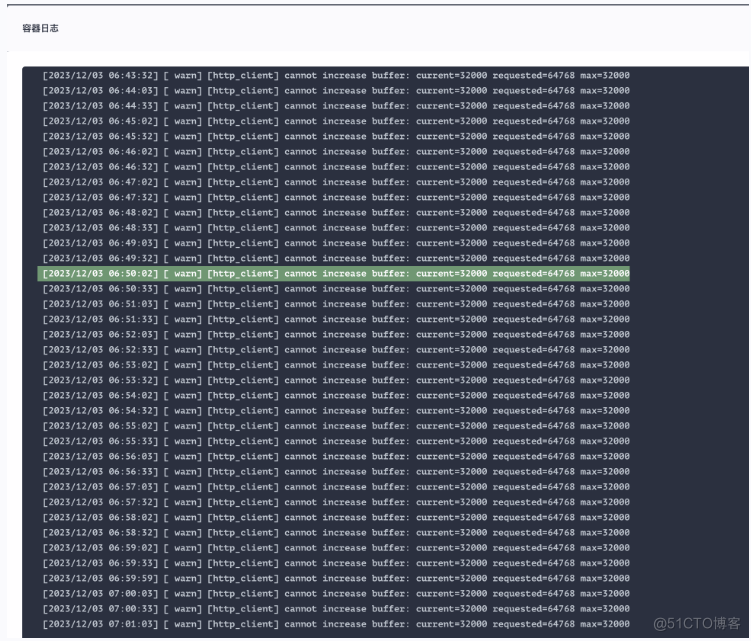
根据日志信息中 [ warn] [http_client] cannot increase buffer: current=32000 requested=64768 max=32000 可知,在 HTTP 客户端无法增加缓冲区大小。当前的缓冲区大小为 32000B(也就是默认大小为 32KB 字节),无法满足请求。由于项目是初期建设,日志平台参数都没有进行优化调整,都保持默认值,因此当日志量级达到一定的级别就会出现该问题,且无法动态调整。
解决方案
针对上述问题,这里可以尝试通过以下方案去解决该问题:
增加
memBufLimit的值,调整内存缓冲区大小:根据具体情况,可以增加memBufLimit的大小,以提供更多内存缓冲区空间处理更多的日志。但需要注意,增加内存缓冲区的大小可能会占用更多的内存资源,因此需要确保系统有足够的内存资源。另外可以调整存储缓冲区大小。根据告警信息,存储缓冲区大小为 128KB,可以考虑增加存储缓冲区大小,以适应更大的数据负载。调整
Buffer_Size的值,调整缓冲区大小:根据实际具体情况,适当增加Buffer_Size的大小。优化日志收集和处理过程:评估当前的日志收集和处理流程,查找可能导致日志快速增长的原因,并采取相应的措施来优化日志生成和处理速度。例如,限制日志的输出频率,对日志进行压缩或者聚合等。
调整日志处理的配置:结合实际情况,调整 Fluent Bit 的配置来更好地适应日志生成和处理需求。例如,可以使用更快的输出插件,调整日志过滤器或者解析器的配置等。
参数剖析
在 Fluent Bit(日志收集和转发工具)的场景中,memBufLmit 和 buffer_size 是两个相关但是不同的参数。
- memBufLmit(内存缓冲区限制):
memBufLimit 是 Fluent Bit 中内存缓冲区大小限制,它定义了 Fluent Bit 在内存中分配给缓冲区的最大空间,当缓冲区达到这个限制时,后续的数据将不再接受和处理。
memBufLimit 可以用来限制 Fluent Bit 处理大量日志所使用的内存大小,以防止它过度消耗系统资源,配合合理的 memBufLimit 值可以帮助确保 Fluent Bit 在接受的内存范围内运行,并避免因内存不足导致性能下降或者崩溃。
- buffer_size(缓冲区大小):
buffer_size 是 Fluent Bit 在输出插件中使用的一个参数,用于定义缓冲区的大小,缓冲区用于将日志数据暂存在内存中,以便在一次性批量处理/传输到目标存储或者服务时提高效率。
buffer_size 可以影响日志数据的传输和内存的消耗,较大的缓冲区可以减少传输的次数,提高效率,但也会占用更多的内存,较小的缓冲区可能会导致更频繁的传输,但会减少内存的消耗。根据具体情况调整缓冲区大小可以平衡传输速度和内存占用。
总结来说,在 Fluent Bit 场景中,memBufLimit 和 buffer_size 的作用如下:
memBufLimit用于限制 Fluent Bit 整体内存缓冲区的大小,以确保其在合理的内存范围内运行。buffer_size用于控制输出插件的缓冲区大小,以提高传输效率和内存消耗。
问题解决
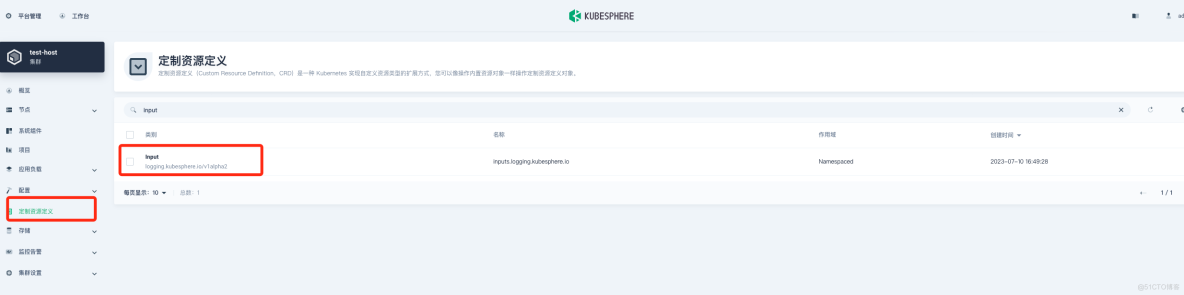
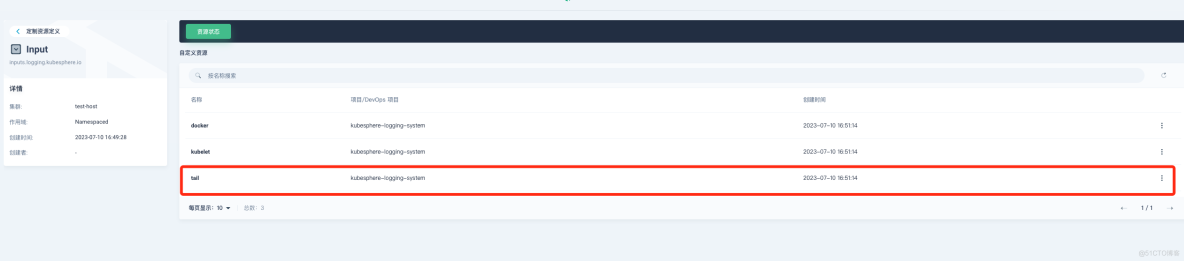
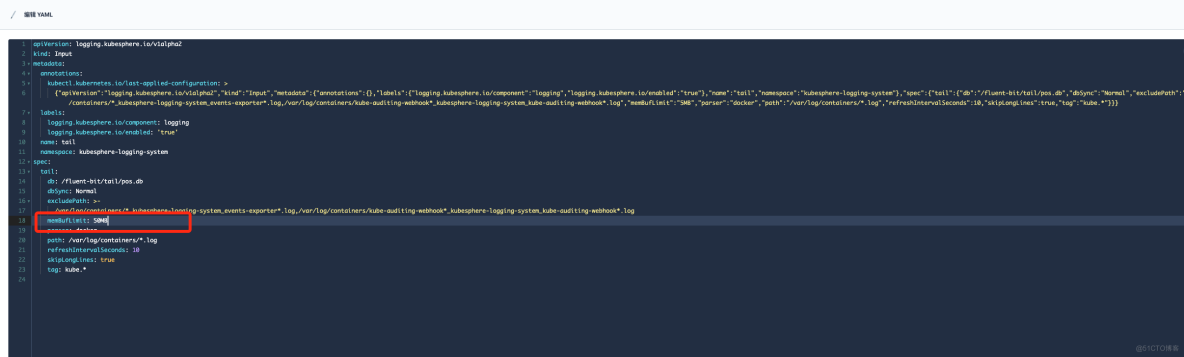
在"定制资源定义(CRD)"->input->"tail" 修改 memBufLimit 参数限制大小,可参考下图:
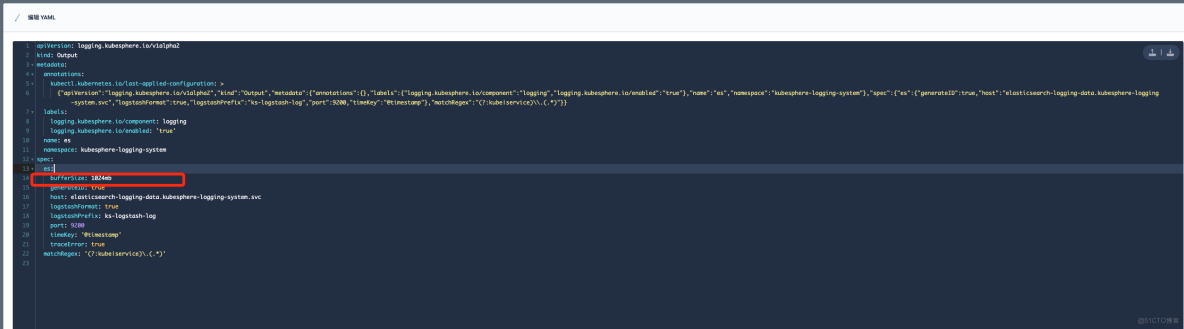
在"定制资源定义(CRD)"->Output->"es" 修改 bufferSize 参数大小,可参考下图:

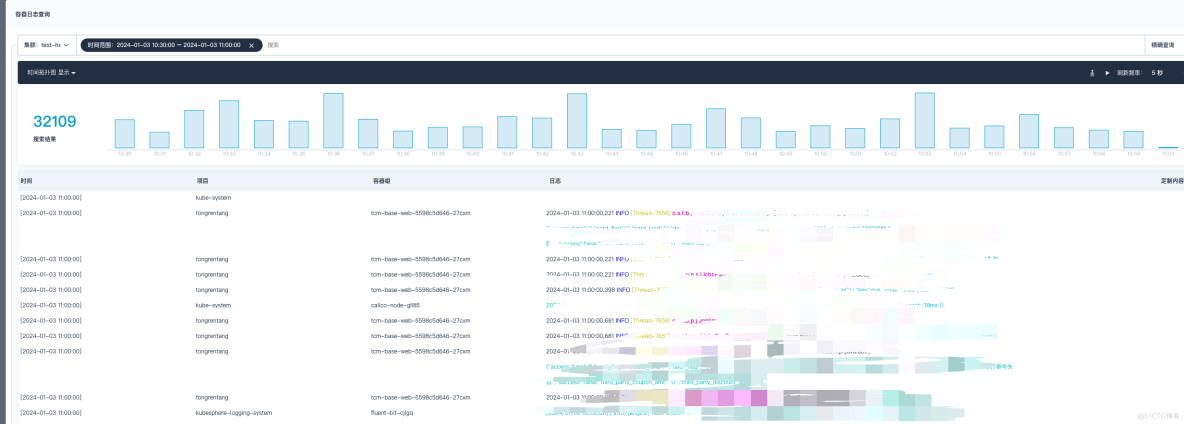
修改完毕之后,随后进行验证日志是否正常展示。参数大小一定要根据自己生产环境的配置进行调整,如果服务器节点性能配置不是很高,那么参数调整之后会严重影响业务,造成 Node 节点负载过高,本人因为这个调整被狠狠地坑过一次。下方截图是当时触发了告警,因为参数调整之后,大量的日志疯狂的刷新,导致节点流量带宽以及负载暴涨。

此时可以查看下 Fluent Bit 容器输出日志是否正常。
参考文档信息
- https://docs.fluentbit.io/manual/v/1.8/administration/buffering-and-storage
- https://docs.fluentbit.io/manual/v/1.8/administration/scheduling-and-retries
- https://docs.fluentbit.io/manual/v/1.8/pipeline/outputs/elasticsearch
- https://docs.fluentbit.io/manual/v/1.8/pipeline/filters/kubernetes
- https://docs.fluentbit.io/manual/v/1.8/pipeline/inputs/tail
本文由博客一文多发平台 OpenWrite 发布!
一次生产 KubeSphere 日志无法正常采集事件解决记录的更多相关文章
- KubeSphere 日志备份与恢复实践
为什么需要日志备份 KubeSphere 日志系统使用 Fluent Bit + ElasticSearch 的日志采集存储方案,并通过 Curator 实现对 Index 的生命周期管理,定期清理久 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- ELK实时日志分析平台环境部署--完整记录
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- ELK实时日志分析平台环境部署--完整记录(转)
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- 关于syslog日志功能详解 事件日志分析、EventLog Analyzer
关于syslog日志功能详解 事件日志分析.EventLog Analyzer 一.日志管理 保障网络安全 Windows系统日志分析 Syslog日志分析 应用程序日志分析 Windows终端服务器 ...
- paip.日志中文编码原理问题本质解决python
paip.日志中文编码原理问题本质解决python 默认的python日志编码仅仅gbk...保存utf8字符错误..输出到个eric5的控制台十默认好像十unicode的,要是有没显示出来的字符,大 ...
- mybatis用logback日志不显示sql的解决办法
mybatis用logback日志不显示sql的解决方法 1.mybatis-config.xml的设定 关于logimpl的设定值还不支持logback,如果用SLF4J是不好用的. 这是官方文档的 ...
- 日志审计系统、事件日志审计、syslog审计
日志审计系统.事件日志审计.syslog审计 任何IT机构中的Windows机器每天都会生成巨量日志数据.这些日志包含可帮助您的有用信息: · 获取位于各个Windows事件日志严重性级别的所有网络活 ...
- NetCore log4net 集成以及配置日志信息不重复显示或者记录
NetCore log4net 集成,这是一个很常见而且网上大批大批的博文了,我写这个博文主要是为了记录我在使用过程中的一点小收获,以前在使用的过程中一直没有注意但是其实网上说的不清不楚的问题. 官方 ...
- MS SqlServer 通过数据库日志文件找回已删除的记录
1.建立演示数据(创建数据库数据表添加基础数据) 1.1 创建数据库 1.2 创建数据表 1.3填充数据 1.4做数据库完整备份 2.模拟误删除.记录操作时间.备份数据库日志 2.1删除数据并记录操作 ...
随机推荐
- 【Hibernate】Re04 JPA规范使用
都忘了前面一些小前提,就是数据库需要是存在的,不过写链接参数都会写上的 JPA实现就是和Hibernate类似,也需要对应的配置文件等等... 1.配置文件必须命名[persistence.xml]且 ...
- 元学习:元学习的始祖论文——《On the Optimization of a Synaptic Learning Rule》
============================================= 这个论文保持着上世纪人工智能论文的特点,与其说是计算机类论文更不如说是偏生物科学方面的论文,这也可能是因为当 ...
- 2023.4.12.汇报.pptx
6月份汇报想法 8月份写论文 ==========================================================
- python语言绘图:绘制一组以beta分布为先验,以二项分布为似然的贝叶斯后验分布图
代码源自: https://github.com/PacktPublishing/Bayesian-Analysis-with-Python ============================= ...
- js 实现俄罗斯方块(一)
上学的时候就想尝试写个游戏了,不过那时一直想的都是些不太切合自身能力的高级游戏(需要花很多时间学习引擎,需要美工等等)最终都没有实现. 最近突然又想写了就利用业余时间写了个俄罗斯方块js写的画面也比较 ...
- 代码随想录Day12
二叉树遍历 分为前序.中序.后续.层序四种 其中前中后序属于深度优先搜索,层序属于广度优先搜索 前序遍历顺序: 根节点->左子树->右子树 中序遍历顺序: 左子树->根节点-> ...
- C#读写图片文件到Access数据库中
今天学习了把图片文件读写到数据库中,我是用的Access数据库,SQL还没去测试,不过都差不多 数据库表的样式 练习嘛就随便弄了下,说明下图片转成的字符串要用备注类型才可以哦 如果用的Sql数据库的话 ...
- LaTeX 插入表格
普通表格 \begin{table}[h] % h: here \begin{center} % 一个字母代表一列 \begin{tabular}{|c|cccc|} % c: center, l: ...
- linux修改limits.conf不生效
正常情况下, /etc/security/limits.conf 的改动,重新登录就可以生效, 我遇到的问题最后的解决方案是重启虚拟机解决了,也参考了很多网上的文章,整理记录一下 一.修改方法 1.临 ...
- rpm -Uvh *.rpm --nodeps --force
rpm -Uvh *.rpm --nodeps --force 含义:-U:升级软件,若未软件尚未安装,则安装软件.-v:表示显示详细信息.-h:以"#"号显示安装进度.--for ...