SQL 优化 - 多层嵌套逻辑先行
近段时间就是忙得不亦乐乎, 一个人搞项目, 中途几经崩溃, 一个是业务方案有问题, 被带跑偏了整整一周, 最后尝试去挑战, 才重新回到正轨. 然后就是自己搞崩盘, sql 这块的处理, 嵌套写太深了, sql 有问题了, 各种查询不出来, 但也不报异常... 无奈之下, 只能全部重写, 果然吃了没有写大 sql 的亏, 这里就是想记录一把, 反例 sql , 引以为鉴. 就是各种嵌套, 然后可读性极差, 自己都维护不了那种.
因为涉及安全问题, 字段, 逻辑, 背景啥的都进行脱敏了, 截取了一段 sql 的匹配逻辑来说明这个问题.
需求
就是对一个前期处理好的表, 进行匹配其他维度信息, 然后又多个匹配表, 多次匹配, 且有顺序, 大致是这样的.
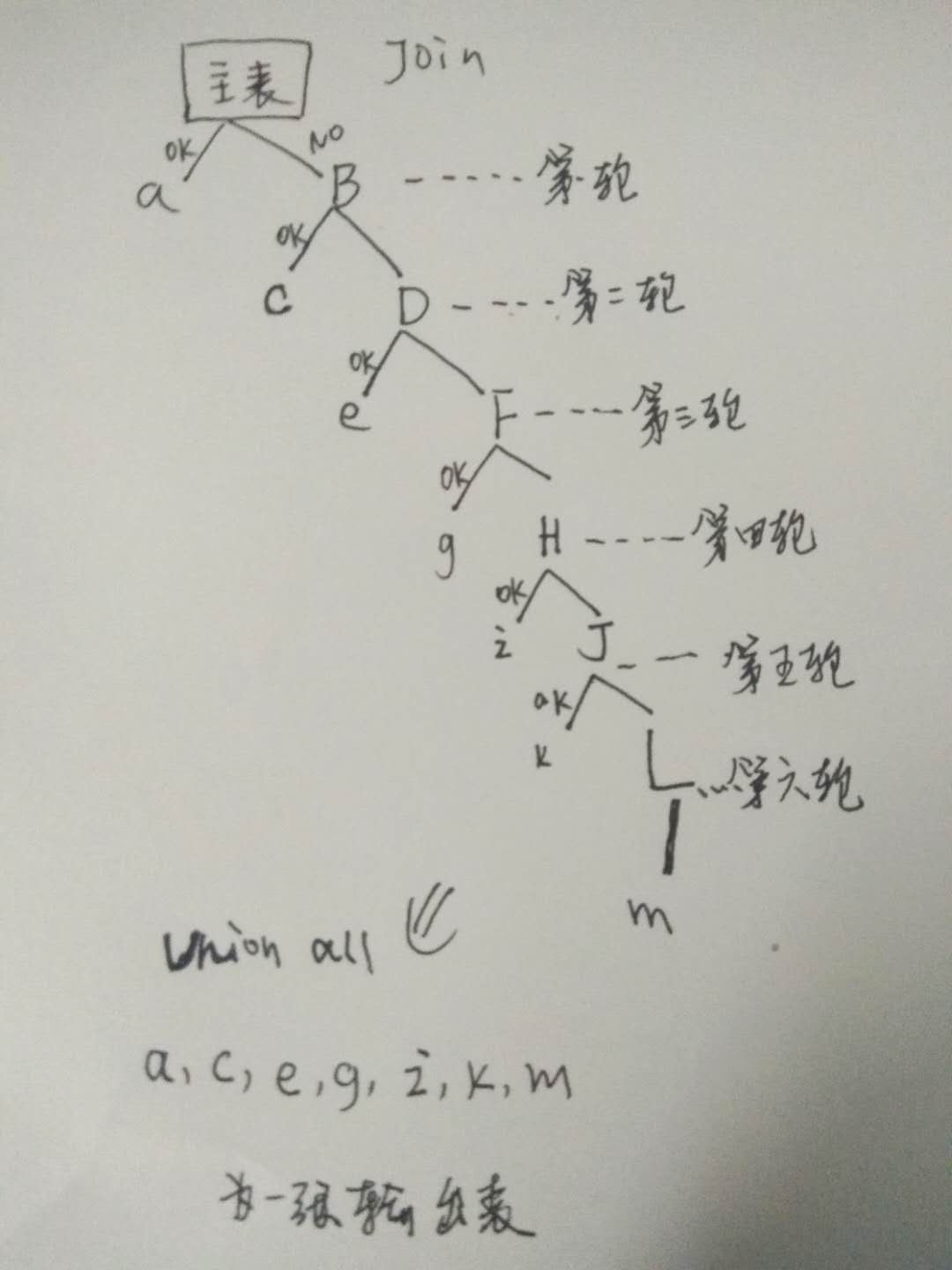
缺失的信息,要从我处理好的 6 个视图去做关联, 匹配出对应的字段信息, 当然, 条件是不同的, 有次序. 这在业务是会经常出现, 老是说, 先从这里找.. 找不到的再从另外找....这样几轮的匹配下去... 如图, 我还是简化了的, 就只有两种情况, 匹配上, 和没匹配上的情况, 这样不断查询.
优化前
真的是缺乏经验, 但是我又强大的逻辑, 就直接一个 大 sql 给拼了出来. 原理就是, 匹配上的, 即 inner join 嘛, 匹不上的就 做 left join 后, 再 where 出 右表为 null 的那些 左表的部分... 不断循环此过程. 最后, 将查询集存为物理表.
然后我就哐哐哐, 写了一段, 神仙一般的 反例sql, 有点 "惊为天人", 然后贻笑大方了.
------------ 优化前 ------------------------------------
-- 之前在列数据库写的套娃, 各种嵌套, 崩溃 IQ
-- 用一段代码逻辑, 将所有的结果拼接起来, 查询集存为一个物理表
select
*
into cj_main
from (
-- ------------------------------------------main----------------------------------
-- 查询集, 6 轮匹配, 不断 union all
-- 查询的表,都是一个个有逻辑的视图哦, 字段都用 '*', 所有字段都要, 简化书写
select
a.*,
b.*
-- 内连接第1个视图
from cj_tmp_main as a, cj_view_01 as b
where upper(a.pp_name + country) = upper(b.foo_key)
-- 第二轮匹配, 基于第一轮匹不上的
union all
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
-- 内连接第2个视图
, cj_view_02 as d
where upper(c.ppp_name + country) = upper(d.foo_key)
union all
-- 第三轮匹配, 基于前两轮
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
-- 挑出没披上的
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
-- 内连接第3个视图
, cj_view_03 as f
where upper(e.pp_name + country) = upper(f.foo_key)
-- e 的 country 能 在 f 的 country, 值(aaa,bbbb,ccc) 中出现过哦, 没出现则索返回 0
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
union all
-- 第四轮匹配, 基于前三轮
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
-- 内连接第 4 个视图
, cj_view_04 as h
where upper(g.pp_key) = upper(h.foo_key)
union all
-- 第五轮匹配, 基于前4轮
select
i.*,
j.*
from (
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
-- 挑出没匹上的
left join cj_view_04 as h
on upper(g.pp_key) = upper(h.foo_key)
where h.foo_key is null
) as i
-- 内连接第 5 个视图
, cj_view_05 as j
where upper(i.foo_key + country) = upper(j.foo_key)
union all
-- 第六轮, 剩余的都是没有匹配上, 则再关联一个维表补充信息
select
k.*,
l.*
from (
select
i.*,
j.*
from (
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + e.country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
left join cj_view_04 as h
on upper(g.pp_key) = upper(h.foo_key)
where h.foo_key is null
) as i
-- 挑出 5轮都没有匹上的顽固兄弟
left join cj_view_05 as j
on upper(i.foo_key + i.country) = upper(j.foo_key)
where j.foo_key is null
) as k
-- 最后的匹配
left join cj_view_06 as l
on upper(k.pp_key) = l.foo_key
-- -------------------------------------main -------------------------
) as m
脱敏处理了一下哈, 也就示意一下, 不能透露过多细节呢. 我发现, 我现在经常喜欢这样写 sql, 又长, 又很多嵌套, 又不好维护, 自己都看不懂, 隔了一段时间. 结果, 测试准备上线的时候, 就突然崩了了, 也不知道是哪一段逻辑的问题...... 这时候才想到了 sql 优化. 我觉得, 优化, 首先是要在逻辑上, 在算法上优先, 而不是那些, 什么鬼写法啥的....
逻辑优化
我很快想了一下, 首先从功能上讲, 要对主表, 不断进行 vlookup 嘛. 然后就想到编程思维了, 还好有强大的编程思维支持着我. 这就是要做 逻辑拆分嘛.
先建一个 目标空表, 拆分为几段逻辑, 分别插入即可, 用主表跟我的 6个视图, 分别做 Join, 下一次数据, 基于与当前主表id 互斥. 这样一下就从逻辑上解决了我的问题. 优化如下:
-- ---------------------- 优化版 --------------------------
-- 逻辑上优化, 先建一个结果表, 分部分, 不断往里面插数据即可.
drop table if exists cj_target_main;
create table cj_target_main (
id int identity,
aa varchar(1000) null,
bb varchar(1000) null,
cc varchar(1000) null,
.....
);
-- 分为 6 部分插入, 在视图的部分, 已经事先将字段对齐了~
-- 主表 跟 匹配表 依次连接 6 次, 每次的 动态过滤 id
-- ------------------------第1段插入-----------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_01 as b
where upper(a.pp_name + country) = upper(b.foo_key)
) as m
-- -------------------------第2段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_02 as b
where upper(a.pp_name + country) = upper(b.foo_key)
-- 这里最关键, 写出了编程思思哦..
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第3段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_03 as b
where upper(a.pp_name + country) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
and charindex(a.contry, b.country) != 0
and b.cj_flag = 'N'
) as m
-- -------------------------第4段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_04 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第5段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_05 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第6段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_06 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
这样就将多层嵌套逻辑, 稍稍修改了下, 就简单很多了. 当然, 视图很关键, 这里还用 * 了嘛, 在那些视图, 字段啥的我都是已经筛选和处理了, 分担了大部分的逻辑, 这里是主逻辑调用. 如此一来, 就将 sql 写出了, 函数式编程的感觉, 也算是我做一个比较成功的 sql 优化. 优化在处理逻辑上, 而非语句分析上, 是从整体上来优化这个过程呢. 毕竟是自己挖的坑, 也只能自己来填上呀.
小结
- sql 多层嵌套, 性能差, 可读性差, 就很难维护, 尽量要做到原子化一点
- 优化上, 优先考虑整体逻辑, 如分治法, 临时表, 中间表, 再去思考写法啥的
- 唯有多写和不断入坑, 填坑, 才会有真正的经验积累, 所谓经验, 都是采坑过来的
世界上本没有经验, 只是踩的坑多了, 便积累成了经验.
SQL 优化 - 多层嵌套逻辑先行的更多相关文章
- mysql SQL优化之嵌套查询-遁地龙卷风
(-1) 写在前面 这篇随笔的数据使用的是http://blog.csdn.net/friendan/article/details/8072668#comments里的,里面有一些常见的select ...
- MySQL中的sql优化
目标: 掌握SQL调优的原则 掌握SQL调优的基本逻辑 掌握优秀SQL的编写方案 掌握何为慢SQL以及检测方案 SQL优化原则 1.减少数据量(表中数据太多可以分表,例如超过500万数据 双11一个 ...
- MySQL(逻辑分层,存储引擎,sql优化,索引优化以及底层实现(B+Tree))
一 , 逻辑分层 连接层:连接与线程处理,这一层并不是MySQL独有,一般的基于C/S架构的都有类似组件,比如连接处理.授权认证.安全等. 服务层:包括缓存查询.解析器.优化器,这一部分是MySQL核 ...
- SQL优化注意事项
sql语句优化 性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的 ...
- SQL 优化,全
性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的SQL语句,要设 ...
- sql优化的50中方法
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化 ...
- 浅谈sql优化
问题的发现: 菜鸟D在工作的时候发现项目的sql语句很怪,例如 : select a.L_ZTBH, a.D_RQ, a.VC_BKDM, (select t.vc_name from tb ...
- mysql系列十一、mysql优化笔记:表设计、sql优化、配置优化
可以从这些方面进行优化: 数据库(表)设计合理 SQL语句优化 数据库配置优化 系统层.硬件层优化 数据库设计 关系数据库三范式 1NF:字段不可分; 2NF:有主键,非主键字段依赖主键; 3NF:非 ...
- MySQL优化(二):SQL优化
一.SQL优化 1.优化SQL一般步骤 1.1 查看SQL执行频率 SHOW STATUS LIKE 'Com_%'; Com_select:执行SELECT操作的次数,一次查询累加1.其他类似 以下 ...
- SQL优化的若干原则
SQL语句:是对数据库(数据)进行操作的惟一途径:消耗了70%~90%的数据库资源:独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低:可以有不同的写法:易 ...
随机推荐
- JAVA基础环境配置指南(简洁版)
1.安装JDK 官网下载后直接安装 配置环境变量: 添加 JAVA_HOME 变量名:JAVA_HOME 变量值:C:\Program Files (x86)\Java\jdk1.8.0_91 // ...
- 『Python底层原理』--CPython的变量实现机制
在Python中,变量的使用看起来非常简单,例如 a = 10,s = "hello"等等. 然而,这种简单的赋值操作背后,CPython其实做了很多复杂的工作. 本文将通过一些简 ...
- 【Unity】投影矩阵和线性深度推导
[Unity]投影矩阵和线性深度推导 网络上有很多投影矩阵的推导,也有很多声称是基于 Unity 的,但和我的实测都不一致(现在看来是因为这些文章并不全面),此外有一些 Unity 本身的函数我也搞不 ...
- gdfs: 基于Fuse的GoogleDrive客户端开源代码分析
背景 在学习fuse的过程中,首先从libfuse中的demo开始学习,以了解用户态与内核态通信的框架.而此处的demo只聚焦于最基本的通信,用户态文件系统的实现只是一个最简单的read only文件 ...
- AngleSharp :在 C# 中轻松解析和操作 HTML/XML 文档
AngleSharp 是一个 C# 库,主要用于解析和操作 HTML 和 XML 文档,类似于浏览器的 DOM 操作.允许你在 C# 中使用类似浏览器的方式处理网页数据,进行网页抓取.数据提取和处理等 ...
- try except 案例
def to_split(df): # 删除不符合加班统计的记录 try: df.dropna(subset=['姓名'], inplace=True) hang_index = df[df['加班信 ...
- Window10永久暂停(禁用)自动更新
终于彻底设置window10不自动更新了(禁用自动更新) 设置成功后的标识 设置成功后,重启电脑再打开就会显示这样的,这个才是禁用成功的标识: 之前安装了window 10 ,但是window 10 ...
- Shell脚本实现服务器多台免密
简介 本脚本(auto_ssh_batch.sh)用于在多台主机之间快速配置SSH免密登录,并支持远程传输脚本/文件及执行命令.通过 pass 文件提供统一认证凭据,通过 nodes 文件定义目标主机 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 31 期(2025年3.17-3.23)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- 导入SpaceClaim的iges模型尺寸被放大1000倍的问题
问题 ANSYS APDL 和 Workbench 联合仿真时,导入 SpaceClaim 的 .iges 模型尺寸被放大 1000 倍数. 如 APDL 生成的尺寸为 10 mm(注:此处的 mm ...