IM消息ID技术专题(六):深度解密滴滴的高性能ID生成器(Tinyid)
1、引言
在中大型IM系统中,聊天消息的唯一ID生成策略是个很重要的技术点。不夸张的说,聊天消息ID贯穿了整个聊天生命周期的几乎每一个算法、逻辑和过程,ID生成策略的好坏有可能直接决定系统在某些技术点上的设计难易度。
有中小型IM场景下,消息ID可以简单处理,反正只要唯一就行,而中大型场景下,因为要考虑到分布式的性能、一致性等,所以要考虑的问题点又是另一回事。
总之就是,IM的消息ID生成这件事,可深可浅,看似简单但实际可探索的边界可以很大,这也是为什么即时通讯网为此专门整理了《IM消息ID技术专题》系列文章的原因。做技术所谓厚积薄发,了解的越多,你的技术可操作空间也就越大,希望随着这个系列文章的阅读,可以为你在ID生成这一块的技术选型带来更多有益的启发。
另外,因为即时通讯网主要关注的是即时通讯方面的系统开发,但并不意味着这个系统文章只适用于IM或消息推送等实时通信系统,它同样适用于其它需要唯一ID的应用中。
本文将要分享的是滴滴开源的分布式ID生成器Tinyid的技术原理、使用方法等等,希望能进一步为你打开这方面的技术视野。
学习交流:
- 即时通讯/推送技术开发交流5群:215477170[推荐]
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
- 开源IM框架源码:https://github.com/JackJiang2011/MobileIMSDK
(本文同步发布于:http://www.52im.net/thread-3129-1-1.html)
2、专题目录
本文是“IM消息ID技术专题”系列文章的第6篇,专题总目录如下:
《IM消息ID技术专题(一):微信的海量IM聊天消息序列号生成实践(算法原理篇)》
《IM消息ID技术专题(二):微信的海量IM聊天消息序列号生成实践(容灾方案篇)》
《IM消息ID技术专题(三):解密融云IM产品的聊天消息ID生成策略》
《IM消息ID技术专题(四):深度解密美团的分布式ID生成算法》
3、什么是Tinyid?
Tinyid是滴滴用Java开发的一款分布式id生成系统,基于数据库号段算法实现。
Tinyid是在美团的ID生成算法Leaf的基础上扩展而来,支持数据库多主节点模式,它提供了REST API和Java客户端两种获取方式,相对来说使用更方便。不过,和美团的Leaf算法不同的是,Tinyid只支持号段一种模式(并不支持Snowflake模式)。(有关美团的Leaf算法,可以详读《IM消息ID技术专题(四):深度解密美团的分布式ID生成算法》)
Tinyid目前在滴滴客服部门使用,且通过tinyid-client方式接入,每天生成的是亿级别的id。性能上,据称单实例能达到1千万QPS。
它的开源地址是:
PS:滴滴在Tinyid工程页面写了一句话,“tinyid,并不是滴滴官方产品,只是滴滴拥有的代码”,我语文不好,这句该怎么理解呢?
4、Tinyid的主要技术特性
主要特性总结一下就是:
- 1)全局唯一的long型ID:即id极限数量是2的64次方;
- 2)趋势递增的id:趋势递增的意思是,id是递增但不一定是连续的(这跟微信的ID生成策略类似);
- 3)提供 http 和 java-client 方式接入;
- 4)支持批量获取ID;
- 5)支持生成1,3,5,7,9…序列的ID;
- 6)支持多个db的配置。
适用的场景:只关心ID是数字,趋势递增的系统,可以容忍ID不连续,可以容忍ID的浪费。
不适用场景:像类似于订单ID的业务,因生成的ID大部分是连续的,容易被扫库、或者推算出订单量等信息。
另外:微信的聊天消息ID生成算法也是基于号段、趋势递增这种逻辑,如果有兴趣,可以详见:《IM消息ID技术专题(一):微信的海量IM聊天消息序列号生成实践(算法原理篇)》。
5、Tinyid的技术优势
性能方面:
- 1)http方式:访问性能取决于http server的能力,网络传输速度;
- 2)java-client方式:id为本地生成,号段长度(step)越长,qps越大,如果将号段设置足够大,则qps可达1000w+。
可用性方面:
- 1)当db不可用时,因为server有缓存,所以还可以使用一段时间;
- 2)如果配置了多个db,则只要有1个db存活,则服务可用;
- 3)使用tiny-client时,只要server有一台存活,则理论上server全挂,因为client有缓存,也可以继续使用一段时间。
6、Tinyid的技术原理详解
6.1 ID生成系统的技术要点
在简单系统中,我们常常使用db的id自增方式来标识和保存数据,随着系统的复杂,数据的增多,分库分表成为了常见的方案,db自增已无法满足要求。
这时候全局唯一的id生成系统就派上了用场,当然这只是id生成其中的一种应用场景。
那么,一个成熟的id生成系统应该具备哪些能力呢?
- 1)唯一性:无论怎样都不能重复,id全局唯一是最基本的要求;
- 2)高性能:基础服务尽可能耗时少,如果能够本地生成最好;
- 3)高可用:虽说很难实现100%的可用性,但是也要无限接近于100%的可用性;
- 4)易用性:能够拿来即用,接入方便,同时在系统设计和实现上要尽可能的简单。
6.2 Tinyid的实现原理
我们先来看一下最常见的id生成方式,db的auto_increment,相信大家都非常熟悉。
我也见过一些同学在实战中使用这种方案来获取一个id,这个方案的优点是简单,缺点是每次只能向db获取一个id,性能比较差,对db访问比较频繁,db的压力会比较大。
那么,是不是可以对这种方案优化一下呢?可否一次向db获取一批id呢?答案当然是可以的。
一批id,我们可以看成是一个id范围,例如(1000,2000],这个1000到2000也可以称为一个“号段”,我们一次向db申请一个号段,加载到内存中,然后采用自增的方式来生成id,这个号段用完后,再次向db申请一个新的号段,这样对db的压力就减轻了很多,同时内存中直接生成id,性能则提高了很多。
PS:简单解释一下什么是号段模式:
号段模式就是从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存。
那么保存db号段的表该怎设计呢?我们继续往下看。
6.3 DB号段算法描述

如上表,我们很容易想到的是db直接存储一个范围(start_id,end_id],当这批id使用完毕后,我们做一次update操作,update start_id=2000(end_id), end_id=3000(end_id+1000),update成功了,则说明获取到了下一个id范围。仔细想想,实际上start_id并没有起什么作用,新的号段总是(end_id,end_id+1000]。
所以这里我们更改一下,db设计应该是这样的:

如上表所示:
- 1)我们增加了biz_type,这个代表业务类型,不同的业务的id隔离;
- 2)max_id则是上面的end_id了,代表当前最大的可用id;
- 3)step代表号段的长度,可以根据每个业务的qps来设置一个合理的长度;
- 4)version是一个乐观锁,每次更新都加上version,能够保证并发更新的正确性 。
那么我们可以通过如下几个步骤来获取一个可用的号段:
A、查询当前的max_id信息:select id, biz_type, max_id, step, version from tiny_id_info where biz_type='test';
B、计算新的max_id: new_max_id = max_id + step;
C、更新DB中的max_id:update tiny_id_info set max_id=#{new_max_id} , verison=version+1 where id=#{id} and max_id=#{max_id} and version=#{version};
D、如果更新成功,则可用号段获取成功,新的可用号段为(max_id, new_max_id];
E、如果更新失败,则号段可能被其他线程获取,回到步骤A,进行重试。
6.4 号段生成方案的简单架构
如上述内容,我们已经完成了号段生成逻辑。
那么我们的id生成服务架构可能是这样的:
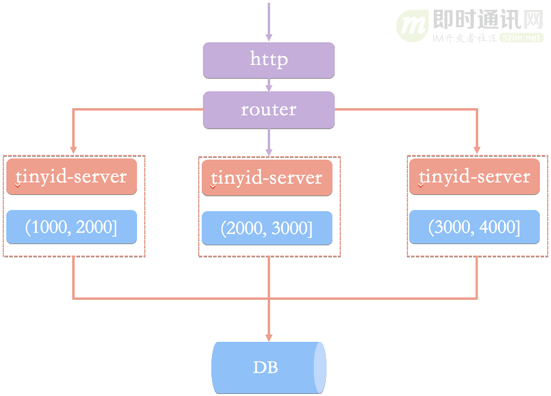
如上图,id生成系统向外提供http服务,请求经过我们的负载均衡router,到达其中一台tinyid-server,从事先加载好的号段中获取一个id。
如果号段还没有加载,或者已经用完,则向db再申请一个新的可用号段,多台server之间因为号段生成算法的原子性,而保证每台server上的可用号段不重,从而使id生成不重。
可以看到:
- 1)如果tinyid-server如果重启了,那么号段就作废了,会浪费一部分id;
- 2)同时id也不会连续;
- 3)每次请求可能会打到不同的机器上,id也不是单调递增的,而是趋势递增的(不过这对于大部分业务都是可接受的)。
6.5 简单架构的问题
到此一个简单的id生成系统就完成了,那么是否还存在问题呢?
回想一下我们最开始的id生成系统要求:高性能、高可用、简单易用。
在上面这套架构里,至少还存在以下问题:
- 1)当id用完时需要访问db加载新的号段,db更新也可能存在version冲突,此时id生成耗时明显增加;
- 2)db是一个单点,虽然db可以建设主从等高可用架构,但始终是一个单点;
- 3)使用http方式获取一个id,存在网络开销,性能和可用性都不太好。
6.6 优化办法及最终架构
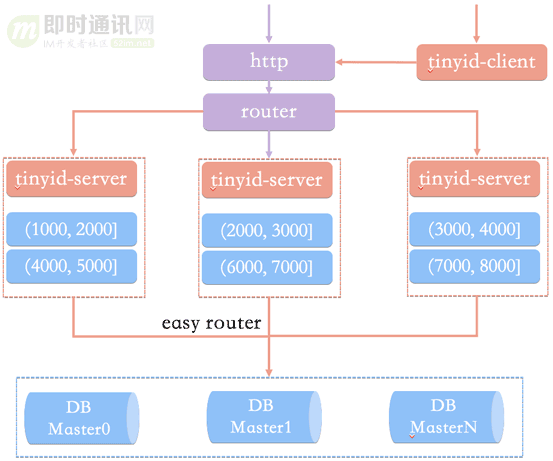
1)双号段缓存:
对于号段用完需要访问db,我们很容易想到在号段用到一定程度的时候,就去异步加载下一个号段,保证内存中始终有可用号段,则可避免性能波动。
2)增加多db支持:
db只有一个master时,如果db不可用(down掉或者主从延迟比较大),则获取号段不可用。实际上我们可以支持多个db,比如2个db,A和B,我们获取号段可以随机从其中一台上获取。那么如果A,B都获取到了同一号段,我们怎么保证生成的id不重呢?tinyid是这么做的,让A只生成偶数id,B只生产奇数id,对应的db设计增加了两个字段,如下所示

delta代表id每次的增量,remainder代表余数,例如可以将A,B都delta都设置2,remainder分别设置为0,1则,A的号段只生成偶数号段,B是奇数号段。通过delta和remainder两个字段我们可以根据使用方的需求灵活设计db个数,同时也可以为使用方提供只生产类似奇数的id序列。
3)增加tinyid-client:
使用http获取一个id,存在网络开销,是否可以本地生成id?
为此我们提供了tinyid-client,我们可以向tinyid-server发送请求来获取可用号段,之后在本地构建双号段、id生成,如此id生成则变成纯本地操作,性能大大提升,因为本地有双号段缓存,则可以容忍tinyid-server一段时间的down掉,可用性也有了比较大的提升。
4)tinyid最终架构:
最终我们的架构可能是这样的:
下面是更具体的代码调用逻辑:
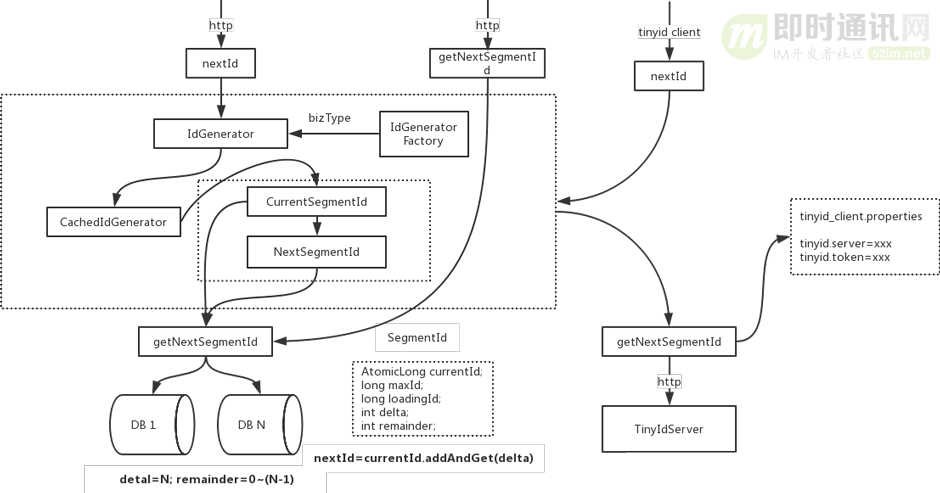
如上图所示,下面是关于这个代码调用逻辑图的说明:
- 1)nextId和getNextSegmentId是tinyid-server对外提供的两个http接口;
- 2)nextId是获取下一个id,当调用nextId时,会传入bizType,每个bizType的id数据是隔离的,生成id会使用该bizType类型生成的IdGenerator;
- 3)getNextSegmentId是获取下一个可用号段,tinyid-client会通过此接口来获取可用号段;
- 4)IdGenerator是id生成的接口;
- 5)IdGeneratorFactory是生产具体IdGenerator的工厂,每个biz_type生成一个IdGenerator实例。通过工厂,我们可以随时在db中新增biz_type,而不用重启服务;
- 6)IdGeneratorFactory实际上有两个子类IdGeneratorFactoryServer和IdGeneratorFactoryClient,区别在于,getNextSegmentId的不同,一个是DbGet,一个是HttpGet;
- 7)CachedIdGenerator则是具体的id生成器对象,持有currentSegmentId和nextSegmentId对象,负责nextId的核心流程。nextId最终通过AtomicLong.andAndGet(delta)方法产生。
具体的代码实现,有兴趣可以直接阅读源码:
7、Tinyid的最佳实践
1)tinyid-server推荐部署到多个机房的多台机器:
多机房部署可用性更高,http方式访问需使用方考虑延迟问题。
2)推荐使用tinyid-client来获取id,好处如下:
a、id为本地生成(调用AtomicLong.addAndGet方法),性能大大增加;
b、client对server访问变的低频,减轻了server的压力;
c、因为低频,即便client使用方和server不在一个机房,也无须担心延迟;
d、即便所有server挂掉,因为client预加载了号段,依然可以继续使用一段时间
注:使用tinyid-client方式,如果client机器较多频繁重启,可能会浪费较多的id,这时可以考虑使用http方式。
3)推荐db配置两个或更多:
db配置多个时,只要有1个db存活,则服务可用 多db配置,如配置了两个db,则每次新增业务需在两个db中都写入相关数据。
8、Tinyid该怎么调用?
关于怎么调用。鉴于篇幅原因,就不再具体去写了,有兴趣的话,可以读一下这篇《Tinyid:滴滴开源千万级并发的分布式ID生成器》。
9、参考资料
[1] 面试总被问分布式ID怎么办? 滴滴(Tinyid)甩给他
[3] tinyid工程中文readme
附录:更多IM开发热门技术文章
《移动端IM开发者必读(一):通俗易懂,理解移动网络的“弱”和“慢”》
《移动端IM开发者必读(二):史上最全移动弱网络优化方法总结》
《现代移动端网络短连接的优化手段总结:请求速度、弱网适应、安全保障》
《IM消息送达保证机制实现(一):保证在线实时消息的可靠投递》
《自已开发IM有那么难吗?手把手教你自撸一个Andriod版简易IM (有源码)》
《IM开发基础知识补课(六):数据库用NoSQL还是SQL?读这篇就够了!》
《适合新手:从零开发一个IM服务端(基于Netty,有完整源码)》
《适合新手:手把手教你用Go快速搭建高性能、可扩展的IM系统(有源码)》
《IM里“附近的人”功能实现原理是什么?如何高效率地实现它?》
《IM开发基础知识补课(七):主流移动端账号登录方式的原理及设计思路》
《IM开发宝典:史上最全,微信各种功能参数和逻辑规则资料汇总》
《IM开发干货分享:我是如何解决大量离线消息导致客户端卡顿的》
《IM开发干货分享:有赞移动端IM的组件化SDK架构设计实践》
>> 更多同类文章 ……
本文已同步发布于“即时通讯技术圈”公众号,欢迎关注:

▲ 本文在公众号上的链接是:点此进入,原文链接是:http://www.52im.net/thread-3129-1-1.html
IM消息ID技术专题(六):深度解密滴滴的高性能ID生成器(Tinyid)的更多相关文章
- 美团技术分享:深度解密美团的分布式ID生成算法
本文来自美团技术团队“照东”的分享,原题<Leaf——美团点评分布式ID生成系统>,收录时有勘误.修订并重新排版,感谢原作者的分享. 1.引言 鉴于IM系统中聊天消息ID生成算法和生成策略 ...
- 🏆【Alibaba中间件技术系列】「RocketMQ技术专题」系统服务底层原理以及高性能存储设计分析
设计背景 消息中间件的本身定义来考虑,应该尽量减少对于外部第三方中间件的依赖.一般来说依赖的外部系统越多,也会使得本身的设计越复杂,采用文件系统作为消息存储的方式. RocketMQ存储机制 消息中间 ...
- 不为人知的网络编程(八):从数据传输层深度解密HTTP
1.引言 在文章<理论联系实际:Wireshark抓包分析TCP 3次握手.4次挥手过程>中,我们学会了用wireshark来分析TCP的“三次握手,四次挥手”,非常好用.这就是传说中的锤 ...
- 深度解密Go语言之channel
目录 并发模型 并发与并行 什么是 CSP 什么是 channel channel 实现 CSP 为什么要 channel channel 实现原理 数据结构 创建 接收 发送 关闭 channel ...
- 深度解密Go语言之反射
目录 什么是反射 为什么要用反射 反射是如何实现的 types 和 interface 反射的基本函数 反射的三大定律 反射相关函数的使用 代码样例 未导出成员 反射的实际应用 json 序列化 De ...
- 技术专题-PHP代码审计
作者:坏蛋链接:https://zhuanlan.zhihu.com/p/24472674来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 一.前言 php代码审计如字面 ...
- Windows消息拦截技术的应用
Windows消息拦截技术的应用 民航合肥空管中心 周毅 一.前 言 众所周知,Windows程式的运行是依靠发生的事件来驱动.换句话说,程式不断等待一个消息的发生,然后对这个消息的类型进行判断,再做 ...
- Windows消息拦截技术的应用(作者博客里有许多相关文章)
民航合肥空管中心 周毅 一.前 言 众所周知,Windows程式的运行是依靠发生的事件来驱动.换句话说,程式不断等待一个消息的发生,然后对这个消息的类型进行判断,再做适当的处理.处理完此次消息后又回到 ...
- JAVA技术专题综述之线程篇(1)
本文详细介绍JAVA技术专题综述之线程篇 编写具有多线程能力的程序经常会用到的方法有: run(),start(),wait(),notify(),notifyAll(),sleep(),yield( ...
- Azure Messaging-ServiceBus Messaging消息队列技术系列3-消息顺序保证
上一篇:Window Azure ServiceBus Messaging消息队列技术系列2-编程SDK入门 http://www.cnblogs.com/tianqing/p/5944573.ht ...
随机推荐
- 云原生爱好者周刊:VMware Tanzu 社区办发布,无任何限制!
云原生一周动态要闻: VMware Tanzu 推出社区版 Kubernetes Cluster API 1.0 版已生产就绪 Linkerd 2.11 发布 Cartografos 工作组推出云原生 ...
- 修复 K8s SSL/TLS 漏洞(CVE-2016-2183)指南
前言 测试服务器配置 主机名 IP CPU 内存 系统盘 数据盘 用途 zdeops-master 192.168.9.9 2 4 40 200 Ansible 运维控制节点 ks-k8s-maste ...
- IO体系
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件.管道.网络连接. Java 中是通过流处理IO 的,那么什么是流? 流(Stream),是一个抽象的 ...
- Games 101 作业1
1 坐标系 关于坐标系,坐标系其实就是空间信息.有了坐标系我们可以非常详细的描述这个世界,为了方便一般为一个观测者生成一个坐标系. 坐标系以观测者所在的位置为原点.就像我们常说的前面三米,我们对世界的 ...
- SpreadJS 在数据填充时的公式填充方案
需求介绍 很多用户使用了 SpreadJS 的数据填报功能.大致用法为:设计模板,填充数据源.在这个过程中,可能会出现模板中设置了公式,而在数据源填充时,公式没有携带下来的问题. 比如我们定义一个模板 ...
- 关于MNN工程框架编译出来的静态库和动态库的使用
一.MNN.lib文件路径 如果你看过之前的博客内容,应该可以在编译的的工程当中 C:\Users\Administrator\Desktop\MNN\MNN-master\MNN-CPU-OPENC ...
- linux history 想显示历史命令的时间和作者
vi ~/.profile 增加 HISTTIMEFORMAT="%F %T `whoami` `who am i|awk '{print $1,$5}'|sed 's/ (/@/'|sed ...
- Python基础:Python可变对象和不可变对象
Python在heap中分配的对象分成两类:可变对象和不可变对象.所谓可变对象是指,对象的内容是可变的,例如list.而不可变的对象则相反,表示其内容不可变. 不可变对象:int,string,flo ...
- 解码OutOfMemoryError:PermGen Space
本文由 ImportNew - Peter Pan 翻译自 javacodegeeks.如需转载本文,请先参见文章末尾处的转载要求. ImportNew注:如果你也对Java技术翻译分享感兴趣,欢迎加 ...
- seldom-platform颠覆传统的自动化测试平台
1. 传统的自动化测试平台 近些年,中等以上规模的公司测试团队都在建设自己的自动化测试平台.主要要以 HTTP接口测试 和 性能测试 为主:一些平台还支持 Web UI测试和App UI测试等,试图通 ...