vmstorage如何将原始指标转换为有组织的历史
vmstorage如何将原始指标转换为有组织的历史
vmstorage是VictoriaMetrics中负责处理长期存储的组件。
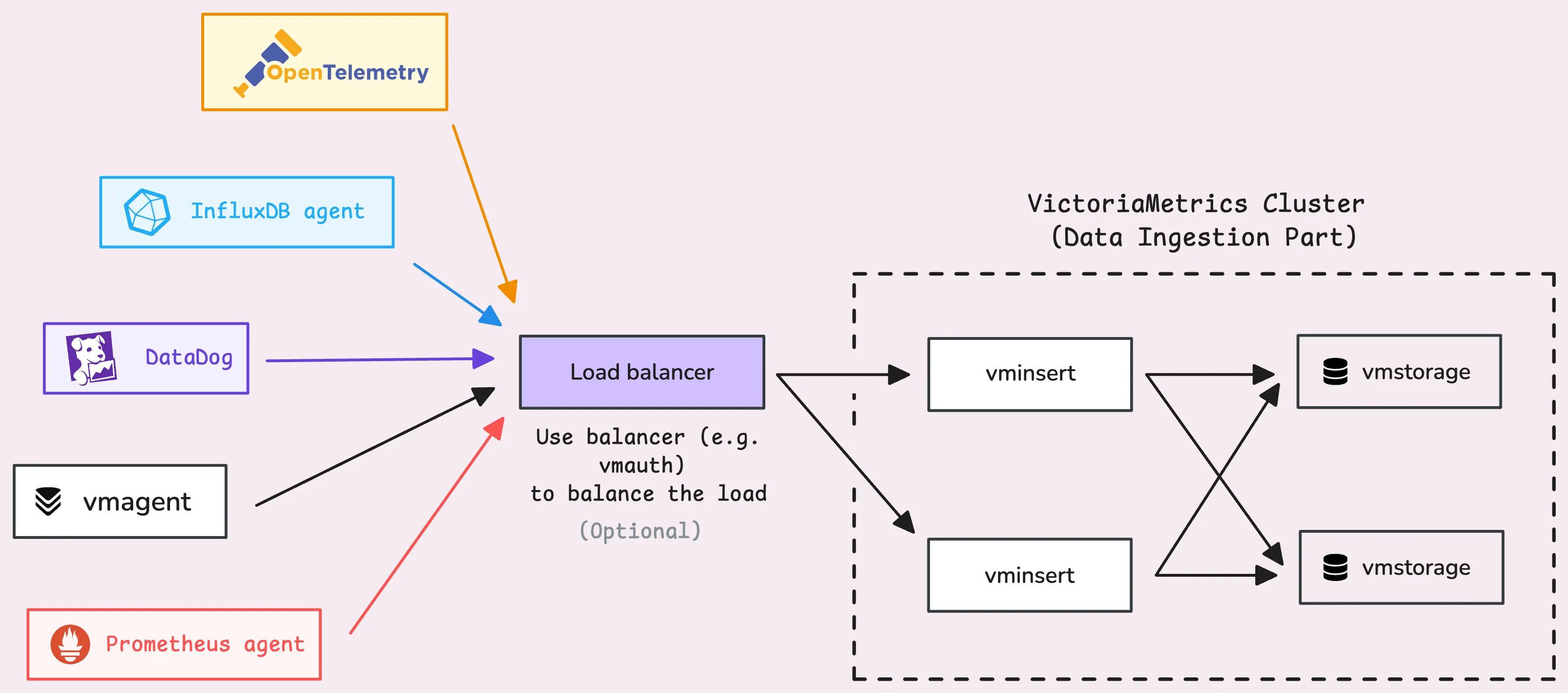
读取和解析数据
在vmstorage接收到数据之后,并不会直接读取这些数据。首先会检查读并发限速器(限制为2倍的CPU cores),如果读操作过多,则最终会排队等候处理。
vmstorage每次会读取一个block,block的结构如下,包含一个表示block大小的8字节的size字段以及一个body字段。一个block不能超过100MB。
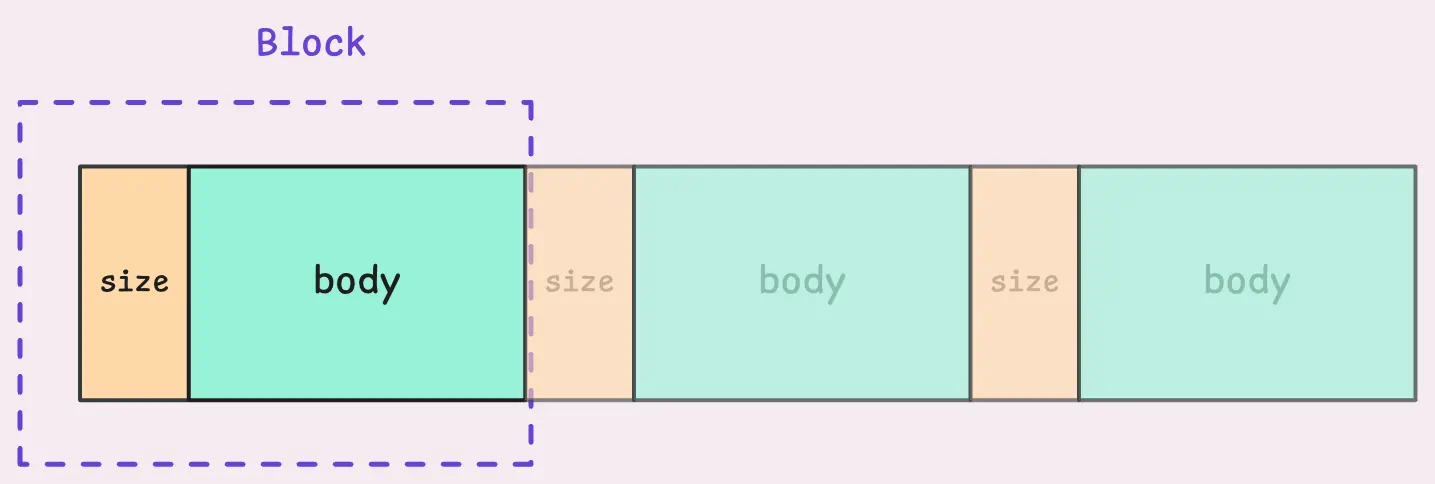
有一个边缘场景值得注意:即当vmstorage在速磁盘空间不足时会转变为只读模式。该模式下vmstorage会对接收到的数据响应"read-only ack",并忽略实际内容,vminsert会识别此种确认类型并重发数据(本文后面讨论)。
本阶段中,vmagent仅使用字节流方式读取原始block,并不会对其解析。这些原始字节最终会被拆分为rows进行处理。
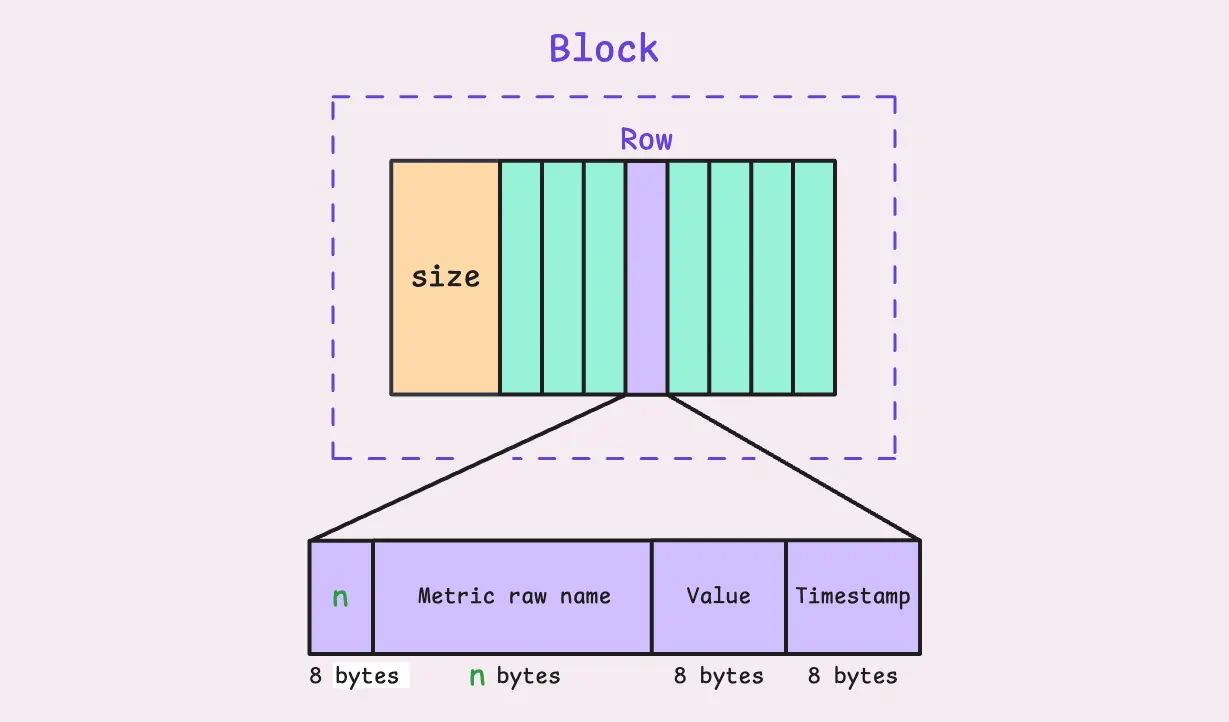
如果block过大,vmstorage会以chunks为单位进行处理,每次处理10,000 rows数据并将其写入存储。
查找每条metric的TSID
TSID用于表示不同的时间序列,有如下作用:
数据存储优化:
- TSID 在存储时序数据时起到索引的作用。VictoriaMetrics 使用 TSID 来将时间序列数据映射到磁盘的存储位置,从而避免直接存储复杂的指标名称和标签。
- 通过 TSID,可以快速找到时间序列对应的样本(samples,时间戳与值的组合)并高效地写入或读取数据。
查询加速:
- 当查询某个指标时,VictoriaMetrics 会解析查询中指定的标签或指标名称,通过倒排索引查找与查询条件匹配的 TSID。
每条metric包含如下几个关键部分:
- 一个metrics名称
- 一组metrics labels
- 一个时间戳(毫秒)
- 一个浮点数表示的metric value

在计算metric的TSID之前,首先需要创建"规范的指标名称",即将metric name和labels组合起来,然后按名字的字母顺序排列,目的是防止包含相同labels的metrics,只是因为labels顺序不同而被认为是不同的metric,如metric{instance="host",job="app"} 和 metric{job="app",instance="host"}是相同的metric,只是label顺序不同。
TSID是一种可以表示时间序列的唯一数字,用于快速定位数据。

上一节中,vmstorage从block中获取到了原始的metrics(无排序),然后通过查询TSID缓存来判断是否已经存在对应的TSID,如果存在,则直接插入该指标:
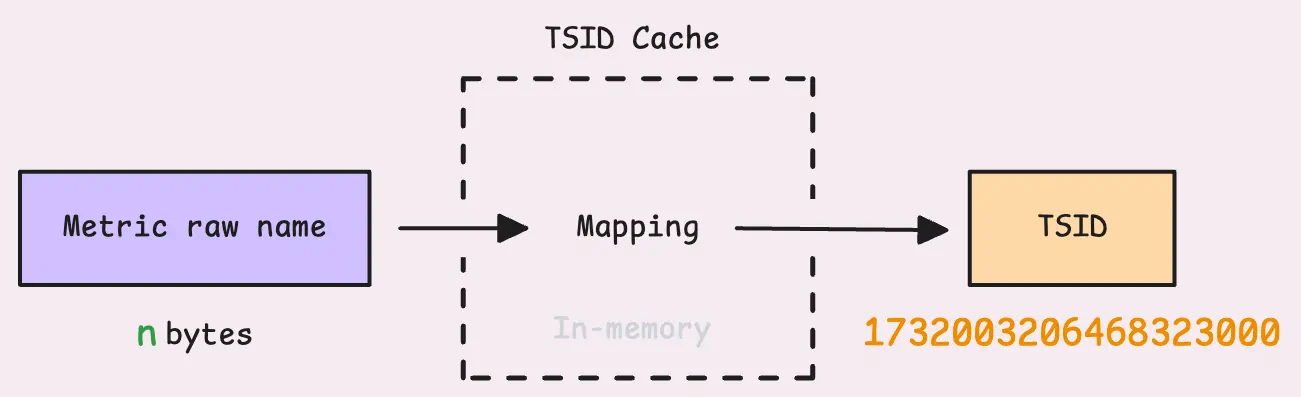
如果不存在,则需要向IndexDB查询,由于涉及随机磁盘查询,因此这是一个比较慢的过程。在查找成功后缓存结果。
如果不存在,则说明这是一个全新的metric。此时,系统需要生成一个新的TSID,并将其同时注册到内存缓存和IndexDB,包括如下步骤:
- 将"规范指标名称"映射到新的TSID
- 设置反向映射,这样TSID可以指向"规范指标名称"
- 倒排索引包含"规范指标名称"中的每个label,可以帮助系统在使用标签过滤时快速查询时序数据
- 创建以天为单位的索引,用于优化按时间范围查找数据的场景。
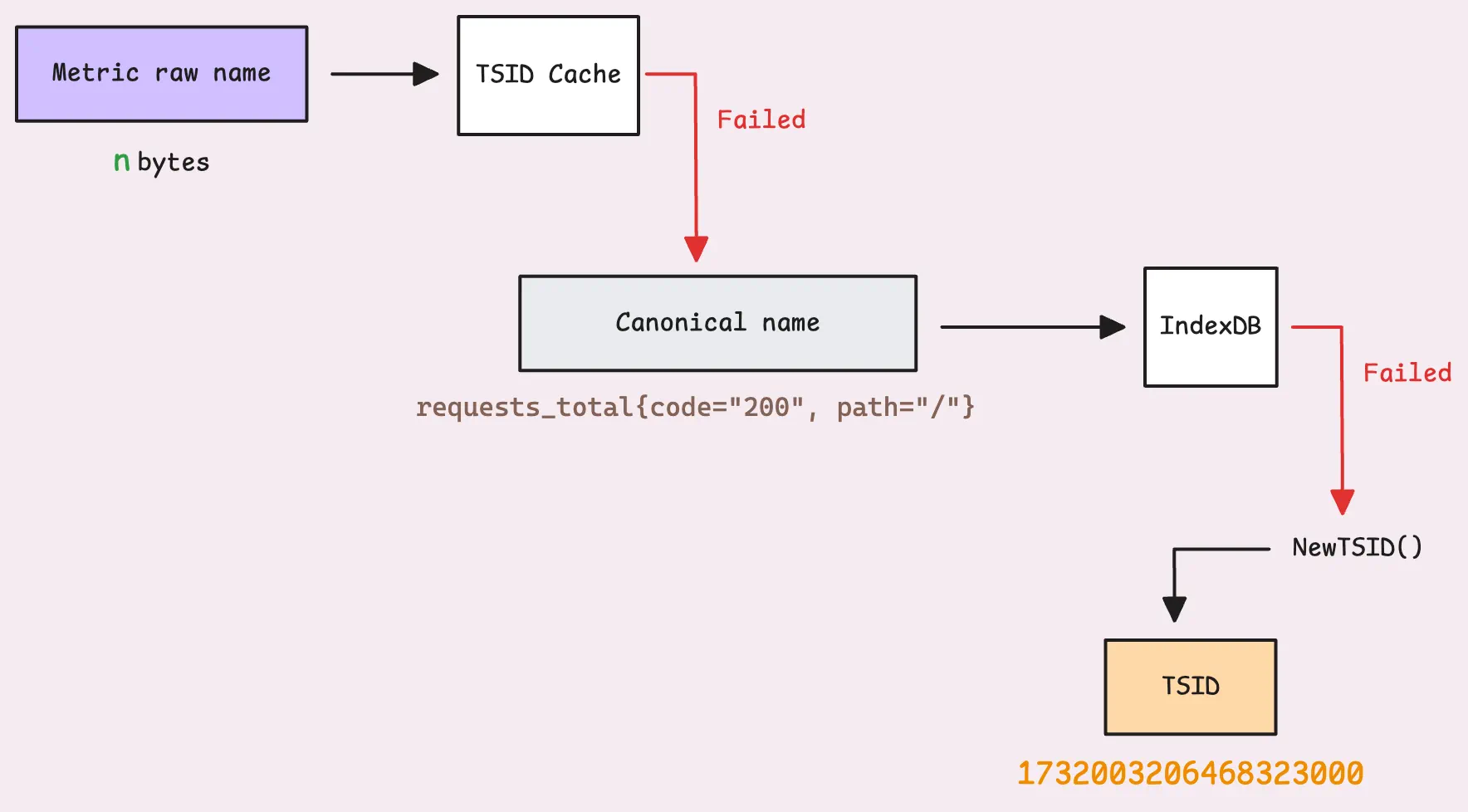
注册新的时间序列涉及向磁盘写入与之相关的所有信息,该过程可能会拖慢整个系统,特别是当metric拥有很多labels或非常长的labels时。
这也是为什么要关注churn rate的原因。vmstorage可以按小时 (-storage.maxHourlySeries)和天(-storage.maxDailySeries)限制新创建的时序数据总量。
向内存缓冲插入数据
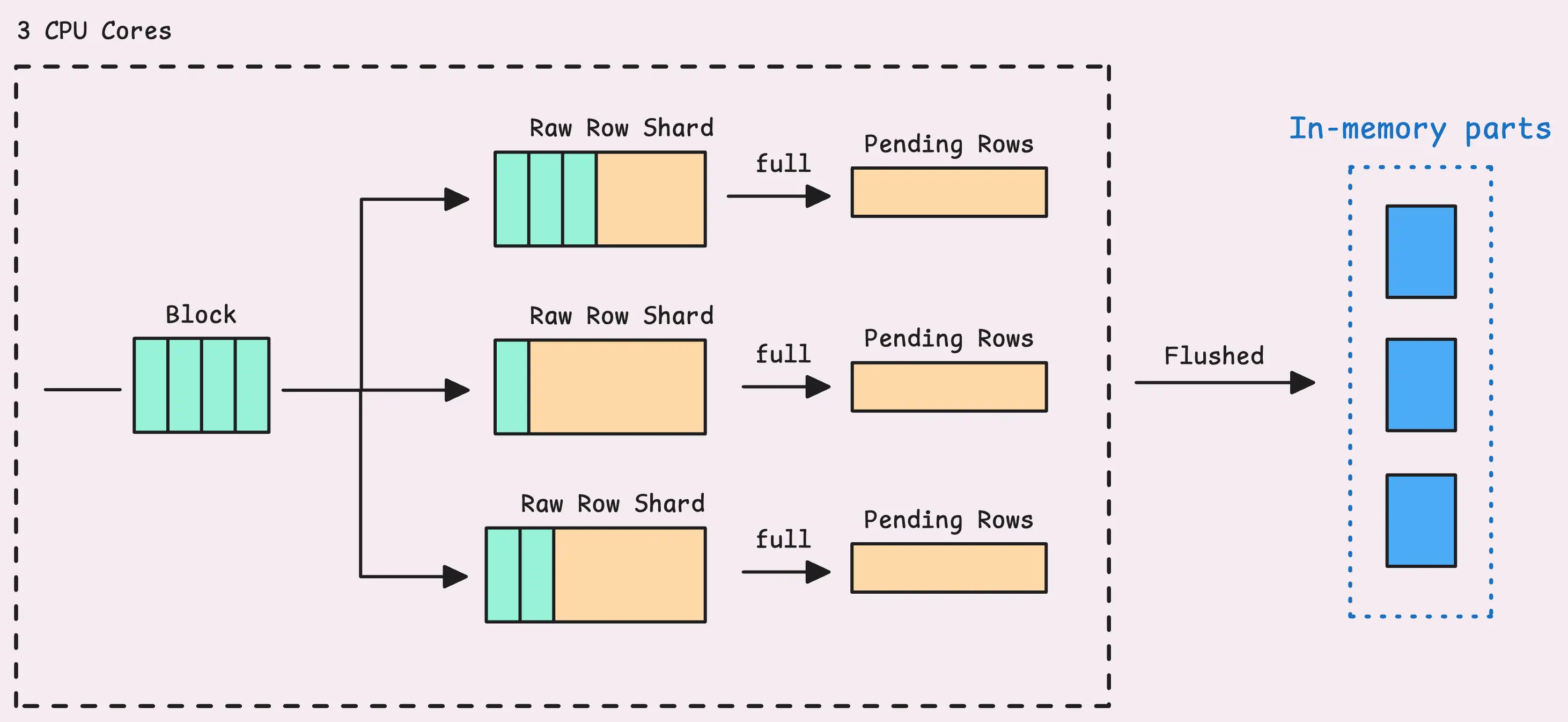
一旦注册好TSID,VictoriaMetrics就可以处理实际的数据样本,包括TSID、时间戳、值等,并将其放入一个内存缓冲(称为"raw-row shards"),且一个partition(表示一个月的数据)的shards数目等于CPU cores的数目。例如,机器有4 cores,则每个月的数据有4个shards,每个shards最多可以有8 MB的数据,约149,796 rows。
如果shard被填满,则这些rows会被推入一个称为"pending series"的地方,等待被处理成“LSM part”,并最终写入磁盘。只有刷新到LSM part的数据才能被查询到,之后便完成了本block的数据处理,可以开始处理下一个block。
数据如何写入磁盘
在如下两种情况中,Shard缓冲会刷新数据:
- 当缓冲达到阈值(约120MB),刷新pending series
- 如果距上一次刷新超过2s,则系统会自动刷新 pending series和raw-row shards
在刷新过程中,数据会转换为一个LSM part,LSM part中的项会根据TSID和时间戳进行排序。
LSM Parts的类型
每个partition(涵盖一个月的数据)会将其数据组织为3种LSM parts类型:
- 内存 part:存放raw-row shards首次刷新后的数据,此时数据可以被搜索和查询
- Small part:比内存part稍大,存储在持久化磁盘上
- big part:最大的parts,存储在磁盘上
vmstorage同一时间最多可以持有60个内存parts,占用约10%的系统内存。例如,vmstorage内存为10GB,则内存parts占1GB,每个part约1MB~17MB。
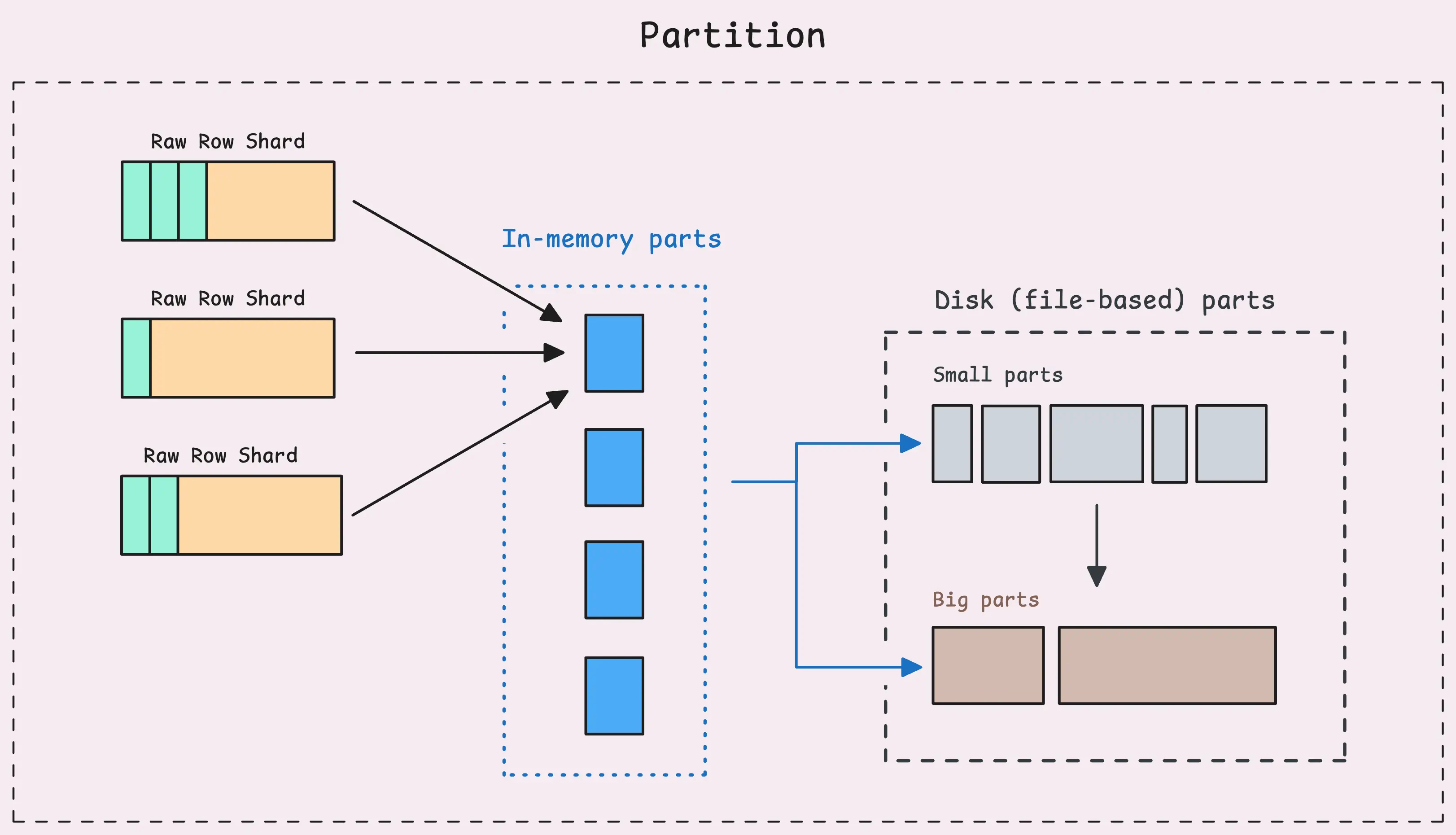
随着数据的写入,会创建越来越多的parts,当LSM parts过多(无论是内存还是磁盘)时,每个查询(如来自grafana的查询)都需要扫描并合并这些parts,可能会拖慢系统。
为了防止上述问题,vmstorage依赖两个关键处理:刷新和合并。
- 刷新:将所有内存parts刷新到磁盘的small parts。每5s,vmstorage(
-inmemoryDataFlushInterval)会将内存parts刷新到基于磁盘或文件的parts上。 - 合并:将多个parts合并为更高效的存储。这并不意味着将所有small parts合并为big parts,而是将一部分small parts合并为稍大一些的small parts
合并过程
合并并不是固定调度的。只要有parts累积,系统就会尝试合并这些parts,将内存parts合并为较大的内存part,将small parts合并为较大的small part,将big parts合并为较大的big part。
small parts不能超过10MB,big parts最大可以占用大约剩余磁盘空间/4,但不能超过1TB。注意small parts和big parts只是系统在合并过程中评估出来的需要创建的part类型,并不是说small parts一定小于big parts。
small parts合并的结果最终会被写入磁盘,该过程中会执行去重操作。
去重是确认并移除那些几乎相等,但记录时间略微不同的时间点。通常发生在出于冗余或可靠性目的,而使用两个或多个监控系统将相同指标并发往同一个存储的场景。
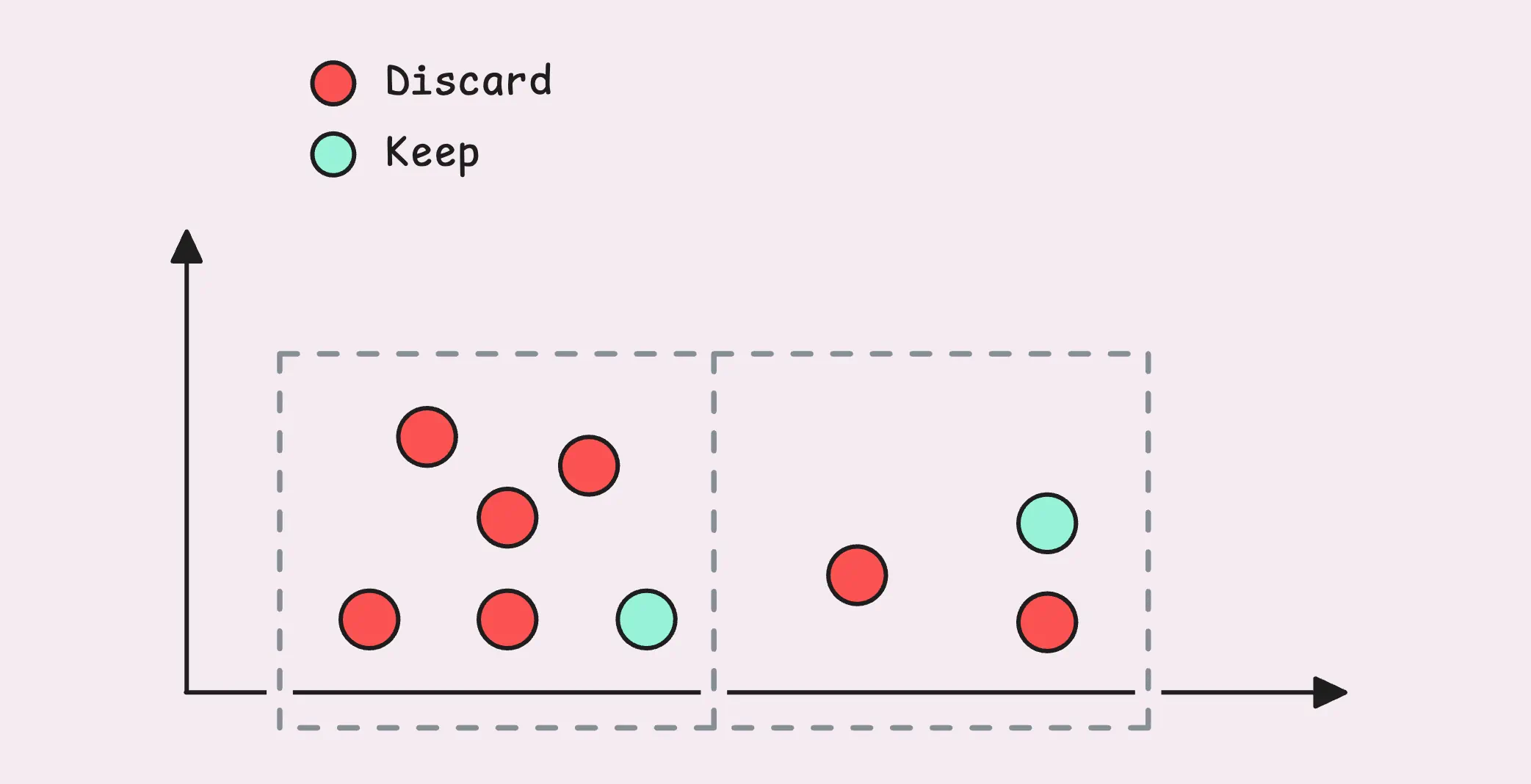
默认关闭去重,可以通过-dedup.minScrapeInterval启用去重功能。
Retention, Free Disk Space Guard和 Downsampling
vmstorage的默认回收周期是1个月。需要注意的是,每个part包含很多样本,只要有一个样本在回收周期内,则必须保留整个part。
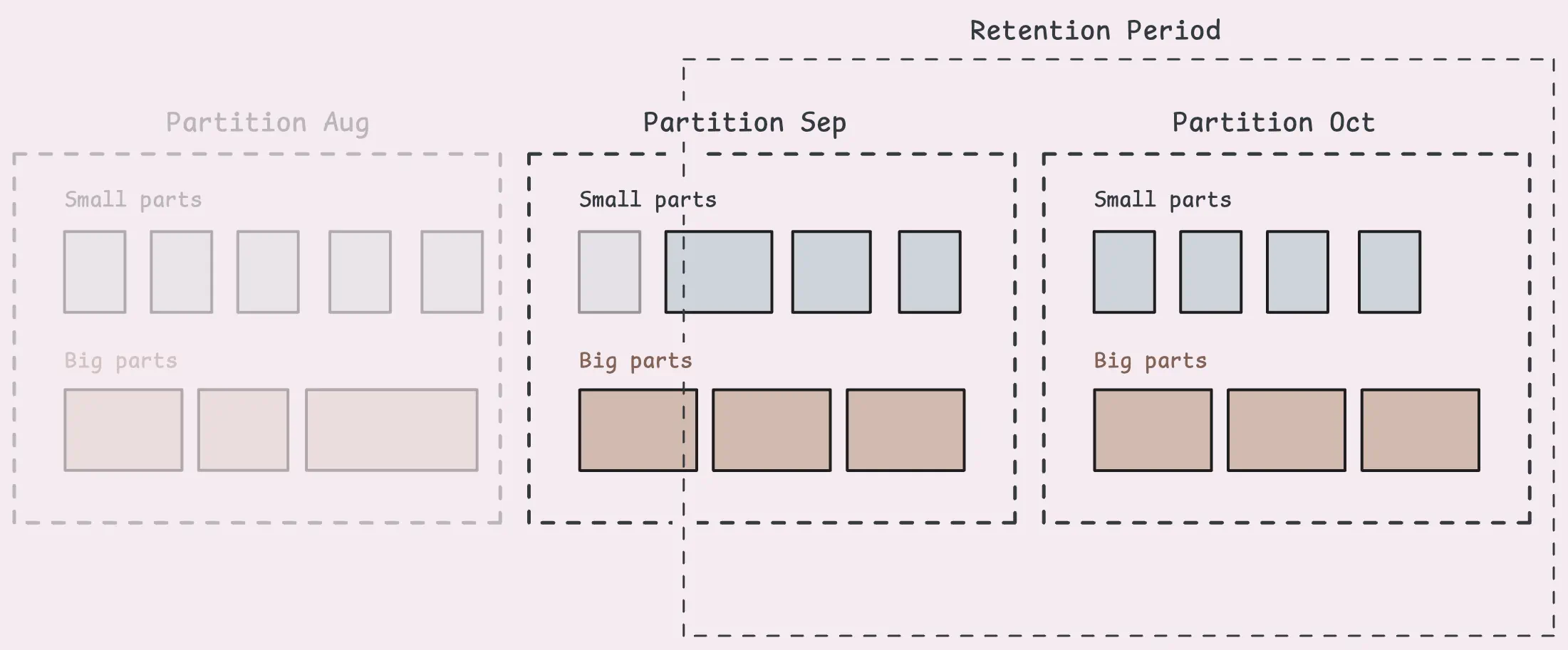
Free Disk Space Watcher: Read Only Mode
一开始提到,在磁盘空间不足的情况下,vmstorage会进入read-only模式,该模式下,vminset会接收到数据发送的确认信息,但vmstorage会忽略掉这些数据。此时vmstorage仍然能够提供查询请求,但停止接收任何写数据。一旦释放了磁盘空间(-storage.minFreeDiskSpaceBytes,默认10MB),vmstorage会退出read-only模式。
Partition的结构
无论是内存parts,small parts还是big parts,其数据都是列模式,即TSID、时间戳和值都不会组合在一个记录中,而是被分散到不同的列,每一列都保存在各自的文件中。
- 所有 TSIDs 都保存在
index.bin. - 所有时间戳都保存在
timestamps.bin. - 所有值都保存在
values.bin.
对于内存parts,这些列结构已经就绪,可以直接刷新到基于文件的parts中。
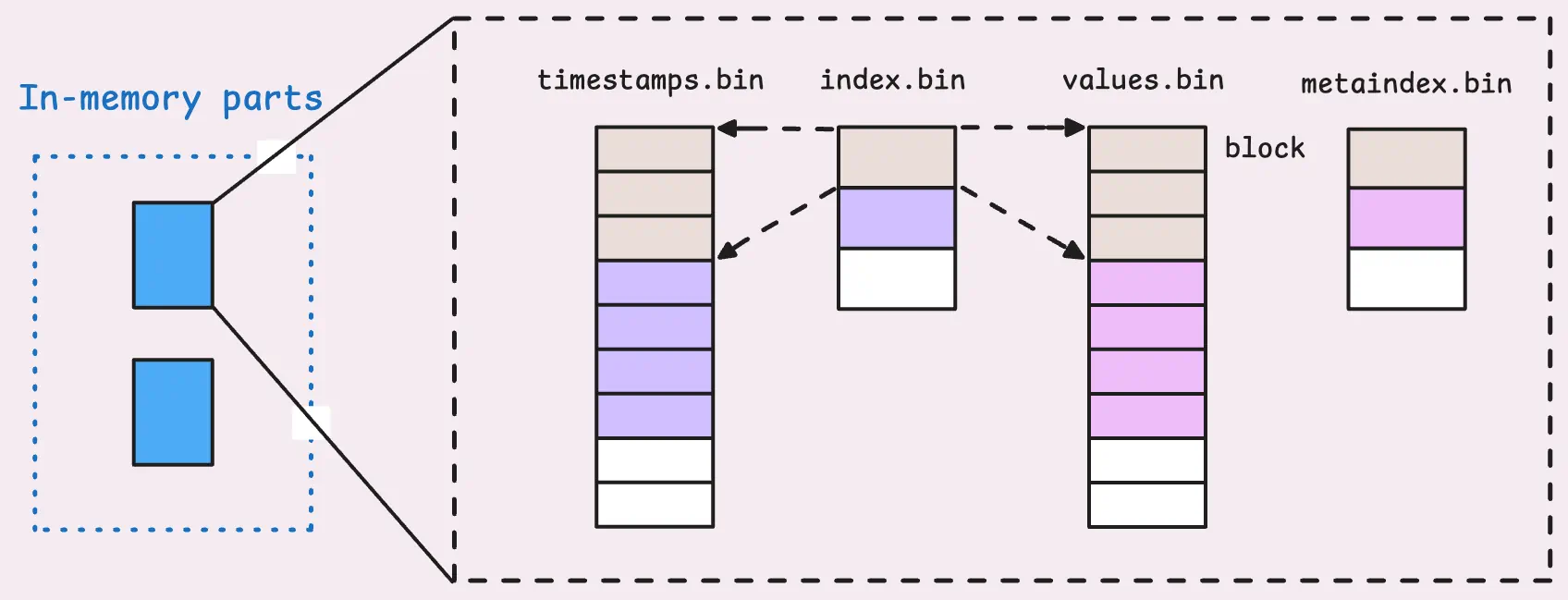
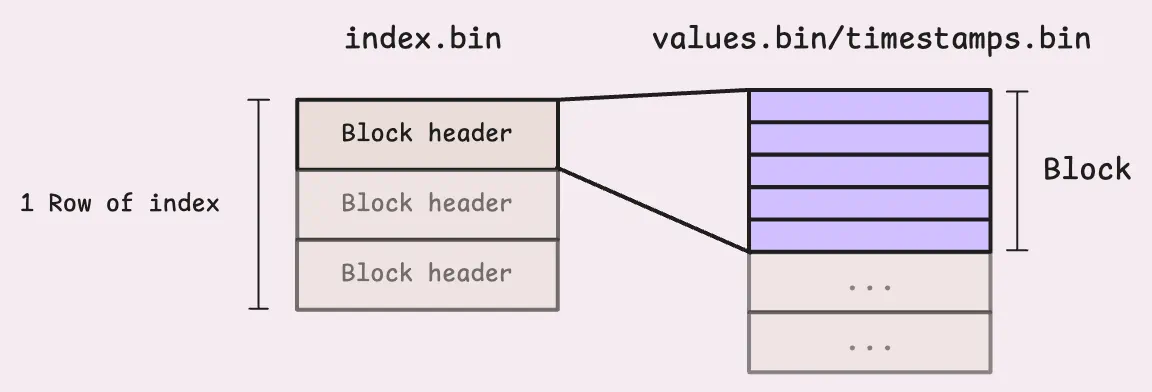
列模式便于压缩和快速查找。 timestamps.bin 和 values.bin中的每个block表示单个TSID行,一个block最多可以有8192 行。
index.bin的每一行包括多个block首部,一个block首部包含:
- block的TSID
- block的行数
- block在
timestamps.bin和values.bin中的位置
vmstorage如何将原始指标转换为有组织的历史的更多相关文章
- JavaScript中对象转换为原始值的规则
JavaScript中对象转换为原始值遵循哪些原则? P52 对象到布尔值对象到布尔值的转换非常简单:所有的对象(包括数字和函数)都转换为true.对于包装对象亦是如此:new Boolean(fal ...
- Python交互K线工具 K线核心功能+指标切换
Python交互K线工具 K线核心功能+指标切换 aiqtt团队量化研究,用vn.py回测和研究策略.基于vnpy开源代码,刚开始接触pyqt,开发界面还是很痛苦,找了很多案例参考,但并不能完全满足我 ...
- GitHub上创建组织
4.3. 组织和团队 GitHub 在早期没有专门为组织提供账号,很多企业用户或大型开源组织只好使用普通用户账号作为组织的共享账号来使用.后来,GitHub推出了组织这一新的账号管理模式,满足大型开发 ...
- [No0000A2]“原始印欧语”(PIE)听起来是什么样子?
"Faux Amis"节目中经常提到"原始印欧语"(PIE)——"Proto-Indo-European". 我们说过,英语,法语中的&qu ...
- 基于知识图谱的APT组织追踪治理
高级持续性威胁(APT)正日益成为针对政府和企业重要资产的不可忽视的网络空间重大威胁.由于APT攻击往往具有明确的攻击意图,并且其攻击手段具备极高的隐蔽性和潜伏性,传统的网络检测手段通常无法有效对其进 ...
- Apache Mahout:适合所有人的可扩展机器学习框架
http://www.ibm.com/developerworks/cn/java/j-mahout-scaling/ 在软件的世界中,两年就像是无比漫长的时光.在过去两年中,我们看到了社交媒体的风生 ...
- 基于PU-Learning的恶意URL检测——半监督学习的思路来进行正例和无标记样本学习
PU learning问题描述 给定一个正例文档集合P和一个无标注文档集U(混合文档集),在无标注文档集中同时含有正例文档和反例文档.通过使用P和U建立一个分类器能够辨别U或测试集中的正例文档 [即想 ...
- 精通Web Analytics 2.0 (6) 第四章:点击流分析的奇妙世界:实际的解决方案
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第四章:点击流分析的奇妙世界:实际的解决方案 到开始实际工作的时候了.哦耶! 在本章中,您将了解到一些最重要的网络分析报告,我将 ...
- Reporting Services 的伸缩性和性能表现规划(转载)
简介 Microsoft? SQL Server? Reporting Services 是一个将集中管理的报告服务器具有的伸缩性和易管理性与基于 Web 和桌面的报告交付手段集于一身的报告平台.Re ...
- 使用Thrift RPC编写程序(服务端和客户端)
1. Thrift类介绍 Thrift代码包(位于thrift-0.6.1/lib/cpp/src)有以下几个目录: concurrency:并发和时钟管理方面的库processor:Processo ...
随机推荐
- 云原生周刊:K8sGPT 加入 CNCF | 2024.1.8
开源项目推荐 VolSync VolSync 使用 rsync 或 rclone 在集群之间异步复制 Kubernetes 持久卷.它还支持通过 Restic 创建持久卷的备份. KubeClarit ...
- 线上debug&gateway自定义路由规则
如何进行线上debug. 如何在gateway自定义路由规则去进行请求分发,让请求打到集群模式下我们想要的节点. 1.配置remote debug 1.在启动参数配置参数: -Xdebug -Xrun ...
- uniapp、nativeJS、H5+退出APP应用(IOS+安卓)
uniapp.nativeJS.H5+退出APP应用(IOS+安卓)阅读原文:https://mp.weixin.qq.com/s/Aru-DCcSHrNcuxJ6Q94QLQ直接扫码进入此链接可阅读 ...
- php技术交流群
php技术交流群-656679284,为PHP广大爱好者提供技术交流,有问必答,相互学习相互进步!也欢迎大牛入群指导!
- 5.2 Vi和Vim之间到底有什么关系?
我们知道,Vi 编辑器是 Unix 系统最初的编辑器.它使用控制台图形模式来模拟文本编辑窗口,允许查看文件中的行.在文件中移动.插入.编辑和替换文本. 尽管 Vi 可能是世界上复杂的编辑器(讨厌它的人 ...
- 基于Java+SpringBoot+Mysql实现的快递柜寄取快递系统功能实现八
一.前言介绍: 1.1 项目摘要 随着电子商务的迅猛发展和城市化进程的加快,快递业务量呈现出爆炸式增长的趋势.传统的快递寄取方式,如人工配送和定点领取,已经无法满足现代社会的快速.便捷需求.这些问题不 ...
- python模块导入规则(相对导入和绝对导入)
python模块可以相对导入和绝对导入,但这两者是不能随意替换使用的.本文主要讨论工作目录下模块之间的导入规则.其中相对导入前面有一个'.',表示从该脚本所在目录开始索引,而绝对导入前面没有'.',表 ...
- Vim基本使用指南
一般模式:移动光标的方法 h或 向左方向键(←)光标向左移动一个字符 j或 向下方向键(↓)光标向下移动一个字符 k或 向上方向键(↑)光标向上移动一个字符 l或 向右方向键(→)光标向右移动一个字符 ...
- 基于python的文件监控watchdog
实时监控第三方库watchdog,其原理通过操作系统的时间触发的,不需要循环和等待 使用场景: 1.监控文件系统中文件或目录的增删改情况 2.当特定的文件被创建,删除,修改,移动时执行相应的任务 1. ...
- 纯JS+CSS实现羊了个羊
前言 省流 gitee上扒的,感觉还不错,拿下来玩玩. https://gitee.com/kenxq/ylgy.git 技术说明 纯JS+CSS实现羊了个羊,包含部分特效,响应式手机.电脑.ipad ...