深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器
title: 深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器
date: 2025/1/14
updated: 2025/1/14
author: cmdragon
excerpt:
在数据处理和分析的过程中,需要对收集到的信息进行整理和汇总,从而为决策提供依据。在 SQL 语言中,GROUP BY 和 HAVING 子句是用于分组和过滤数据的重要工具。它们使得用户能够对数据进行高效的聚合和分析,尤其是进行复杂的统计计算和报告生成时格外有用。
categories:
- 前端开发
tags:
- SQL
- GROUP BY
- HAVING
- 数据分析
- 聚合函数
- 数据分组
- 性能优化

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
{kind=link}
在 SQL 查询中,GROUP BY 和 HAVING 子句是进行数据汇总和分析的重要工具。通过对数据进行分组,这些子句使得开发人员能够生成多维度的数据报告并应用聚合函数,从而更好地理解和展现数据。
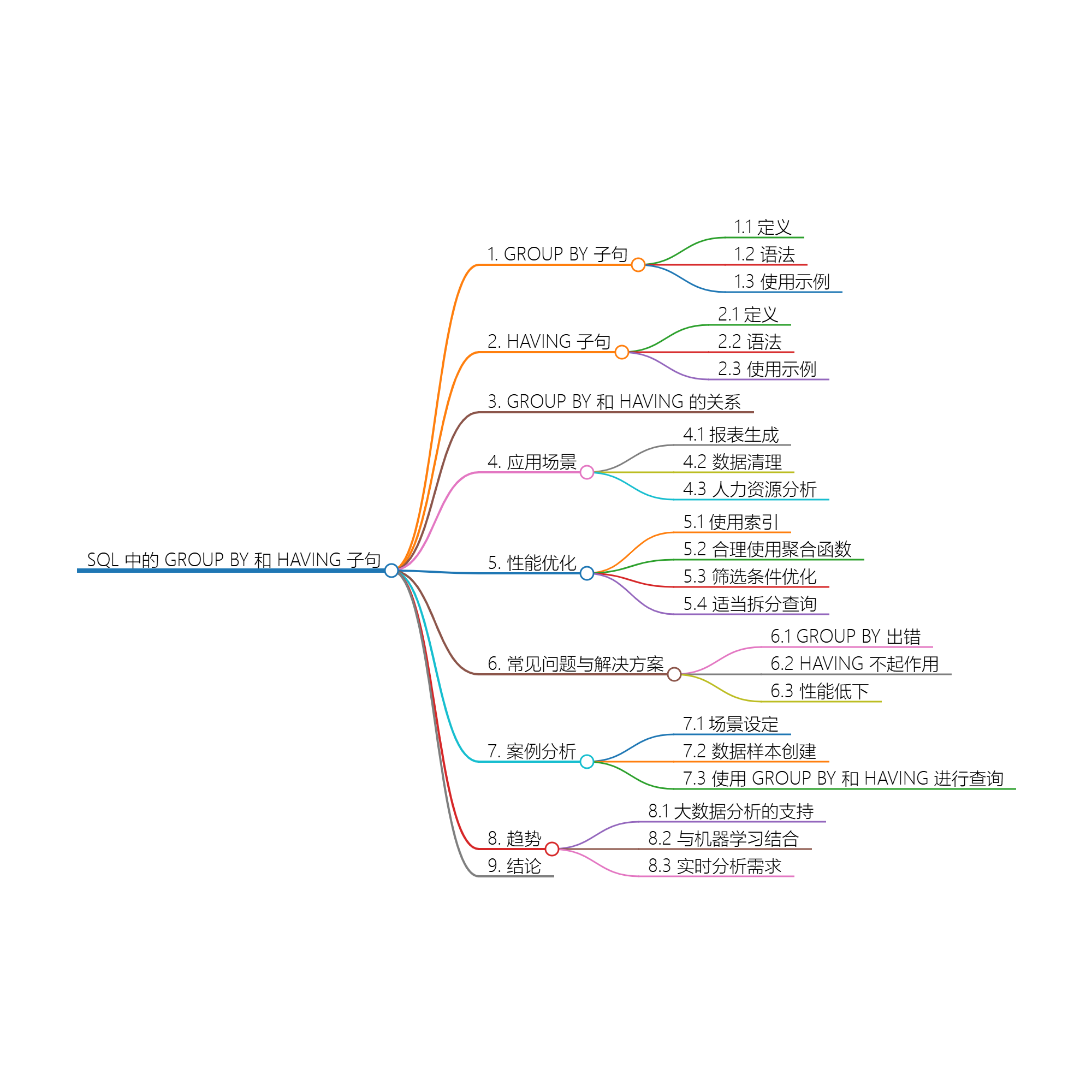
1. 引言
在数据处理和分析的过程中,需要对收集到的信息进行整理和汇总,从而为决策提供依据。在 SQL 语言中,GROUP BY 和 HAVING 子句是用于分组和过滤数据的重要工具。它们使得用户能够对数据进行高效的聚合和分析,尤其是进行复杂的统计计算和报告生成时格外有用。
2. GROUP BY 子句概述
2.1 定义
GROUP BY 子句用于将结果集中的数据按一个或多个列进行分组。使用 GROUP BY 之后,可以对每个分组应用聚合函数(如 SUM、COUNT、AVG 等),从而生成总结性的数据。
2.2 语法
基本的语法格式如下:
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE condition
GROUP BY column1;
在这个结构中,column1 是用于分组的列,aggregate_function(column2) 是聚合函数。
2.3 使用示例
考虑一个员工表 employees,包含 department(部门)和 salary(薪资)字段。我们希望计算各部门的员工数量和总薪资。
SELECT department, COUNT(*) AS employee_count, SUM(salary) AS total_salary
FROM employees
GROUP BY department;
这个查询将返回每个部门的员工数量和总薪资。
3. HAVING 子句概述
3.1 定义
HAVING 子句用于过滤分组后的结果集,相较于 WHERE 子句,HAVING 允许在聚合结果上进行条件过滤。
3.2 语法
其基本语法格式如下:
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING condition;
在这个结构中,condition 应当是基于聚合函数的条件。
3.3 使用示例
继续以 employees 表为例,如果我们希望只查看员工数大于 10 的部门,我们可以在查询中使用 HAVING。
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department
HAVING COUNT(*) > 10;
这一查询返回员工人数超过10的部门。
4. GROUP BY 和 HAVING 的关系
虽然 GROUP BY 和 HAVING 都用于处理结果集,但其作用却各有不同:
GROUP BY在数据行级别上对结果集进行分组,而HAVING则在聚合结果级别上过滤数据。WHERE子句在聚合之前过滤数据,而HAVING子句在数据分组之后过滤聚合结果。
这种关系使得它们在复杂数据处理和分析时互为补充。
5. 应用场景
GROUP BY 和 HAVING 在各种场景中都大显身手,以下是一些典型的应用场景:
5.1 报表生成
在生成业务报表时,GROUP BY 和 HAVING 可以用来统计销售额、客户数量等重要指标。例如:
SELECT region, SUM(sales) AS total_sales
FROM sales_data
GROUP BY region
HAVING SUM(sales) > 100000;
此查询返回销售额超过 100,000 的区域总销售数据。
5.2 数据清理
在数据分析中,可能需要识别异常值或清洗数据。通过结合 GROUP BY 和 HAVING,可以快速找到频繁出现的错误数据。例如,查找出现次数超过 5 次的用户 IP。
SELECT ip_address, COUNT(*) AS access_count
FROM access_log
GROUP BY ip_address
HAVING COUNT(*) > 5;
5.3 人力资源分析
在 HR 数据分析中,通常需要对员工数据进行分类和汇总。比如,计算每个部门的平均薪水,并且只保留平均薪水超过 50,000 的部门。
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;
6. 性能优化
对GROUP BY 和 HAVING 的性能优化是非常重要的,以下是一些建议:
6.1 使用索引
在 GROUP BY 上使用索引可以提高查询效率。为涉及的列创建适当的索引,以加快分组处理的速度。
6.2 合理使用 聚合函数
仅对需要的数据进行分组,避免不必要的计算。此外,尽量做到查询的简练,避免重复的聚合函数调用。
6.3 筛选条件优化
将能够使用 WHERE 子句的方法放在 HAVING 之前,使用 WHERE 限制原始数据集,可以显著减少后续操作的计算量。
6.4 适当拆分查询
在某些复杂情况下,拆分查询,先计算并存储临时表,然后再进行进一步处理,可以提高效率。
7. 常见问题与解决方案
7.1 GROUP BY 出错
如果在使用 GROUP BY 时出现 SQL 错误,检查 SELECT 子句中是否包含了所有未被聚合的列。
7.2 HAVING 不起作用
如果 HAVING 子句未能返回预期结果,确保使用的条件针对的是聚合函数,并确认分组数据是否正确。
7.3 性能低下
若执行查询缓慢,使用 EXPLAIN 来分析查询计划,找出子句中的潜在瓶颈,及时优化。
8. 案例分析
为了更好地理解 GROUP BY 和 HAVING 的使用,以下是一个实际的案例分析。
8.1 场景设定
假设我们有一个销售数据表 sales_data,该表包含 product_id、sale_amount、sale_date、region 等字段。
8.2 数据样本创建
CREATE TABLE sales_data (
id SERIAL PRIMARY KEY,
product_id INT,
sale_amount DECIMAL(10, 2),
sale_date DATE,
region VARCHAR(50)
);
INSERT INTO sales_data (product_id, sale_amount, sale_date, region) VALUES
(1, 200.00, '2023-01-01', 'North'),
(2, 120.00, '2023-01-05', 'South'),
(1, 180.00, '2023-01-10', 'North'),
(3, 150.00, '2023-01-12', 'East'),
(2, 70.00, '2023-01-15', 'South'),
(3, 90.00, '2023-01-20', 'East'),
(1, 300.00, '2023-01-25', 'North'),
(2, 60.00, '2023-01-28', 'South');
8.3 使用 GROUP BY 和 HAVING 进行查询
我们希望统计每种产品的总销售额,并只保留总销售额超过 250 的产品。
SELECT product_id, SUM(sale_amount) AS total_sales
FROM sales_data
GROUP BY product_id
HAVING SUM(sale_amount) > 250;
8.3.1 结果解释
此查询会返回所有销售额超过 250 的产品及其对应的销售总额。假设结果如下:
| product_id | total_sales |
|---|---|
| 1 | 680.00 |
| 3 | 240.00 |
在这个示例中,产品 ID 为 1 的销售额显著高于 250,而产品 ID 为 3 则未通过筛选。
9. 趋势
随着数据分析和数据库技术的不断发展,GROUP BY 和 HAVING 的使用和优化也将面临新的挑战与机遇,未来可能的趋势包括:
9.1 大数据分析的支持
在处理大规模数据时,传统的 SQL 查询可能面临性能瓶颈,因此,如何高效地将 GROUP BY 与分布式计算框架结合,将是一个研究方向。
9.2 与机器学习结合
结合机器学习技术,实现对分组数据的智能化分析与预测,使得 GROUP BY 和 HAVING 不再局限于传统的聚合,而是提供更深层次的洞察。
9.3 实时分析需求
随着行业的变化,实时数据分析变得日益重要,如何优化 GROUP BY 和 HAVING 以支持快速数据处理、聚合和过滤,将是下一个关注点。
10. 结论
GROUP BY 和 HAVING 凭借其强大的数据处理能力,已经成为 SQL 查询和数据分析中不可或缺的部分。通过对两者的深入分析,我们发现其相辅相成,并在实践中具备显著的应用价值。理解如何有效利用这两种工具将极大提升数据分析的能力,从而为各类应用场景提供重要支持。
参考文献
- SQL and Relational Theory - Chris Date
- SQL Cookbook - Anthony Molinaro
- Effective SQL: 61 Specific Ways to Write Better SQL - John Viescas
- 数据库系统概念 - Abraham Silberschatz, Henry Korth & S. Sudarshan
- PostgreSQL Documentation: GROUP BY
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器 | cmdragon's Blog
往期文章归档:
- 深入探讨聚合函数(COUNT, SUM, AVG, MAX, MIN):分析和总结数据的新视野 | cmdragon's Blog
- 深入解析子查询(SUBQUERY):增强 SQL 查询灵活性的强大工具 | cmdragon's Blog
- 探索自联接(SELF JOIN):揭示数据间复杂关系的强大工具 | cmdragon's Blog
- 深入剖析数据删除操作:DELETE 语句的使用与管理实践 | cmdragon's Blog
- 数据插入操作的深度分析:INSERT 语句使用及实践 | cmdragon's Blog
- 特殊数据类型的深度分析:JSON、数组和 HSTORE 的实用价值 | cmdragon's Blog
- 日期和时间数据类型的深入探讨:理论与实践 | cmdragon's Blog
- 数据库中的基本数据类型:整型、浮点型与字符型的探讨 | cmdragon's Blog
- 表的创建与删除:从理论到实践的全面指南 | cmdragon's Blog
- PostgreSQL 数据库连接 | cmdragon's Blog
- PostgreSQL 数据库的启动与停止管理 | cmdragon's Blog
- PostgreSQL 初始化配置设置 | cmdragon's Blog
- 在不同操作系统上安装 PostgreSQL | cmdragon's Blog
- PostgreSQL 的系统要求 | cmdragon's Blog
- PostgreSQL 的特点 | cmdragon's Blog
- ORM框架与数据库交互 | cmdragon's Blog
- 数据库与编程语言的连接 | cmdragon's Blog
- 数据库审计与监控 | cmdragon's Blog
- 数据库高可用性与容灾 | cmdragon's Blog
- 数据库性能优化 | cmdragon's Blog
- 备份与恢复策略 | cmdragon's Blog
- 索引与性能优化 | cmdragon's Blog
- 事务管理与锁机制 | cmdragon's Blog
- 子查询与嵌套查询 | cmdragon's Blog
- 多表查询与连接 | cmdragon's Blog
- 查询与操作 | cmdragon's Blog
- 数据类型与约束 | cmdragon's Blog
- 数据库的基本操作 | cmdragon's Blog
深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器的更多相关文章
- SQL常见优化Sql查询性能的方法有哪些?
常见优化Sql查询性能的方法有哪些? 1.查询条件减少使用函数,避免全表扫描 2.减少不必要的表连接 3.有些数据操作的业务逻辑可以放到应用层进行实现 4.可以使用with as 5.使用“临时表”暂 ...
- 47、Spark SQL核心源码深度剖析(DataFrame lazy特性、Optimizer优化策略等)
一.源码分析 1. ###入口org.apache.spark.sql/SQLContext.scala sql()方法: /** * 使用Spark执行一条SQL查询语句,将结果作为DataFram ...
- 索引 使用use index优化sql查询
好博客:MySQL http://webnoties.blog.163.com/blog/#m=0&t=1&c=fks_08407108108708107008508508609508 ...
- 如何优化sql查询
借鉴https://www.cnblogs.com/ssrstm/p/5753068.html和https://www.cnblogs.com/exe19/p/5786806.html 1. 对查询进 ...
- 通过手动创建统计信息优化sql查询性能案例
本质原因在于:SQL Server 统计信息只包含复合索引的第一个列的信息,而不包含复合索引数据组合的信息 来源于工作中的一个实际问题, 这里是组合列数据不均匀导致查询无法预估数据行数,从而导致无法选 ...
- 优化SQL 查询性能
为什么查询会很慢 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.要优化查询,实际上是要优化其子任务,要么消除其中一些子任务,要么减少子任务的执行次数,要么让子任务运 ...
- 优化SQL查询:如何写出高性能SQL语句
1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个 10万条记录的表中查1条 ...
- 关于优化sql查询的一个方法。
select * from gmvcsbase.base_file file,gmvcsbase.base_user user,gmvcsbase.base_department dep,gmvcsb ...
- Entity Framework 第四篇 优化SQL查询
Expression<Func<TEntity, bool>>与Func<TEntity, bool>的异同 public IList<TEntity> ...
- 几个优化SQL查询的方法
1.什么是执行计划 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个 10万条记录的表中查1条记录,那查询优化 ...
随机推荐
- springboot 复杂邮件发送
application.yml配置 密码为邮箱开启smtp时邮箱服务商提供的密码
- esp8266+http (PlatformIO)
esp8266 + http 使用esp8266发起http请求 #include <Arduino.h> #include <ESP8266WiFi.h> #include ...
- 第八届御网杯线下赛Pwn方向题解
由于最近比赛有点多,而且赶上招新,导致原本应该及时总结的比赛搁置了,总结来说还是得多练,因为时间很短像这种线下赛,一般只有几个小时,所以思路一定要清晰,我还是经验太少了,导致比赛力不从心,先鸽了~ S ...
- Sealos 基础教程:Sealos Devbox 的架构原理解析
今天这篇文章咱们来聊一聊 Sealos Devbox 到底是怎么设计的,据说隔壁老奶奶最喜欢看这种有技术深度的文章了. Devbox 返璞归真,把开发者的开发精力放到开发中去,真正做到了摈弃复杂的 C ...
- 实时数仓及olap可视化构建(基于mysql,将maxwell改成seatunnel可以快速达成异构数据源实时同步)
1. OLAP可视化实现(需要提前整合版本) Linux121 Linux122 Linux123 jupyter spark python3+SuperSet3.0 hive ClinckHouse ...
- Gitlab运维操作
部署 安装Postfix以发送通知邮件 yum install postfix 将postfix服务设置成开机自启动 systemctl enable postfix 启动postfix system ...
- 使用Microsoft.Extensions.AI简化.NET中的AI集成
项目介绍 Microsoft.Extensions.AI是一个创新的 .NET 库,它为平台开发人员提供了一个内聚的 C# 抽象层,简化了与大型语言模型 (LLMs) 和嵌入等 AI 服务的交互.它支 ...
- pnpm 是如何颠覆 npm 和 yarn 的?
今天研究了一下 pnpm 的机制,发现它确实很强大,甚至可以说对 yarn 和 npm 形成了降维打击 . 我们从包管理工具的发展历史,一起看下到底好在哪里? npm2 在 npm 3.0 版本之前, ...
- ClickHouse之基础使用
[安装] [YUM] 1.添加官方存储库 sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://packag ...
- [NET,C# ] Nuget包发布流程
1.新建一个.NET Core类库 2.新增一个方法,并编译项目 3.下载Nuget.exe,与刚才新建的类库放在同一目录下 下载地址:https://www.nuget.org/downloads ...