RandomAccessFile、FileInputStream、MappedByteBuffer、FileChannel 区别及应用场景
RandomAccessFile、FileInputStream、MappedByteBuffer、FileChannel 比较
这些类都是Java中用于文件I/O操作的类,但各有特点和适用场景。下面我将详细介绍它们的区别、使用场景以及相关类。
主要区别
| 类/接口 | 特点 | 线程安全 | 性能 | 功能丰富度 |
|---|---|---|---|---|
| RandomAccessFile | 可随机读写,功能全面但API较老 | 是 | 中 | 高 |
| FileInputStream | 只能顺序读取,简单易用 | 是 | 中 | 低 |
| MappedByteBuffer | 内存映射文件,高性能随机访问 | 否 | 高 | 中 |
| FileChannel | NIO的核心通道,支持多种操作(传输、锁定、内存映射等),功能强大且灵活 | 是 | 高 | 高 |
详细说明及使用场景
1. RandomAccessFile
特点:
- 可读可写,支持随机访问(通过seek()方法)
- 支持基本数据类型(如readInt(), writeDouble()等)
- 基于文件指针操作
使用场景:
- 需要同时读写文件的场景
- 需要随机访问文件的场景(如数据库实现)
- 需要操作基本数据类型的场景
示例:
https://www.cnblogs.com/vipsoft/p/16252698.html
断点续传(上传)Java版: https://www.cnblogs.com/vipsoft/p/15951660.html
RandomAccessFile raf = new RandomAccessFile("file.txt", "rw");
raf.seek(100); // 移动到第100字节
raf.writeInt(123);
raf.close();
2. FileInputStream
特点:
- 只能顺序读取,不能写入
- 简单的字节流读取
- 通常与BufferedInputStream配合使用提高性能
使用场景:
- 只需顺序读取文件的简单场景
- 读取小文件
- 与其他装饰器流配合使用(如BufferedInputStream)
示例:
FileInputStream fis = new FileInputStream("file.txt");
byte[] buffer = new byte[1024];
int bytesRead = fis.read(buffer);
fis.close();
3. MappedByteBuffer
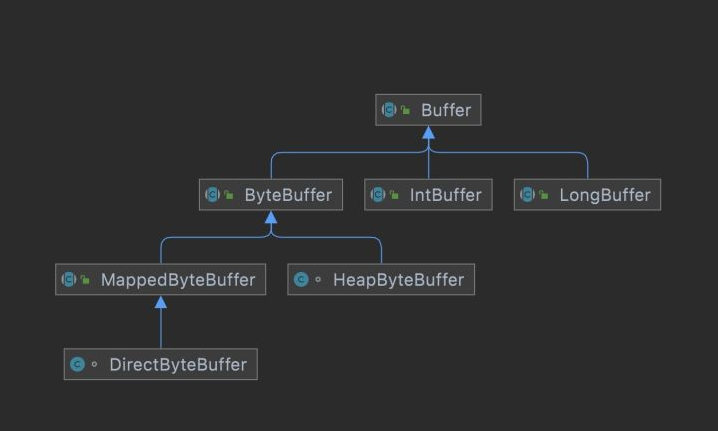
特点:
- 通过内存映射文件提供高性能访问
- 直接操作内存,避免了用户空间和内核空间的数据拷贝
- 适合大文件操作
- 非线程安全
使用场景:
- 需要高性能随机访问大文件
- 内存数据库实现
- 文件共享场景
示例:
https://www.cnblogs.com/vipsoft/p/16533152.html
https://www.cnblogs.com/vipsoft/p/16458161.html
RandomAccessFile file = new RandomAccessFile("largefile.dat", "rw");
FileChannel channel = file.getChannel();
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, channel.size());
// 直接操作buffer
buffer.put(0, (byte)123);
buffer.force(); // 强制刷新到磁盘
4. FileChannel
特点:
- NIO的核心文件操作类
- 支持多种高级功能:文件锁定、内存映射、分散/聚集I/O、文件间传输等
- 通常比传统I/O性能更好
- 线程安全
使用场景:
- 需要高性能文件操作的场景
- 需要文件锁定的场景
- 大文件传输(transferTo/transferFrom)
- 与Selector配合实现非阻塞I/O(虽然文件通道不能完全非阻塞)
示例:
RandomAccessFile file = new RandomAccessFile("file.txt", "rw");
FileChannel channel = file.getChannel();
// 文件锁定
FileLock lock = channel.lock();
// 文件传输
FileChannel destChannel = new FileOutputStream("dest.txt").getChannel();
channel.transferTo(0, channel.size(), destChannel);
channel.close();
相关联的重要类
- BufferedInputStream/BufferedOutputStream:提供缓冲功能,提高I/O性能
- BufferedReader/BufferedWriter:提供字符缓冲功能,支持按行读写
- FileOutputStream:对应FileInputStream的写入类
- ByteBuffer:NIO中的缓冲区类,与Channel配合使用 https://www.cnblogs.com/vipsoft/p/16547142.html
- Selector:NIO多路复用器,用于非阻塞I/O(虽然文件通道不完全支持)
- Files (Java 7+ NIO.2):提供很多实用静态方法操作文件
- Path/Paths (Java 7+ NIO.2):现代文件路径操作类
- AsynchronousFileChannel (Java 7+):异步文件通道
- FileLock:文件锁定功能: https://www.cnblogs.com/vipsoft/p/16540562.html
性能比较
一般来说性能排序(从高到低):
- MappedByteBuffer (内存映射文件)
- FileChannel (特别是使用transferTo/transferFrom时)
- BufferedInputStream/BufferedOutputStream (有缓冲)
- RandomAccessFile
- 原始FileInputStream/FileOutputStream (无缓冲)
选择建议
- 简单读取:FileInputStream + BufferedInputStream
- 需要随机访问:RandomAccessFile 或 FileChannel + MappedByteBuffer
- 高性能需求:FileChannel + MappedByteBuffer
- 大文件传输:FileChannel的transferTo/transferFrom
- 现代Java开发:优先考虑NIO.2 (Java 7+)的Files和Path API
Java 7引入的NIO.2 (java.nio.file包)提供了更现代的API,对于新项目推荐优先考虑使用这些新API。
在 Java 中,你可以使用 RandomAccessFile 或 FileInputStream 来从指定偏移量(offset)读取指定长度的字节数据。以下是两种实现方式:
方法 1:使用 RandomAccessFile(推荐)
RandomAccessFile 可以直接跳转到文件的指定位置进行读取,适合随机访问文件。
import java.io.IOException;
import java.io.RandomAccessFile;
public class ReadFileFromOffset {
public static void main(String[] args) {
String filePath = "your_file.bin"; // 替换为你的文件路径
int offset = 10; // 起始偏移量
int length = 2; // 要读取的字节数
try (RandomAccessFile raf = new RandomAccessFile(filePath, "r")) {
// 跳转到指定偏移量
raf.seek(offset);
// 读取指定长度的字节
byte[] buffer = new byte[length];
int bytesRead = raf.read(buffer);
if (bytesRead != length) {
System.err.println("未能读取足够字节,可能已到文件末尾");
} else {
System.out.println("读取的字节数据: " + bytesToHex(buffer));
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 辅助方法:将字节数组转为十六进制字符串(方便查看)
private static String bytesToHex(byte[] bytes) {
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(String.format("%02X ", b));
}
return sb.toString();
}
}
方法 2:使用 FileInputStream
FileInputStream 也可以读取指定偏移量的数据,但需要手动跳过前面的字节。
import java.io.FileInputStream;
import java.io.IOException;
public class ReadFileFromOffsetWithStream {
public static void main(String[] args) {
String filePath = "your_file.bin"; // 替换为你的文件路径
int offset = 10; // 起始偏移量
int length = 2; // 要读取的字节数
try (FileInputStream fis = new FileInputStream(filePath)) {
// 跳过 offset 之前的字节
long skipped = fis.skip(offset);
if (skipped != offset) {
System.err.println("无法跳过足够字节,可能文件太小");
return;
}
// 读取指定长度的字节
byte[] buffer = new byte[length];
int bytesRead = fis.read(buffer);
if (bytesRead != length) {
System.err.println("未能读取足够字节,可能已到文件末尾");
} else {
System.out.println("读取的字节数据: " + bytesToHex(buffer));
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 辅助方法:将字节数组转为十六进制字符串
private static String bytesToHex(byte[] bytes) {
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(String.format("%02X ", b));
}
return sb.toString();
}
}
关键点说明
RandomAccessFilevsFileInputStream:RandomAccessFile更适合随机访问(如频繁跳转偏移量)。FileInputStream适用于顺序读取,但也可以手动skip()到指定位置。
seek(offset)和skip(offset):RandomAccessFile.seek(offset)直接定位到offset。FileInputStream.skip(offset)跳过offset字节,但可能受流限制(如网络流可能无法跳过)。
字节读取:
read(byte[])返回实际读取的字节数,可能小于请求的长度(如文件末尾)。
异常处理:
- 需处理
IOException(如文件不存在或权限问题)。
- 需处理
字节转十六进制:
- 示例代码提供了
bytesToHex()方法方便查看字节数据(如1A 2B)。
- 示例代码提供了
输出示例
如果文件 your_file.bin 在 offset=10 处的 2 个字节是 0x41 和 0x42(即 ASCII 字符 A 和 B),输出:
读取的字节数据: 41 42
适用场景
- 读取二进制文件(如
.bin、.dat)。 - 解析文件头、特定偏移量的数据(如文件格式解析)。
- 网络协议解析(如从固定位置读取字段)。
如果需要更复杂的文件操作(如内存映射),可以考虑 java.nio 的 FileChannel 和 MappedByteBuffer。
RandomAccessFile、FileInputStream、MappedByteBuffer、FileChannel 区别及应用场景的更多相关文章
- list set map区别及适用场景
list与Set.Map区别及适用场景 1.List,Set都是继承自Collection接口,Map则不是 2.List特点:元素有放入顺序,元素可重复 ,Set特点:元素无放入顺序,元素不可重 ...
- session,cookie,sessionStorage,localStorage的区别及应用场景
session,cookie,sessionStorage,localStorage的区别及应用场景 浏览器的缓存机制提供了可以将用户数据存储在客户端上的方式,可以利用cookie,session等跟 ...
- Java内存的 静态方法和实例方法的区别及使用场景
注意:变量指基本数据类型非对象,局部变量不能被静态修饰 1.(静态)成员变量存放在data segment区(数据区),字符串常量也存放在该区 2.非静态变量,new出来的对象存放在堆内存,所有局部变 ...
- 【转】ArrayList与LinkedList的区别和适用场景
ArrayList 优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的). 缺点:因为地址连续,当要插入和删除时,Arra ...
- Java RandomAccessFile与MappedByteBuffer
Java RandomAccessFile与MappedByteBuffer https://www.cnblogs.com/guazi/p/6838915.html
- 转载>>C# Invoke和BeginInvoke区别和使用场景
转载>>C# Invoke和BeginInvoke区别和使用场景 一.为什么Control类提供了Invoke和BeginInvoke机制? 关于这个问题的最主要的原因已经是dotnet程 ...
- java 常用集合list与Set、Map区别及适用场景总结
转载请备注出自于:http://blog.csdn.net/qq_22118507/article/details/51576319 list与Set.Map区别及 ...
- hibernate与mybatis的区别和应用场景
mybatis 与 hibernate 的区别和应用场景(转) 1 Hibernate : 标准的ORM(对象关系映射) 框架: 不要用写sql, sql 自动语句生成: 使用Hibernate ...
- mybatis由浅入深day01_ 4.11总结(parameterType_resultType_#{}和${}_selectOne和selectList_mybatis和hibernate本质区别和应用场景)
4.11 总结 4.11.1 parameterType 在映射文件中通过parameterType指定输入参数的类型.mybatis通过ognl从输入对象中获取参数值拼接在sql中. 4.11.2 ...
- 为什么要使用索引?-Innodb与Myisam引擎的区别与应用场景
Innodb与Myisam引擎的区别与应用场景 http://www.cnblogs.com/changna1314/p/6878900.html https://www.cnblogs.com/ho ...
随机推荐
- MySQL - [08] 存储过程
题记部分 一.什么是存储过程 存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效 ...
- Git错误合集 | git工作上遇到的那些报错
前言 我总是在git提交的时候,遇到一些奇奇怪怪的问题.有时候居然还会碰上第二次. 记住这些"绊脚石",下回不摔跤. 目录 git index损坏 一.git index损坏 报错 ...
- linux服务器压力/性能测试命令
linux命令下使用ab -c500 -n2000 http://www.test.cn 进行压力测试 在Linux命令行中,ab 是 Apache HTTP server benchmarki ...
- 李沐动手学深度学习V2-chapter_convolutional-modern
李沐动手学深度学习V2 文章内容说明 本文主要是自己学习过程中的随手笔记,需要自取 课程参考B站:https://space.bilibili.com/1567748478?spm_id_from=3 ...
- surpac 中如何删除点
找到显示的编号 输入线窜线段编号
- Ubuntu安装配置redis
更新安装相关依赖库 下面步骤一步一步来 sudo apt update sudo apt install build-essential sudo apt-get install manpages-d ...
- jquery的radio的change事件
一.用的jquery的radio的change事件:当元素的值发生改变时,会发生 change 事件,radio选择不同name值选项的时候恰巧是值发生改变 表单单选框 <input type= ...
- VLAN聚合技术:Super-vlan
Super-VLAN,也称为VLAN聚合(VLAN Aggregation),是一种网络配置技术,主要用于优化IP地址资源的利用和隔离广播域. 一.定义与功能 Super-VLAN是通过将多个VLAN ...
- 【Azure Developer】分享两段Python代码处理表格(CSV格式)数据 : 根据每列的内容生成SQL语句
问题描述 在处理一个数据收集工作任务上,收集到的数据内容格式都不能直接对应到数据库中的表格内容. 比如: 第一种情况:服务名作为第一列内容,然后之后每一列为一个人名,1:代表此人拥有这个服务,0:代表 ...
- 使用 vscode-jest 插件
vscode-jest [error] Abort jest session: Not able to auto detect a valid jest command: multiple candi ...