TF-IDF计算方法和基于图迭代的TextRank
文本处理方法概述
说明:本篇以实践为主,理论部分会尽量给出参考链接
摘要:
1.分词
2.关键词提取
3.主题模型(LDA/TWE)
4.词的两种表现形式(词袋模型和分布式词向量)
5.关于文本的特征工程
6.文本挖掘(文本分类,文本用户画像)
内容:
1.分词
分词是文本处理的第一步,词是语言的最基本单元,在后面的文本挖掘中无论是词袋表示还是词向量形式都是依赖于分词的,所以一个好的分词工具是非常重要的。
这里以python的jieba分词进行讲解分词的基本流程,在讲解之前还是想说一下jieba分词的整个工作流程:
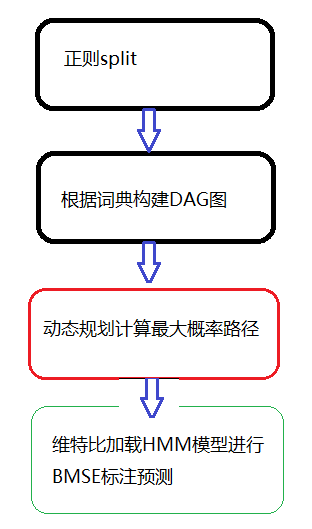
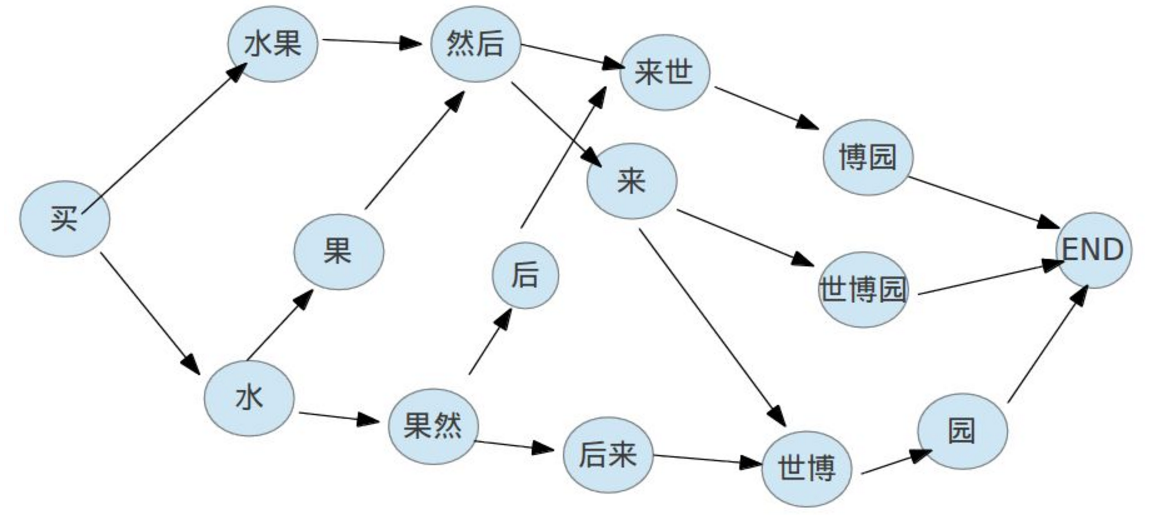
图1是jieba切词函数的4个可能过程,图2是一个根据DAG图计算最大概率路径,具体的代码走读请参考jieba cut源码讲了这么多,我们还是要回归到实践中去,看下jieba的分词接口

1 # encoding=utf-8
2 import jieba
3
4 seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
5 print("Full Mode: " + "/ ".join(seg_list)) # 全模式
9
10 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
11 print(", ".join(seg_list))
12
13 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
14 print(", ".join(seg_list))
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
其中全模式切词不会发生图1中的第3,4步,也不会发现新词,是一种完全依赖于词典的分词方式
精确模式是会全部计算最大概率路径和新词发现的。
我们都知道分词最重要的是字典,所以jieba也提供了若干方法对词典进行设置:
jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
#词典文件举例:
#创新办 3 i
#云计算 5
#凱特琳 nz
#台中 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来
2.关键词提取
文本被分词之后和数据处理一样,也会有如下两个问题:
其一,并不是所有的词都是有用的;其二,一个语料库的词量是非常大的,传统的文本挖掘方法又是基于向量空间模型表示的,所以这会造成数据过于稀疏。
为了解决这两个问题一般会进行停用词过滤和关键字提取,而后者现有基于频率的TF-IDF计算方法和基于图迭代的TextRank的计算方法两种。下面看看这两种方法是怎么工作的

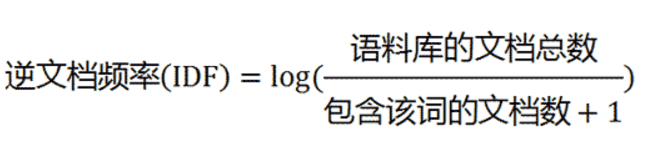
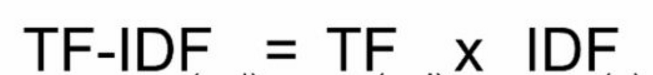
这里TF表示词在文章中的重要性,因为我们知道一个文章的主题一多次出现;IDF表示词的区分度,因为专业词汇在整个语料库中出现越少,越能关联文章主题。具体来说就是信息熵越低。
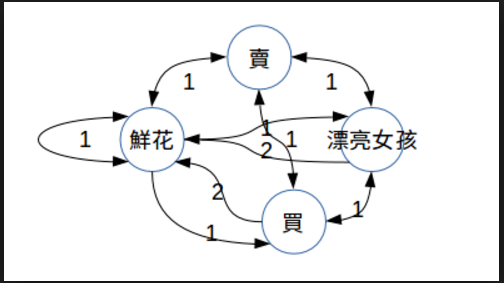
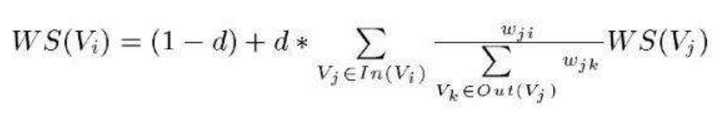
图1是一个文章的上下文词构造的无向加权图(UWG),图2是叶结点的权重迭代公式,其中d是阻尼系数。可见textRank认为一个节点如果入度多且权重大,那么这个节点越重要。
具体理论和代码走读参考: 关键词抽取源码,TextRank: Bringing Order into Texts;下面我们就动手试试吧!
import jieba.analyse #设置停词表路径
jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径 #默认tfidf提取关键词
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
#sentence 为待提取的文本
#topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
#withWeight 为是否一并返回关键词权重值,默认值为 False
#allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) #新建 TFIDF 实例,idf_path 为 IDF 频率文件 #textrank提取关键词
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
上面jieba的TFIDF是通过需要指定IDF文件预先指定词的IDF值的,同时textrank中比较重要的参数有一个上下文窗口。jieba通过了这两个方法让我们筛选出前多少个关键词。然而sklearn提供了一种构建文档词矩阵(稀疏矩阵)的方法,可以让我们直接构建文本训练集。
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> vectorizer = TfidfVectorizer()
>>> vectorizer.fit_transform(corpus)
...
<4x9 sparse matrix of type '<... 'numpy.float64'>'
with 19 stored elements in Compressed Sparse ... format>
待续~~~
TF-IDF计算方法和基于图迭代的TextRank的更多相关文章
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- 用PersonalRank实现基于图的推荐算法
今天我们讲一个下怎么使用随机游走算法PersonalRank实现基于图的推荐. 在推荐系统中,用户行为数据可以表示成图的形式,具体来说是二部图.用户的行为数据集由一个个(u,i)二元组组成,表示为用户 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 基于图的图像分割(Graph-Based Image Segmentation)
一.介绍 基于图的图像分割(Graph-Based Image Segmentation),论文<Efficient Graph-Based Image Segmentation>,P. ...
- 推荐系统之基于图的推荐:基于随机游走的PersonalRank算法
转自http://blog.csdn.net/sinat_33741547/article/details/53002524 一 基本概念 基于图的模型是推荐系统中相当重要的一种方法,以下内容的基本思 ...
- 图像切割—基于图的图像切割(Graph-Based Image Segmentation)
图像切割-基于图的图像切割(Graph-Based Image Segmentation) Reference: Efficient Graph-Based Image Segmentation ...
随机推荐
- lighttpd启动不了,libssl.so.4&libcrypto.so.4 缺失
lighttd的出错日志在 log/out_lighttpd 里,当lighttd启动不了时候,这里文件中会说明原因. 今天的报错是 error while loading shared librar ...
- android图像处理系列之七--图片涂鸦,水印-图片叠加
图片涂鸦和水印其实是一个功能,实现的方式是一样的,就是一张大图片和一张小点图片叠加即可.前面在android图像处理系列之六--给图片添加边框(下)-图片叠加中也讲到了图片叠加,里面实现的原理是直接操 ...
- 洛谷 P1313 计算系数
题目描述 给定一个多项式(by+ax)^k,请求出多项式展开后x^n*y^m 项的系数. 输入输出格式 输入格式: 输入文件名为factor.in. 共一行,包含5 个整数,分别为 a ,b ,k , ...
- Linux下基于LDAP统一用户认证的研究
Linux下基于LDAP统一用户认证的研究 本文出自 "李晨光原创技术博客" 博客,谢绝转载!
- Linux shell command学习笔记(一)
Shell的种类有很多种,例如CSH,Bourne Shell,Korn Shell.在现在的大多数Linux发行版中,默认的Shell一般都是Bourne again shell(bash). &l ...
- 【Good Bye 2017 A】New Year and Counting Cards
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 是元音字母或者是奇数就递增. [代码] #include <bits/stdc++.h> using namespace ...
- [Node & Testing] Intergration Testing with Node Express
We have express app: import _ from 'lodash' import faker from 'faker' import express from 'express' ...
- Matrix学习——基础知识
以前在线性代数中学习了矩阵,对矩阵的基本运算有一些了解,前段时间在使用GDI+的时候再次学习如何使用矩阵来变化图像,看了之后在这里总结说明. 首先大家看看下面这个3 x 3的矩阵,这个矩阵被分割成4部 ...
- RGB颜色转换为多种颜色工具、公式
http://www.easyrgb.com/index.php?X=CALC#Result http://www.easyrgb.com/index.php?X=MATH
- Mine Vison base on VC++ and procilica Gige Vison SDK
This is my first vision base on VC++6.0. I am so happy to record this time i succesfully create it b ...