caffe中lenet_train_test.prototxt配置文件注解
caffe框架下的lenet.prototxt定义了一个广义上的LeNet模型,对MNIST数据库进行训练实际使用的是lenet_train_test.prototxt模型。
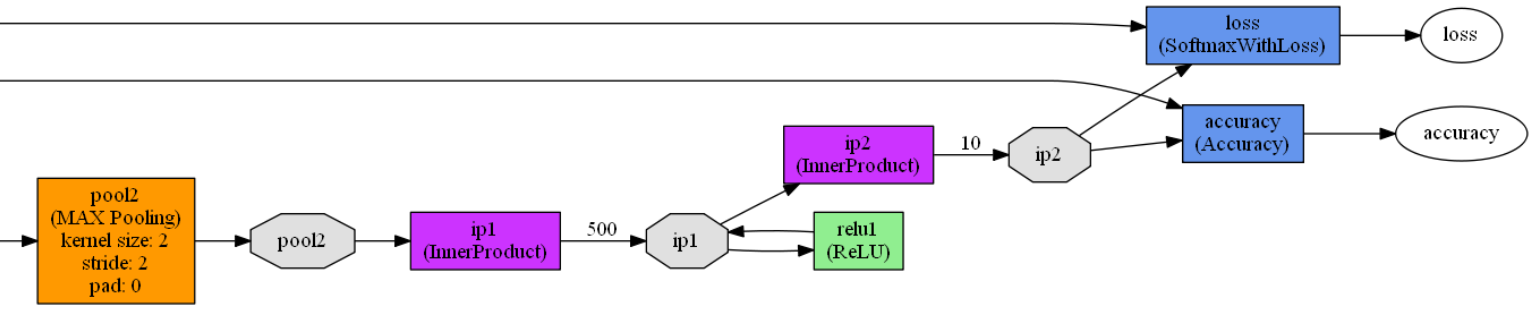
lenet_train_test.prototxt模型定义了一个包含2个卷积层,2个池化层,2个全连接层,1个激活函数层的卷积神经网络模型,模型如下:

name: "LeNet" //神经网络的名称是LeNet
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在训练阶段有效
phase: TRAIN
}
transform_param {
scale: 0.00390625 //归一化参数,输入的数据都是需要乘以该参数(1/256)
//由于图像数据上的像素值大小范围是0~255,这里乘以1/256
//相当于把输入归一化到0~1
}
data_param {
source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_train_lmdb" //训练数据的路径
batch_size: 64 //每批次训练样本包含的样本数
backend: LMDB //数据格式(后缀)定义为LMDB,另一种数据格式是leveldb
}
}
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在测试阶段有效
phase: TEST
}
transform_param {
scale: 0.00390625 //归一化系数是1/256,数据都归一化到0~1
}
data_param {
source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_test_lmdb" //测试数据路径
batch_size: 100 //每批次测试样本包含的样本数
backend: LMDB //数据格式(后缀)是LMDB
}
}
layer { //定义一个网络层
name: "conv1" //网络层的名称是conv1
type: "Convolution" //网络层的类型是卷积层
bottom: "data" //网络层的输入是data
top: "conv1" //网络层的输出是conv1
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 20 //输出是20个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "pool1" //网络层的名称是pool1
type: "Pooling" //网络层的类型是池化层
bottom: "conv1" //网络层的输入是conv1
top: "pool1" //网络层的输出是pool1
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "conv2" //网络层的名称是conv2
type: "Convolution" //网络层的类型是卷积层
bottom: "pool1" //网络层的输入是pool1
top: "conv2" //网络层的输出是conv2
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 50 //输出是50个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "pool2" //网络层的名称是pool2
type: "Pooling" //网络层的类型是池化层
bottom: "conv2" //网络层的输入是conv2
top: "pool2" //网络层的输出是pool2
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "ip1" //网络层的名称是ip1
type: "InnerProduct" //网络层的类型是全连接层
bottom: "pool2" //网络层的输入是pool2
top: "ip1" //网络层的输出是ip1
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 500 //输出是一个500维的向量
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "relu1" //网络层的名称是relu1
type: "ReLU" //网络层的类型是激活函数层
bottom: "ip1" //网络层的输入是ip1
top: "ip1" //网络层的输出是ip1
}
layer { //定义一个网络层
name: "ip2" //网络层的名称是ip2
type: "InnerProduct" //网络层的类型是全连接层
bottom: "ip1" //网络层的输入是ip1
top: "ip2" //网络层的输出是ip2
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 10 //输出是一个10维的向量,即0~9的数字
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "accuracy" //网络层的名称是accuracy
type: "Accuracy" //网络层的类型是准确率层
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "accuracy" //网络层的输出是accuracy
include { //定义该网络层只在测试阶段有效
phase: TEST
}
}
layer { //定义一个网络层
name: "loss" //网络层的名称是loss
type: "SoftmaxWithLoss" //网络层的损失函数采用Softmax计算
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "loss" //网络层的输出是loss
} caffe中lenet_train_test.prototxt配置文件注解的更多相关文章
- caffe中lenet_solver.prototxt配置文件注解
caffe框架自带的例子mnist里有一个lenet_solver.prototxt文件,这个文件是具体的训练网络的引入文件,定义了CNN网络架构之外的一些基础参数,如总的迭代次数.测试间隔.基础学习 ...
- [转]caffe中solver.prototxt参数说明
https://www.cnblogs.com/denny402/p/5074049.html solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是so ...
- 浅谈caffe中train_val.prototxt和deploy.prototxt文件的区别
本文以CaffeNet为例: 1. train_val.prototxt 首先,train_val.prototxt文件是网络配置文件.该文件是在训练的时候用的. 2.deploy.prototxt ...
- Caffe中deploy.prototxt 和 train_val.prototxt 区别
之前用deploy.prototxt 还原train_val.prototxt过程中,遇到了坑,所以打算总结一下 本人以熟悉的LeNet网络结构为例子 不同点主要在一前一后,相同点都在中间 train ...
- caffe中通过prototxt文件查看神经网络模型结构的方法
在修改propotxt之前我们可以对之前的网络结构进行一个直观的认识: 可以使用http://ethereon.github.io/netscope/#/editor 这个网址. 将propotxt文 ...
- caffe 中solver.prototxt
关于cifar-10和mnist的weight_decay和momentum也是相当的重要:就是出现一次把cifar-10的两个值直接用在mnist上,发现错误很大.
- caffe mnist实例 --lenet_train_test.prototxt 网络配置详解
1.mnist实例 ##1.数据下载 获得mnist的数据包,在caffe根目录下执行./data/mnist/get_mnist.sh脚本. get_mnist.sh脚本先下载样本库并进行解压缩,得 ...
- caffe中LetNet-5卷积神经网络模型文件lenet.prototxt理解
caffe在 .\examples\mnist文件夹下有一个 lenet.prototxt文件,这个文件定义了一个广义的LetNet-5模型,对这个模型文件逐段分解一下. name: "Le ...
- Windows下使用python绘制caffe中.prototxt网络结构数据可视化
准备工具: 1. 已编译好的pycaffe 2. Anaconda(python2.7) 3. graphviz 4. pydot 1. graphviz安装 graphviz是贝尔实验室开发的一个 ...
随机推荐
- awesome-free-software
Free software is distributed under terms that allow users to run the program for any purpose, study ...
- tcpdump dns流量监控
tcpdump监听数据 为了看清楚DNS通信的过程,下面我们将从主机1:192.168.0.141上运行host命令以查询主机www.jd.com对应的IP地址,并使用tcpdump抓取这一过程中LA ...
- DNS查询报文实例
2.2 DNS查询报文实例 以www.baidu.com为例,用Wireshark俘获分组,结合2.1的理论内容,很容易看明白的,DNS请求报文如下: 图7 DNS请求报文示例 2.3 DNS回答报文 ...
- USACO 1.5 Superprime Rib
Superprime Rib Butchering Farmer John's cows always yields the best prime rib. You can tell prime ri ...
- oracle RAC 11g sqlload 生产表导入数据(ORA-12899)
背景:由于即将来临的双十一,业务部门(我司是做京东,天猫的短信服务),短信入库慢,需要DBA把数据库sqlload进数据库. 表结构如下: MRS VARCHAR2(100), STATUS VARC ...
- HttpClient简单操作
HttpClient 这个框架主要用来请求第三方服务器,然后获取到网页,得到我们需要的数据: HttpClient设置请求头消息User-Agent模拟浏览器 比如我们请求 www.tuicool.c ...
- webapi+DataTables
webapi + datatables 前言 之前写过一个关于DataTables的记录,是之前做webform的时候从后台一次性生成html代码,有很多弊端,就不多说了. 这次把最近研究的DataT ...
- SQL学习——基础语句(4)
前面感觉真的好乱,想哪,写哪.这里慢慢整理…… SQL Having 语句 还是前面的那两个表: grade表: student表: 我们需要查找这里的s_id下的gradeValue的和,这就要分组 ...
- iOS开发者账号证书配置及相关工作
申请到开发者账号,肯定要先配置一下才可以使用,这主要是iOS证书及配置文件: 以下这篇文章写得比较全面,故不再累赘,需要的同学可以看一下: iOS开发证书与配置文件的使用
- pgpool中定义的数据库节点及pgpool支持的复制模式
/* * The first DB node id appears in pgpool.conf or the first "live" DB * node otherwise. ...