Flume安装部署
Flume安装部署
- Flume的安装(非常简单)
上传安装包到数据源所在节点上,实际上不是数据源节点也是可以的,只要运行Flume的这台机器与数据源节点的这台机器能够通过某种协议进行通信即可。
然后解压tar –zxvf apache-flume-1.8.0-bin.tar.gz,并修改(mv)文件名为flume
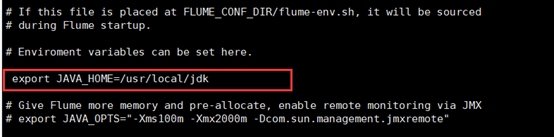
然后进入flume的目录,修改conf下的flume-env.sh,没有的话复制(cp)flume-env.sh.template,在里面配置JAVA_HOME为jdk的根目录。
- 根据数据采集需求配置采集方案,描述在配置文件中(文件名可任意自定义)
- 指定采集方案配置文件,在相应的节点上启动flume agent
先用一个最简单的例子来测试一下程序环境是否正常。重点是体会一下Flume三个组件之间该怎么配置。
需求:往一个网络端口上发送数据,Flume监听该端口,把这个端口里面接收到的数据收集起来,并下沉到终端上以日志的形式打印出来。
1、 配置采集方案(在flume的conf目录下新建一个文件)
vi netcat-logger.conf(命名规则:source-sink.conf)
#从网络端口接受数据,下沉到logger
#采集配置文件,netcat-logger.conf #定义这个agent中各组件的名字
a1.sources=r1
a1.sinks=k1
a1.channels=c1 #描述和配置source组件:r1
# netcat类型用来监听端口数据源
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444 #描述和配置sink组件:k1
a1.sinks.k1.type=logger #描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100 #描述和配置source channel sink之间的连接关系
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2、 启动agent去采集数据
bin/flume-ng agent -c conf –f conf /netcat-logger.conf –n a1 -Dflume.root.logger=INFO,console
示例:
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
解释1:
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.conf 指定我们所描述的采集方案
-n a1 指定本次启动agent的名字,与采集方案配置文件中一致
解释2:
-c (或--conf) : flume自身所需的conf文件路径
-f (--conf-file) : 自定义的flume配置文件,也就是采集方案文件
-n (--name): 自定义的flume配置文件中agent的name
3、 测试
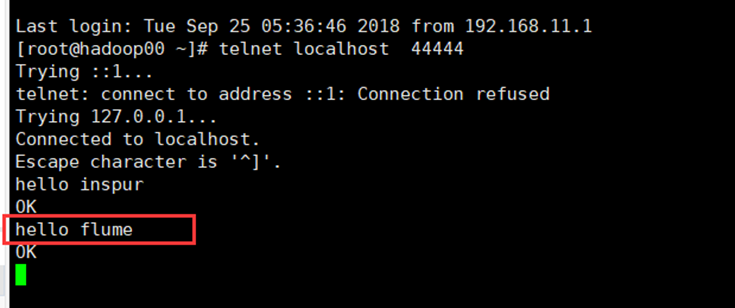
先要往agent采集监听的端口上发送数据,让agent有数据可采。
随便在一个能跟agent节点联网的机器上,也可以在本机:telnet agent-hostname port (如:telnet localhost 44444)
注意:如果telnet还没有安装,则需要执行yum install -y telnet进行安装

Flume安装部署的更多相关文章
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- Flume —— 安装部署
一.前置条件 Flume需要依赖JDK 1.8+,JDK安装方式见本仓库: Linux环境下JDK安装 二 .安装步骤 2.1 下载并解压 下载所需版本的Flume,这里我下载的是CDH版本的Flum ...
- Flume NG安装部署及数据采集测试
转载请注明出处:http://www.cnblogs.com/xiaodf/ Flume作为日志收集工具,监控一个文件目录或者一个文件,当有新数据加入时,采集新数据发送给消息队列等. 1 安装部署Fl ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- 02_ Flume的安装部署及其简单使用
一.Flume的安装部署: Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 安装包的下载地址为:http://www-us.apache.org/dist/flume/1. ...
- 2 安装部署flume
本文对flume进行安装部署 flume是什么?传送门:https://www.cnblogs.com/zhqin/p/12230301.html 0.要安装部署在日志所在的服务器,或者把日志发送到日 ...
- flume 1.8 安装部署
环境 centos:7.2 JDK:1.8 Flume:1.8 一.Flume 安装 1) 下载 wget http://mirrors.tuna.tsinghua.edu.cn/apa ...
随机推荐
- bzoj4753
bzoj4753 树形dp+01分数规划 这是一个典型的树形背包+01分数规划.看见分数形式最大就应该想到01分数规划. 于是套用分数规划,每次用树形背包检验. 首先这是一棵树,不是一个森林,所以我们 ...
- Gym - 101208C 2013 ACM-ICPC World Finals C.Surely You Congest 最大流+最短路
题面 题意:给你n(2w5)个点,m条边(7w5)有k(1e3)辆车停在某些点上的,然后他们都想尽快去1号点,同时出发,同一个点不允许同时经过, 如果多辆车同时到达一个点,他们就会堵塞,这时候只能选择 ...
- 解决input输入框在iOS中有阴影问题
input{ -webkit-appearance: none; }
- Android数据存储的5种方法
--使用SharedPreferences存储数据 --文件存储数据 --SQLite数据库存储数据 --使用ContentProvider存储数据 --网络存储数据 Preference,File, ...
- 51nod 1340 差分约束
思路: 带未知量的Floyd 很强 http://yousiki.net/index.php/archives/87/ //By SiriusRen #include <bits/stdc++. ...
- 【LeetCode】-- 73. Set Matrix Zeroes
问题描述:将二维数组中值为0的元素,所在行或者列全set为0:https://leetcode.com/problems/set-matrix-zeroes/ 问题分析:题中要求用 constant ...
- 查询分析器执行SQL很快但是ado.net很慢:请为你的SQLparameter设置DbType
我们都知道,参数化查询可以处理SQL注入,以及提高查询的效率,因为参数化查询会使MSSQL缓存查询的计划. 但是会出现一个问题:有的时候参数化查询比直接拼接sql字符串效率低好多,甚至是查询超时. 原 ...
- Java系列学习(零)-写在前面的话
1.为什么写这套笔记 理由一:因为需求,所以学习,然后就要记笔记 理由二:同时学几种相似的语言,怕搞混,所以写 2.笔记修改日志
- Json解析与Gson解析
本文主要介绍json最原始的解析与google提供的gson工具类解析 ①json解析 /** * 普通的json解析 * @param s * @throws JSONException */ pr ...
- C#入门经典 Chapter3 变量和表达式
3.1 C#基本语法 分号结束语句 花括号字符不需要附带分号 缩进 注释:/*....*/,//,/// 区分大小写 3.2 C#控制台应用程序的基本结构 namespace Chapter3 ...