pandas之cut(),qcut()
功能:将数据进行离散化
可参见博客:https://blog.csdn.net/missyougoon/article/details/83986511 , 例子简易好懂

>>> factors = np.random.randn(9)
[ 2.12046097 0.24486218 1.64494175 -0.27307614 -2.11238291 2.15422205 -0.46832859 0.16444572 1.52536248]
传入bins参数
>>> pd.cut(factors, 3) #返回每个数对应的分组
[(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]]
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]] >>> pd.cut(factors, bins=[-3,-2,-1,0,1,2,3])
[(2, 3], (0, 1], (1, 2], (-1, 0], (-3, -2], (2, 3], (-1, 0], (0, 1], (1, 2]]
Categories (6, interval[int64]): [(-3, -2] < (-2, -1] < (-1, 0] < (0, 1] (1, 2] < (2, 3]] >>> pd.cut(factors, 3).value_counts() #计算每个分组中含有的数的数量
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]]
(-2.117, -0.69] 1
(-0.69, 0.732] 4
(0.732, 2.154] 4
传入lable参数
>>> pd.cut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示
[c, b, c, b, a, c, b, b, c]
Categories (3, object): [a < b < c] >>> pd.cut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标
[2 1 2 1 0 2 1 1 2]
传入retbins参数
>>> pd.cut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值
([(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]]
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]], array([-2.11664951, -0.69018126, 0.7320204 , 2.15422205]))
>>> pd.qcut(factors, 3) #返回每个数对应的分组
[(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]]
Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154]] >>> pd.qcut(factors, 3).value_counts() #计算每个分组中含有的数的数量
(-2.113, -0.158] 3
(-0.158, 1.525] 3
(1.525, 2.154] 3
传入lable参数
>>> pd.qcut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示
[c, b, c, a, a, c, a, b, b]
Categories (3, object): [a < b < c] >>> pd.qcut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标
[2 1 2 0 0 2 0 1 1]
传入retbins参数
>>> pd.qcut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值
[(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]]
Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154],array([-2.113, -0.158 , 1.525, 2.154]))
另一个例子:
import numpy as np
from numpy import *
import pandas as pd
df = pd.DataFrame()
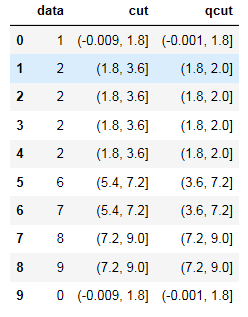
df['data'] = [1,2,2,2,2,6,7,8,9,0]#这里注意箱边界值需要唯一,不然qcut时程序会报错
df['cut']=pd.cut(df['data'],5)
df['qcut']=pd.qcut(df['data'],5)
df.head(10)
运行结果如图:
可以看到cut列各个分段之间间距相等,qcut由于数据中‘2’较多,所以2附近间距较小,2之后的分段间距较大。
pandas之cut(),qcut()的更多相关文章
- Pandas中的qcut和cut
qcut与cut的主要区别: qcut:传入参数,要将数据分成多少组,即组的个数,具体的组距是由代码计算 cut:传入参数,是分组依据.具体见示例 1.qcut方法,参考链接:http://panda ...
- pandas之cut
cut( )用来把一组数据分割成离散的区间. cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_low ...
- pandas的基本功能(一)
第16天pandas的基本功能(一) 灵活的二进制操作 体现在2个方面 支持一维和二维之间的广播 支持缺失值数据处理 四则运算支持广播 +add - sub *mul /div divmod()分区和 ...
- pandas的离散化,面元划分
pd.cut pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=, include_lowest=False) ...
- 利用Python进行数据分析-Pandas(第四部分-数据清洗和准备)
在数据分析和建模的过程中,相当多的时间要用在数据准备上:加载.清理.转换以及重塑上.这些工作会占到分析时间的80%或更多.有时,存储在文件和数据库中的数据的格式不适合某个特定的任务.研究者都选择使用编 ...
- pandas - groupby 深入及数据清洗案例
import pandas as pd import numpy as np 分割-apply-聚合 大数据的MapReduce The most general-purpose GroupBy me ...
- pandas 常规操作大全
那年夏天抓住了蝉的尾巴 gitbook 前言 pandas 抓住 Series (排序的字典), DataFrame (row + 多个 Series) 对象 , 就如同 numpy 里抓住 ndar ...
- 数据处理:12个使得效率倍增的pandas技巧
数据处理:12个使得效率倍增的pandas技巧 1. 背景描述 Python正迅速成为数据科学家偏爱的语言,这合情合理.它拥有作为一种编程语言广阔的生态环境以及众多优秀的科学计算库.如果你刚开始学习P ...
- pandas 初识(三)
Python Pandas 空值 pandas 判断指定列是否(全部)为NaN(空值) import pandas as pd import numpy as np df = pd.DataFrame ...
随机推荐
- IntelliJ IDEA测试学习网站
IntelliJ IDEA测试学习网站 http://idea.lanyus.com/ 嗯,请支持正版:
- Swift学习——变量var和let常量的用法(一)
Swift中的变量var和let常量 首先介绍一下Swift中的 var 和 let (1)var 是 variable的缩写形式,是变量的意思 ,是可改变的.并非数据类型 比如: 注意每一个语句后面 ...
- Java设计模式菜鸟系列(十五)建造者模式建模与实现
转载请注明出处:http://blog.csdn.net/lhy_ycu/article/details/39863125 建造者模式(Builder):工厂类模式提供的是创建单个类的模式.而建造者模 ...
- poj1426--Find The Multiple(广搜,智商题)
Find The Multiple Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 18527 Accepted: 749 ...
- 问题: Unsupported major.minor version 51.0
Unsupported major.minor version 51.0 问题原因:外部jar包使用jdk1.7(jdk7)编译,而使用此jar包的工程jdk版本为jdk1.6(jdk6),算是版本不 ...
- Tomcat启动时项目反复载入,导致资源初始化两次的问题
近期在项目开发測试的时候,发现Tomcat启动时项目反复载入,导致资源初始化两次的问题 导致该问题的解决办法: 例如以下图:在Eclipse中将Server Locations设置为"Us ...
- SwiftUI 官方教程(一)
完整中文教程及代码请查看 https://github.com/WillieWangWei/SwiftUI-Tutorials 创建和组合 View 此部分将指引你构建一个发现和分享您喜爱地方的 ...
- guice整合struts2,guice的使用(八)
平时我们习惯用了spring整合struts2,今天我们就来见识一下guice整合struts2吧. 看web.xml配置: <?xml version="1.0" enco ...
- APM技术原理
链接地址:http://www.infoq.com/cn/articles/apm-Pinpoint-practice 1.什么是APM? APM,全称:Application Performance ...
- shopping car 2.0
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/5/13 0013 10:20# @Author : Anthony.Waa# @ ...