数据分析例子-------CTR1
1、CTR:
(1)几个概念:
impression(展示):用户看到该广告的次数。也就是一个广告被显示了多少次,它就计数多少。比如:打开网站的一个页面,网站上的所有广告就被显示了一次,每个广告增加1个,如果刷新就再增加一个。
click(点击):用户点击该广告的次数
CTR:click through rate 广告点击率
CTR = click次数 / impression次数
(2)任务:
CTR预估任务:给定用户(user),给定一个商品(product),给定了一定的环境,来看用户会不会买这个商品,买该商品的概率有多高;或者说给用户推荐一个电影,用户会不会看这个电影。

这里要训练一个模型,X表示训练数据的输入,即各种特征,Y表示输出,Y的取值为1到5。
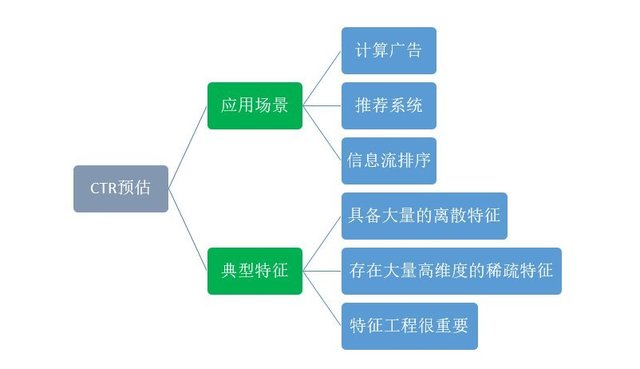
(3)应用:
计算广告、推荐系统、信息流排序。
计算广告:比如很多广告,用户会点击哪些?
推荐系统:推荐系统可以转化成CTR预估,比如电影推荐,用户会不会看?
信息流排序:百度头条微博都在做信息流,比如微博中你关注了很多人,他们会有很多信息发布出来,则优先给你展示哪些内容你可能会点呢?这涉及到怎么为那些推送给你的信息流进行重新排序。
2、广告中几种计费方式:
CPM:不管用户对该广告有任何行为(点击不点击),广告只要曝光就得收费,一般在游戏场景下用的比较多。
CPC:广告曝光后根据用户点击数量来收费,一些搜索引擎常用的收费方式。
CPA:代价比较大,用户必须有行为,也就是用户必须点击进去然后下订单进行收费。
3、CTR
CTP=click次数 / impression次数,比如说将CTR与price相乘作为广告排序的依据。
4、基于LR的CTR预测
LR的优点:简单、可解释性强(像DNN难以解释)(若出问题可以查看是数据出问题还是模型出问题)
5、论文Practical Lessons from Pre dicting Clicks on Ads at Facebook
论文结合了GBDT和LR来预测CTR,评价指标为NE和Calibration。
(1)评价指标:
① NE为归一化熵:公式为 ,其中分子为LR的损失函数,yi为样本i的label(值为1/-1),pi为样本i的点击预测概率。分母为原样本数据集平均损失(平均信息熵),p为正样本的概率。NE的作用:在模型的帮准下,样本剩余的不确定性和没有模型时样本的不确定性的比值。NE值越低越好。
,其中分子为LR的损失函数,yi为样本i的label(值为1/-1),pi为样本i的点击预测概率。分母为原样本数据集平均损失(平均信息熵),p为正样本的概率。NE的作用:在模型的帮准下,样本剩余的不确定性和没有模型时样本的不确定性的比值。NE值越低越好。
② Calibration:等于预测点击数 / 实际点击数,值越大越好。
(2)模型:
①两种在线学习方法:基于LR的SGD、BOPR
SGD:

BOPR:基本思想是参数w是一个先验分布为正态分布的分布,参数为u、σ;
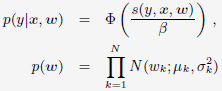
在贝叶斯框架下,每一个样本都是在修正对应的分布参数u、σ。每轮迭代时对应的更新公式为:
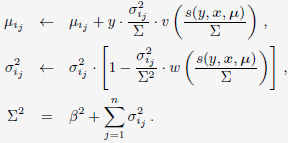
②决策树
前提:随着特征的增加,特征组合变得很困难,特征组合是在特征离散化之后做的,故组合之后特征可能会爆炸,造成维度灾难。所以一种解决特征组合问题的方案被提出。GBDT+LR。
GBDT基本思路:利用树模型的组合特性来自动做特征组合,即使用了GBDT的特征组合能力。整体框架如下:
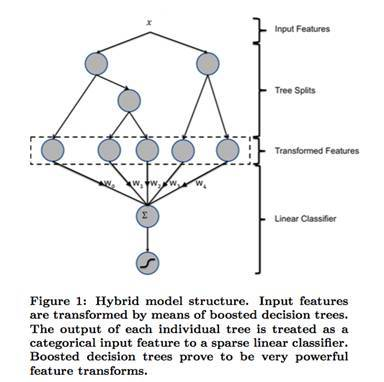
GBDT可以看做是对特征一种组合编码的过程,最后的LR才是最终的分类(回归)模型。
数据分析例子-------CTR1的更多相关文章
- Hadoop第10周练习—Mahout部署及进行20newsgroup数据分析例子
:搭建Mahout环境 :运行20newsgroup 内容 运行环境说明 1.1 硬软件环境 线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 buil ...
- Python数据分析------例子1(信用卡欺诈)
1.读取数据 data=read_csv(path) data.head() #画图(查看class即分类的数据条形图),函数sort_index()是将dataframe按照行索引来排序输出值 co ...
- Javaweb 第15天 web练习和分页技术
第15天 web练习和分页技术 复习day14内容: 学习新技术的思路? 分析功能的思路? 使用queryRunner操作数据库的步骤? ResultSetHandler接口常用实现类(三个重点)? ...
- 【R与数据库】R + 数据库 = 非常完美
前言 经常用R处理数据的分析师都会对dplyr包情有独钟,它强大的数据整理功能让原始数据从杂乱无章到有序清晰,便于后期进一步的深入分析,特别是配合上数据库的使用,更是让分析师如虎添翼,轻松搞定Exce ...
- 第十三章:Python の 网络编程进阶(二)
本課主題 SQLAlchemy - Core SQLAlchemy - ORM Paramiko 介紹和操作 上下文操作应用 初探堡垒机 SQLAlchemy - Core 连接 URL 通过 cre ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
- 关于《Spark快速大数据分析》运行例子遇到的报错及解决
一.描述 在书中第二章,有一个例子,构建完之后,运行: ${SPARK_HOME}/bin/spark-submit --class com.oreilly.learningsparkexamples ...
- 如何在美国公司写project plan 邮件--以hadoop安装和Mahout数据分析为例子
Hi, XXX (boss name) Project Title: Hadoop installation and Data analysis based on Mahout Deliverabl ...
- R与数据分析旧笔记(二)随机抽样的一个综合例子
题目:模拟产生统计专业同学的名单(学号区分),记录数学分析.线性代数.概率统计三科成绩,然后进行一些统计分析 > num=seq(10378001,10378100) > num [1] ...
随机推荐
- hdu 1568关于斐波那契数列的公式及其思维技巧
先看对数的性质,loga(b^c)=c*loga(b),loga(b*c)=loga(b)+loga(c); 假设给出一个数10234432,那么log10(10234432)=log10(1.023 ...
- Java 中 synchronized的用法详解
Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码. 1.方法声明时使用,放在范围操作符(public等)之后,返回类型声明(void等)之 ...
- JAVA实现多线程的两种方法
参考URL: http://www.cnblogs.com/jbelial/archive/2013/03/17/2964472.html 1.继承 java.lang.Thread 类. 2.实现R ...
- RestTemplate使用详解
1.RestTemplate添加RequestHeader如content-type可通过httpclient设置 List<Header> headers = new ArrayList ...
- Java内部静态类与内部非静态类
Java内部静态类与内部非静态类 把类看成一个属性,稍微容易理解一些:在main方法中,不会去直接引用一个非static的变量,对于类也一样. 学习了:http://blog.csdn.net/zer ...
- Javascript中数据实时推送
数据变化后前端需要更新,有几种方式:(参考http://www.xiaocai.name/post/cf1f9_7b6507) .利用setInterval函数,每隔n秒去异步拉取数据.对数据实时性要 ...
- HDU 4607 Park visit (求树的直径)
解题思路: 通过两次DFS求树的直径,第一次以随意点作为起点,找到距离该点距离最远的点,则能够证明这个点一定在树的直径上,然后以该点为起点进行DFS得到的最长路就是树的直径. 最后的询问,假设K &l ...
- 基于ActiveMQ的消息中间件系统逻辑与物理架构设计具体解释
1. 基本介绍与组件架构图 维基百科对消息中间件的定义是"Message-oriented Middleware is software infrastructure focused on ...
- HDU 5218 The E-pang Palace (简单几何—2014广州现场赛)
题目链接:pid=5128">http://acm.hdu.edu.cn/showproblem.php? pid=5128 题面: The E-pang Palace Time Li ...
- 翻译Beginning iOS 7 Development中文版
不会iOS开发好像真的说只是去,来本中文版的Beginning iOS 7 Development吧. 看了Beginning iOS 7 Development这本书,感觉蛮不错的.全英文的,没有中 ...