大数据下多流形聚类分析之谱聚类SC
大数据,人人都说大数据;类似于人人都知道黄晓明跟AB结婚一样,那么什么是大数据?对不起,作为一个本科还没毕业的小白实在是无法回答这个问题。我只知道目前研究的是高维,分布在n远远大于2的欧式空间的数据如何聚类。今年的研究生数模中用大数据引出了一个国内还不怎么火热的概念——多流形结构。题目中那个给出的流形概念:流形是局部具有欧氏空间性质的空间,欧氏空间就是流形最简单的实例。从而在2000年提出了多流形学习:基于数据均匀采样于一个高维欧氏空间中的低维流形的假设,流形学习试图学习出高维数据样本空间中嵌入的低维子流形,并求出相应的嵌入映射。
很无奈的是这些复杂的文字看了两天外加其他论文的参考也没搞明白,整个人就是稀里糊涂,什么是子空间?什么是稀疏子空间?什么是低秩子空间?我知道这些方法的提出很多是基于目前广泛应用的非线性数据中谱聚类算法有关,希望能从中找到答案。首先我们来了解几个陌生的概念热身一下:
- Graph(Ps:Thanks for the contributions of wiki,sorry for no way to donate a cup of coffee)
不妨开一下脑洞,如果把数据可视化为欧式空间的点,那么数据与数据之间的联系就用权重表示,这个权重就是点之间的连线也叫边。权重顾名思义就是分量,关系(中国人的思维),假设把我跟你之间的关系用权重表示,可能是没有关系(权重为0),可能有关系(权重为1)。当然也可以用相关性来看待两个点之间的相似度,我跟你之间连接越紧密,说明关系越深,相似度越大,所谓:物以类聚,人以群分。所以就有了大大小小的集合,真个社交会如果用图来表示,就是一个巨大的社交网络图G=(V,E),V表示点的集合,E表示边的集合。
- Cut(值为被切割的边的权值之和)
现在我是上帝,我要将你们这群人一分为二(现实的聚类往往是2类以上)!如何分割?当然是找关系稀疏的地方下手。谱聚类的目的就是找到一个合理的分割即找到连接两个子网络的权重尽可能小的边,并将其残忍砍断,让你们各自画地为牢~并使得子网络内部的边权尽量大。
这种一分为二的切割情况、具体的Cut值表示以及切割情况如下图所示(以下部分图来自“A Tutorial on Spectral Clustering”):
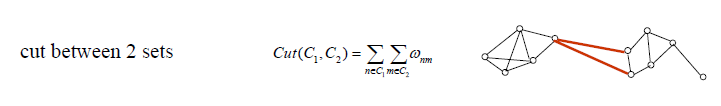
以上公式中,Wnm为属于类C1中的点n到类C2中的点m之间的权重;Cut(C1,C2)为类C1与C2之间的Cut值,至于具体的切割方式,我们主要推出以下三种常见的切割方式:
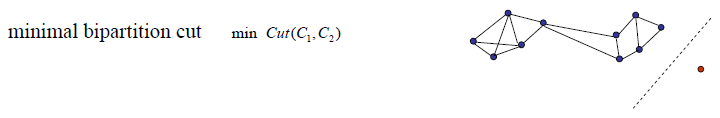
本来的目的是只要使得切割的cut值最小,也就是把权重最小的的边切断就好,但是人们发现这样的切割方式运用在数据中如果存在上图红色点标记的离异点时就会让划分不均匀,造成离异的数据点和密集分布的数据被分别聚类,而现实中往往这些离异数据很可能并不是那么“离异”,因此这样就达不到我们聚类的效果,毕竟聚类是希望把特征相似的数据聚类而不是将“不听话”的数据识别出来。因此,为了产生分布较为“均匀”,因此提出以下两种分割方式~
- RatioCut
公式如下:
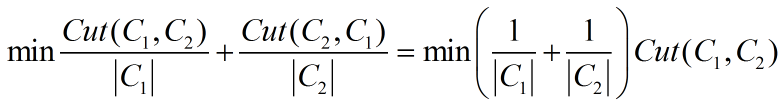
其中 为子图Ci(i=1,2)中包含的顶点数目。该目标函数用类内顶点数作分母,反映了一些类内信息,对倾斜划分能起到一定的约束作用,但顶点数多并非类内相似度大的充要条件,因此我们需要更换“标准化数据”的条件,由此,标准化切割被提出~
为子图Ci(i=1,2)中包含的顶点数目。该目标函数用类内顶点数作分母,反映了一些类内信息,对倾斜划分能起到一定的约束作用,但顶点数多并非类内相似度大的充要条件,因此我们需要更换“标准化数据”的条件,由此,标准化切割被提出~
- Normalized cut
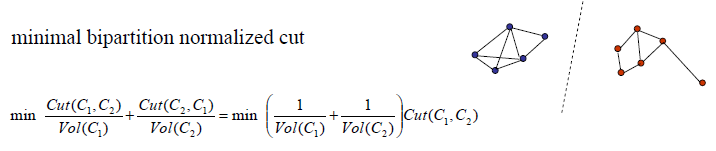
上图公式中的Vol(Ci)为类Ci的点到空间中相连接点的权重之和。
看起来,第三种方法非常之强大,既满足不同类间的权值和最小,同一个类内的权值和最大,似乎把需要解决的问题都解决了。But,here is our problem:这个问题的最优解的求解问题是一个NP-hard problem!至于什么是NP-hard,抱歉,各位自行看wiki链接吧,我是不明白,也没有研究过这一块了。不过不明白也不影响我们后面的谱聚类算法的提出。只要知道谱聚类算法就是解决这个NP问题的一个近似算法,类似于偏微分中常常是以数值解来逼近真实解的道理~
既然我们了解了谱聚类的目的和由来,下面举个小例子完整的理解一下整个谱聚类算法过程:
(0)空间中有这么6个数据点:A,B,C,D,E关系如下(无向加权图):
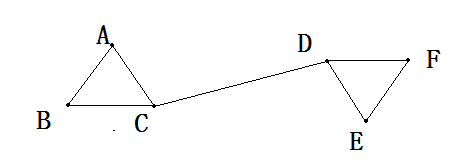
(1)构造邻接矩阵
由于邻接矩阵W的构造原理是:如果空间中任意点a与点b属于同一个子图,假设边权全部取值为1,那么W的第a行第b列的元素W(a,b)=W(b,a)=1,反之为0。因此我们由上图关系构造的邻接矩阵W为:
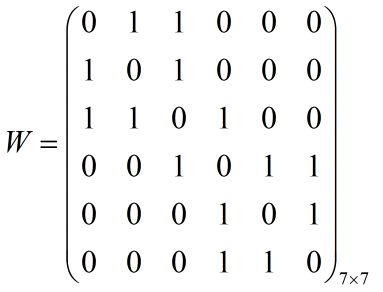
上图的邻接矩阵通常用来描述图中点与点之间的关系,其中W的行列标好分别对应于点A,B,C,D,E,F。其实我们也会发现无向图的邻接矩阵实际上是沿着对角线对称的一个对称矩阵,而且主对角线上的元素全部为0。
(2)构造度矩阵(某个点的度指的是与该点关联的点之间的总权数,比如A点的度为2,因为A分别与B、C两点相连且权为1)
那么度矩阵如何构造?第i点的度其实就是邻接矩阵W的第i列或行的元素相加,因此我们将W的每一列元素相加依次存入一个对角矩阵的对角线上,该矩阵的主对角线以外的元素全部为0,因此本例中的度矩阵D如下:

(3)相似度矩阵(也叫拉普拉斯矩阵)
这个拉普拉斯矩阵L的得来听得很牛×,实际上就是L=D-W,计算结果如下:
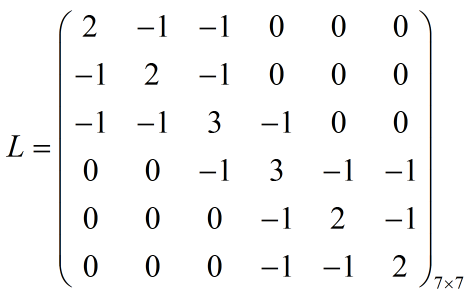
相信稍微熟悉线代的朋友都看出来这个矩阵的一些性质:主对角线的上元素的值对应的是该点的度,某一列元素中值为-1的下标对应的是与该点关联的点,至于不相关的点的元素值当然都是1咯。
(4)计算特征值和特征向量
接下来就很好理解,计算这个拉普拉斯矩阵的前k个特征值和对应的特征向量。如果说前面的拉普拉斯矩阵的构造是为了将数据之间的关系反映到矩阵中,那么计算特征值以及特征向量从而达到将维度从N维降到k维,然后维度降下来了,我们就可以很happy的使用kmeans聚类,聚类完成后再将数据投影到原始数据上,这样原始数据就成功聚类啦~
关于特征值和特征向量的理解,我这里引用知乎上面的一个精彩回答:
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:Dan Pan
链接:http://www.zhihu.com/question/21082351/answer/19055262
来源:知乎
特征值是
那么这样,给定任意的一个向量
既然我们要将N维的矩阵压缩到k维矩阵,那么就少不了特征值,取A的前k个特征值进而计算出k个N维向量P(1),P(2),...,P(k).这k个向量组成的矩阵N行k列的矩阵(经过标准化)后每一行的元素作为k维欧式空间的一个数据,将这N个数据使用kmeans或者其他传统的聚类方法聚类,最后将这个聚类结果映射到原始数据中,原始数据从而达到了聚类的效果。
当然,这里仅仅是昨天一天的研究成果,是参考了多个博客和指导书的情况下豁然开朗,但是随着今天笔记的进行,发现自己还是有很多不明白的地方,比如具体的切割是怎么实现?具体的特征值以及特征向量又是如何求解,以及最重要的是把自己写的代码运用到实际的数据聚类效果又是怎样?
Problem1:How to create the similarity matrix?
我们知道,正如万有引力的存在,任何物质之间的引力都存在,只不过万有引力的大小跟距离和质量有关系。那么空间中的任何两个数据应该也是都有一定的相关关系的,事情往往不如我们上面举例中的权重为0和1来区分,如何确定他们每个点与其他点之间的相似度?如何确定边上的权重分布?怎么得到相似度矩阵?
已知空间中有这么一群数据点:
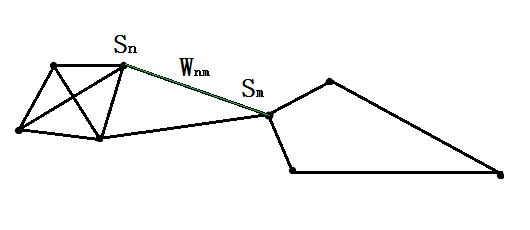
任意点Sn与点Sm之间的权重为Wnm,那么用这个权重来描述点Sn与点Sm之间的相似度,则该值一般使用高斯核函数来度量:

这里的欧几里德距离平方,是由于我们计算的欧式距离往往是需要开根号,因此取平方值也是方便计算。由上述公式可以轻易得到随着两个点之间距离的增大,近似度也在不断减小,且总在0到1之间。这里有一个自由参数 的确定是一个问题:
的确定是一个问题:
1、早先的自由参数的确定是选取多个自由参数,然后将聚类效果最好的那个参数作为最终的参数,但是这样计算时间就增加了;
2、也有人提出通过经验公式确定这个自由参数,例如有人取距离变化范围的10%~20%或者取最大欧式距离的5%,但是这样的经验并不适用于所有的数据集;
3、Zelnik-Manor和Perona提出的Self-Tuning算法得到了比较广泛的应用。该方法是利用每个点自身的领域信息为每个点计算一个自适应的参数,两点之间的相似度被定义如下:

假设任何一点Sn有t个最近邻点。如果我们将这些邻点按照降序排列,计算出Sn到第t/2个近邻点之间的距离,并将其定义为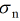 ,依次更新近邻点之间的相似度。(至于这个t的取值,通常取14)
,依次更新近邻点之间的相似度。(至于这个t的取值,通常取14)
主要算法步骤如下:
- 计算出样本数据任何一点与其他点之间的距离,并存入距离矩阵d中;
- 对每一个点Sn与其他点之间的距离进行排序,即对距离矩阵d按照行或者列进行降序排序,取排行第7的那个距离为,并将这些存入向量m;
- 根据距离矩阵d以及参数向量m,运用Wnm的公式求出相似度矩阵W。
Problem2:How to get the Affinity matrix?
我们给每一个数据之间的联系确定了权重,那么这个相似度矩阵W(similarity matrix)并不是我们想要的邻接矩阵(Affinity matrix),因为理想情况下,同一个类的连点间的相似度为1,不同类内点之间的相似度为0,而我们计算的相似度往往是介于0到1之间。有人提出可以将权重小于某一个阈值的边权重置为0,大于该阈值的边权重置为1,因此就有了我们想要的二值化的邻接矩阵,但是这个阈值的取定也是一个非常值得讨论的问题。实际上这方面能够很好的解决问题的算法很少被关注,然而,作为一个想要最优化算法的人来说,肯定是想面面俱到,却发现自己挖掘的坑越来越大~
还有一些其他的问题就不再多赘述,以下两篇博客里的公式推导非常详细:
从拉普拉斯矩阵说到谱聚类
漫谈 Clustering (4): Spectral Clustering
感谢其他参考文献,在此就懒得给出参考链接,一一谢过~总算是弄明白了一些事情,话说我的重点不应该是稀疏子空间聚类SMMC么?突然发现自己真的是跳进自己挖0的坑越来越无法自拔。。。
大数据下多流形聚类分析之谱聚类SC的更多相关文章
- 【阿里云产品公测】大数据下精确快速搜索OpenSearch
[阿里云产品公测]大数据下精确快速搜索OpenSearch 作者:阿里云用户小柒2012 相信做过一两个项目的人都会遇到上级要求做一个类似百度或者谷歌的站内搜索功能.传统的sql查询只能使用like ...
- 大数据下的数据分析平台架构zz
转自http://www.cnblogs.com/end/archive/2012/02/05/2339152.html 随着互联网.移动互联网和物联网的发展,谁也无法否认,我们已经切实地迎来了一个海 ...
- 【CSWS2014 Summer School】大数据下的游戏营销模式革新-邓大付
大数据下的游戏营销模式革新 邓大付博士腾讯专家工程师 Bio:毕业于华中科技大学,现任腾讯IEG运营部数据中心技术副总监,负责腾讯游戏的数据挖掘相关工作,包括有用户画像,推荐系统,基础算法研究等.主要 ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- mysql优化----大数据下的分页,延迟关联,索引与排序的关系,重复索引与冗余索引,索引碎片与维护
理想的索引,高效的索引建立考虑: :查询频繁度(哪几个字段经常查询就加上索引) :区分度要高 :索引长度要小 : 索引尽量能覆盖常用查询字段(如果把所有的列都加上索引,那么索引就会变得很大) : 索引 ...
- 大数据下的Distinct Count(一):序
在数据库中,常常会有Distinct Count的操作,比如,查看每一选修课程的人数: select course, count(distinct sid) from stu_table group ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
- 教你做一个牛逼的DBA(在大数据下)
一.基本概念 大数据量下,搞mysql,以下概念需要先达成一致 1)单库,不多说了,就是一个库 2)分片(sharding),水平拆分,用于解决扩展性问题,按天拆分表 3)复制(replication ...
- Apache Kylin - 大数据下的OLAP解决方案
OLAPCube是一种典型的多维数据分析技术,Cube本身可以认为是不同维度数据组成的dataset,一个OLAP Cube 可以拥有多个维度(Dimension),以及多个事实(Factor Mea ...
随机推荐
- mysql一些小技巧
1 强制命中索引:force index 某些时候查询,索引会失效,可以进行强制命中索引 2 group_concat 能将相同的行组合起来. 当然,我推荐这种操作可以在代码中操作,如果必须在特定情况 ...
- git技巧记录--blame
git blame [-L<m,n>] FilePath 可以查看代码每一行是谁写的(根据该行最后一次改动情况), -L表示要查看的行数范围, m: 起始行数, n:结束行数. 方便快速定 ...
- sed实例精解--例说sed完整版
原文地址:sed实例精解--例说sed完整版 作者:xiaozhenggang 最近在学习shell,怕学了后面忘了前面的就把学习和实验的过程记录下来了.这里是关于sed的,前面有三四篇分开的,现在都 ...
- Servlet/JSP-06 Session
一. 概述 Session 指客户端(浏览器)与服务器端之间保持状态的解决方案,有时候也用来指这种解决方案的存储结构. 当服务器端程序要为客户端的请求创建一个 Session 时,会首先检查这个请求里 ...
- linux 源码安装mysql 5.5
今天在ubuntu和CentOS下,用源码反复安装了许多次mysql,趁还没忘记,赶紧记下来... 在ubuntu和CentOS下安装过程倒是没什么差别. 0.下载源码, ...
- Android界面隐藏软键盘的探索(兼findViewById返回null解决办法)
最近写的APP,老师说我的登陆界面虽然有ScrollView滑动,但用户体验不太好,因为软键盘会挡住输入框或登录button(小米Pad,横屏,当指定只能输入数字时没找到关闭系统自带键盘的下箭头). ...
- CSS Sprite雪碧图应用
在写网页过程中,会遇到这种需要使用多个小图标: 如上图中的「女装」文字左边的图标.容易想到的解决方法是为每张图片加入<img>标签,但这样做会增加HTTP请求数量,影响网站加载速度.比这更 ...
- 为什么 Java 不提供无符号类型呢?
网上查资料,无意中找到一个java写的开源论坛,用的人还挺多 http://jforum.net/ 查MD5,了解到 Java getBytes方法详解(字符集问题) http://liushilan ...
- Diffuse_Shader笔记1.shader和编辑器的交互
1.写在前面的心情 o(︶︿︶)o 坚持不下来就是失败:每次看到candycat博客都会一阵阵冷汗很愧疚... shader .图形还是要学:不仅是兴趣,以后一定有用.现在做游戏UI开发,工作上还 ...
- ubuntu为用户增加sudoer权限的两种方法
方法一.使用usermod命令 新增user sudo adduser username 增加sudo权限 sudo usermod -aG sudo username sudo usermod -a ...