mapreduce 自定义数据类型的简单的应用
本文以手机流量统计为例:
日志中包含下面字段
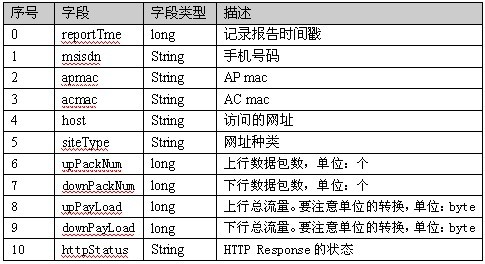
现在需要统计手机的上行数据包,下行数据包,上行总流量,下行总流量。
分析:可以以手机号为key 以上4个字段为value传传递数据。
这样则需要自己定义一个数据类型,用于封装要统计的4个字段,在map 与reduce之间传递和shuffle
注:作为key的自定义类型需要实现WritableComparable 里面的compareTo方法
作为value的自定义类 则只需实现Writable里面的方法
自定义代码如下:
package org.apache.hadoop.mapreduce.io; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; /***
* customize mobile data writable
* @author nele
*
*/
public class MobileDataWritable implements
Writable { private long upPackNum; private long downPackNum; private long upPayLoad; private long downPayLoad; public long getUpPackNum() {
return upPackNum;
} public void setUpPackNum(long upPackNum) {
this.upPackNum = upPackNum;
} public long getDownPackNum() {
return downPackNum;
} public void setDownPackNum(long downPackNum) {
this.downPackNum = downPackNum;
} public long getUpPayLoad() {
return upPayLoad;
} public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
} public long getDownPayLoad() {
return downPayLoad;
} public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
} public MobileDataWritable() {
} public MobileDataWritable(long upPackNum, long downPackNum, long upPayLoad,
long downPayLoad) {
this.set(upPackNum, downPackNum, upPayLoad, downPayLoad);
} public void set(long upPackNum, long downPackNum, long upPayLoad,
long downPayLoad) {
this.upPackNum = upPackNum;
this.downPackNum = downPackNum;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
} public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
} public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
} @Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + (int) (downPackNum ^ (downPackNum >>> 32));
result = prime * result + (int) (downPayLoad ^ (downPayLoad >>> 32));
result = prime * result + (int) (upPackNum ^ (upPackNum >>> 32));
result = prime * result + (int) (upPayLoad ^ (upPayLoad >>> 32));
return result;
} @Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MobileDataWritable other = (MobileDataWritable) obj;
if (downPackNum != other.downPackNum)
return false;
if (downPayLoad != other.downPayLoad)
return false;
if (upPackNum != other.upPackNum)
return false;
if (upPayLoad != other.upPayLoad)
return false;
return true;
} @Override
public String toString() {
return upPackNum + "\t" +downPackNum+ "\t" + upPayLoad + "\t" + downPayLoad;
} }
现在就可以使用自定义的类型进行手机流量的统计 代码如下:
/***
* MapReduce Module
*
* @author nele
*
*/
public class MobileDataMapReduce extends Configured implements Tool { // map class
/**
*
* @author nele
*
*/
public static class MobileDataMapper extends
Mapper<LongWritable, Text, Text, MobileDataWritable> { public Text outPutKey = new Text();
public MobileDataWritable outPutValue = new MobileDataWritable(); @Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
System.out.println(key+":"+value);
String[] arr = value.toString().split("\t");
outPutKey.set(arr[1]);
outPutValue.set(Long.valueOf(arr[6]), Long.valueOf(arr[7]),
Long.valueOf(arr[8]), Long.valueOf(arr[9]));
context.write(outPutKey, outPutValue);
} } // reduce class
/***
*
* @author nele
*
*/
public static class MobileDataReducer extends
Reducer<Text, MobileDataWritable, Text, MobileDataWritable> { private Text outPutKey = new Text();
private MobileDataWritable outPutValue = new MobileDataWritable(); @Override
public void reduce(Text key, Iterable<MobileDataWritable> values,
Context context) throws IOException, InterruptedException {
long upPackNum = 0;
long downPackNum = 0;
long upPayLoad = 0;
long downPayLoad = 0;
for (MobileDataWritable val : values) {
upPackNum += val.getUpPackNum();
downPackNum += val.getDownPackNum();
upPayLoad += val.getUpPayLoad();
downPayLoad += val.getDownPayLoad();
}
outPutKey.set(key);
outPutValue.set(upPackNum, downPackNum, upPayLoad, downPayLoad);
context.write(outPutKey, outPutValue);
}
} // run method
public int run(String[] args) throws Exception {
Configuration conf = super.getConf(); // create job
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); // set input path
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inPath); // map
job.setMapperClass(MobileDataMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MobileDataWritable.class); // conbile
job.setCombinerClass(MobileDataReducer.class); // reduce
job.setReducerClass(MobileDataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(MobileDataWritable.class); // output
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath); // submit
return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args) throws Exception {
args = new String[] {
"hdfs://bigdata5:8020/user/nele/data/input/HTTP_20130313143750.data",
"hdfs://bigdata5:8020/user/nele/data/output/output6" }; Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new MobileDataMapReduce(), args); System.exit(status);
} }
这样就可以统计 给出的数据日志中的手机各种流量的数据
mapreduce 自定义数据类型的简单的应用的更多相关文章
- Hadoop MapReduce自定义数据类型
一 自定义数据类型的实现 1.继承接口Writable,实现其方法write()和readFields(), 以便该数据能被序列化后完成网络传输或文件输入/输出: 2.如果该数据需要作为主键key使用 ...
- 自定义MapReduce中数据类型
数据类型(都实现了Writable接口) BooleanWritable 布尔类型 ByteWritable 单字节数值 DoubleWritable 双字节数值 FloatWritable 浮点数 ...
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- Hadoop mapreduce自定义分组RawComparator
本文发表于本人博客. 今天接着上次[Hadoop mapreduce自定义排序WritableComparable]文章写,按照顺序那么这次应该是讲解自定义分组如何实现,关于操作顺序在这里不多说了,需 ...
- java基础(14):Eclipse、面向对象、自定义数据类型的使用
1. Eclipse的应用 1. 常用快捷操作 Ctrl+T:查看所选中类的继承树 例如,在下面代码中,选中Teacher类名,然后按Ctrl+T,就会显示出Teacher类的继承关系 //员工 ab ...
- js数据类型很简单,却也不简单
最近脑子里有冒出"多看点书"的想法,但我个人不是很喜欢翻阅纸质书籍,另一方面也是因为我能抽出来看书的时间比较琐碎,所以就干脆用app看电子书了(如果有比较完整的阅读时间,还是建议看 ...
- TVM自定义数据类型
TVM自定义数据类型 本文将介绍"自定义数据类型"框架,该框架可在TVM中使用自定义数据类型. 介绍 在设计加速器时,关键是如何近似地表示硬件中的实数.这个问题具有长期的行业标准解 ...
- 自主数据类型:在TVM中启用自定义数据类型探索
自主数据类型:在TVM中启用自定义数据类型探索 介绍 在设计加速器时,一个重要的决定是如何在硬件中近似地表示实数.这个问题有一个长期的行业标准解决方案:IEEE 754浮点标准.1.然而,当试图通过构 ...
- 【填坑往事】使用Rxjava2的distinct操作符处理自定义数据类型去重的问题
最近碰到一个问题,自定义数据类型列表中出现了重复数据,需要去重.处理去重的办法很多,比如借助Set集合类,使用双重循环拿每一个元素和其他元素对比等.这里介绍一种简单而且比较优雅的方式:使用Rxjava ...
随机推荐
- Linux下的IO模式
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间.所以说,当一个read操作发生时,它会经历两个阶段:1. 等待数据准 ...
- HDFS源码分析:NameNode相关的数据结构
本文主要基于Hadoop1.1.2分析HDFS中的关键数据结构. 1 NameNode 首先从NameNode开始.NameNode的主要数据结构如下: NameNode管理着两张很重要的表: 1) ...
- 【matlab】设定函数默认参数
C++/java/python系列的语言,函数可以有默认值,通常类似如下的形式: funtion_name (param1, param2=default_value, ...) 到了matlab下发 ...
- wpf listview 换行
<ListView Name="listView1" VerticalAlignment="Top" Height="600" Ma ...
- codevs1183泥泞的道路
题意:给定一张有向稠密图和通过每条边的时间和路程,问从1到n的路程/时间 最大为多少 正解:SPFA+二分答案 开始做的时候,想直接跑图论,后来发现好像不对(不然数据范围怎么这么小) 但是显然要用到图 ...
- Servlet教程
有JSP的教程,就有Servlet教程. http://www.runoob.com/servlet/servlet-tutorial.html
- Linux列出安装过的程序
命令行: dpkg -l apt-cache(模糊搜索apt-cache search 包名) pkgnames yum list(ubuntu下试了无效) rpm -aq(ubuntu下试了无效)
- PHP Fatal error: Call to undefined function mb_substr()
Lamp架构 PHP 5.3.29 #查看php是否有mbstring模块 php -m | grep mbstring yum install php-mbstring -y find / -nam ...
- Nginx系列1之部分模块详解
1 内核模块: 名称: daemon 语法: daemon on |off 默认值: on 功能: 决定nginx 在前台执行还是后台守护进程执行的 ================== 名称: En ...
- UVA10054The Necklace (打印欧拉路)
题目链接 题意:一种由彩色珠子组成的项链.每个珠子的两半由不同的颜色组成.相邻的两个珠子在接触的地方颜色相同.现在有一些零碎的珠子,需要确定他们是否可以复原成完整的项链 分析:之前也没往欧拉路上面想, ...