转:遗传算法解决TSP问题
1.编码
这篇文章中遗传算法对TSP问题的解空间编码是十进制编码。如果有十个城市,编码可以如下:
0 1 2 3 4 5 6 7 8 9
这条编码代表着一条路径,先经过0,再经过1,依次下去。
2.选择
选择操作仍然是轮盘赌模型,虽然不会出现路径长度为负数的情况,但是需要考虑与上篇文章不同的是求的是最小值。因此在代码中概率的计算为:
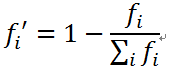
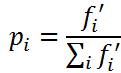
3.交叉

4.变异
变异操作就是交换两个城市,例如:
0 1 2 3 4
0 2 1 3 4
5.代码实现
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<math.h>
#include<time.h>
#include<Windows.h>
#include<fstream>
#include<iostream>
using namespace std; const int cities = ; //城市的个数
const int MAXX = ; //迭代次数
const double pc = 0.8; //交配概率
const double pm = 0.05; //变异概率
const int num = ; //种群的大小 int bestsolution;//最优染色体
double distance1[cities][cities];//城市之间的距离 struct group //染色体的结构
{
int city[cities];//城市的顺序
double adapt;//适应度
double p;//在种群中的幸存概率
}group[num],grouptemp[num]; struct point{
double x,y;
}Cpoint[cities]; //随机产生cities个城市之间的相互距离
void init()
{/*
int i,j;
memset(distance,0,sizeof(distance));
srand((unsigned)time(NULL));
for(i=0;i<cities;i++)
{
for(j=i+1;j<cities;j++)
{
distance[i][j]=rand()%100;
distance[j][i]=distance[i][j];
}
}
//打印距离矩阵
printf("城市的距离矩阵如下\n");
for(i=0;i<cities;i++)
{
for(j=0;j<cities;j++)
printf("%4d",distance[i][j]);
printf("\n");
}*/
ifstream f1("C:\\city.txt",ios::in);
for(int i = ; i < cities; i++){
//if(ll % 2 != 0)
f1 >> Cpoint[i].x;
//if(ll % 2 == 0)
f1 >> Cpoint[i].y;
//ll++;
}
f1.close();
double tmp1 = 0.0;
for(int m = ; m < cities; m++){
for(int n = ; n < cities; n++){
if(m == n)
distance1[m][n] = ;
else{
tmp1 = sqrt(pow(Cpoint[m].x - Cpoint[n].x,) + pow(Cpoint[m].y - Cpoint[n].y,));
distance1[m][n] = tmp1;
distance1[n][m] = tmp1;
}
}
}
//打印距离矩阵
printf("城市的距离矩阵如下\n");
for(int i = ; i < cities; i++)
{
for(int j = ; j<cities; j++){
cout << distance1[i][j] << ' ';
}
cout << endl;
}
}
//随机产生初试群
void groupproduce()
{
int i,j,t,k,flag; for(i = ; i < num; i++) //初始化
for(j = ; j < cities; j++)
group[i].city[j]=-; srand((unsigned)time(NULL));
for(i = ; i < num; i++)
{
//产生10个不相同的数字
for(j = ; j < cities;)
{
t = rand() % cities;
flag = ;
for(k = ; k < j; k++)
{
if(group[i].city[k] == t)
{
flag = ;
break;
}
}
if(flag)
{
group[i].city[j] = t;
j++;
}
}
}
//打印种群基因
printf("初始的种群\n");
for(i = ; i < num; i++)
{
for(j = ; j < cities; j++)
printf("%4d",group[i].city[j]);
printf("\n");
}
}
//评价函数,找出最优染色体
void pingjia()
{
int i,j;
int n1,n2;
double sumdistance;
int biggestsum = ;
double biggestp = ;
for(i = ; i < num; i++)
{
sumdistance = ;
for(j = ; j < cities; j++)
{
n1 = group[i].city[j-];
n2 = group[i].city[j];
sumdistance += distance1[n1][n2];
}
sumdistance += distance1[group[i].city[cities-]][group[i].city[]];
group[i].adapt = sumdistance; //每条染色体的路径总和
//printf("%d",group[i].adapt);
biggestsum += sumdistance; //种群的总路径
}
//计算染色体的幸存能力,路劲越短生存概率越大
for(i = ; i < num; i++)
{
group[i].p = - (double)group[i].adapt / (double)biggestsum; biggestp += group[i].p;
//printf("%s"," ");
}
//printf("%f",biggestp);
for(i = ; i < num; i++){ group[i].p = group[i].p / biggestp; }//在种群中的幸存概率,总和为1
//求最佳路径 bestsolution = ;
for(i = ;i < num; i++)
if(group[i].p > group[bestsolution].p)
bestsolution = i;
//打印适应度
/*for(i = 0; i < num; i++)
cout << "染色体" << i << "的路径之和与生存概率分别为" << group[i].adapt << "和" << group[i].p;
//printf("染色体%d的路径之和与生存概率分别为%4d %.4f\n",i,group[i].adapt,group[i].p);
cout << "当前种群的最优染色体是" << bestsolution << "号染色体" << endl;
//printf("当前种群的最优染色体是%d号染色体\n",bestsolution);*/
}
//选择
void xuanze()
{
int i,j,temp;
double gradient[num];//梯度概率
double xuanze[num];//选择染色体的随机概率
int xuan[num];//选择了的染色体
//初始化梯度概率
for(i = ; i < num; i++)
{
gradient[i] = 0.0;
xuanze[i] = 0.0;
}
gradient[] = group[].p; for(i = ; i < num; i++)
gradient[i] = gradient[i-]+group[i].p; srand((unsigned)time(NULL));
//随机产生染色体的存活概率
for(i = ; i < num; i++)
{
xuanze[i] = (rand()%);
xuanze[i] /= ;
}
//选择能生存的染色体
for( i = ; i < num; i++)
{
for(j = ; j < num; j++)
{
if(xuanze[i] < gradient[j])
{
xuan[i] = j; //第i个位置存放第j个染色体
break;
}
}
}
//拷贝种群
for(i = ; i < num; i++)
{
grouptemp[i].adapt = group[i].adapt;
grouptemp[i].p = group[i].p;
for(j = ; j < cities; j++)
grouptemp[i].city[j] = group[i].city[j];
}
//数据更新
for(i = ; i < num; i++)
{
temp = xuan[i];
group[i].adapt = grouptemp[temp].adapt;
group[i].p = grouptemp[temp].p;
for(j = ; j < cities; j++)
group[i].city[j] = grouptemp[temp].city[j];
}
//用于测试
/*
printf("<------------------------------->\n");
for(i=0;i<num;i++)
{
for(j=0;j<cities;j++)
printf("%4d",group[i].city[j]);
printf("\n");
printf("染色体%d的路径之和与生存概率分别为%4d %.4f\n",i,group[i].adapt,group[i].p);
}
*/
} //交配,对每个染色体产生交配概率,满足交配率的染色体进行交配
void jiaopei()
{
int i,j,k,kk;
int t;//参与交配的染色体的个数
int point1,point2,temp;//交配断点
int pointnum;
int temp1,temp2;
int map1[cities],map2[cities];
double jiaopeip[num];//染色体的交配概率
int jiaopeiflag[num];//染色体的可交配情况
int kkk,flag=;
//初始化
for(i = ; i < num; i++)
{
jiaopeiflag[i] = ;
}
//随机产生交配概率
srand((unsigned)time(NULL));
for(i = ; i < num; i++)
{
jiaopeip[i] = (rand()%);
jiaopeip[i] /= ;
}
//确定可以交配的染色体
t = ;
for(i = ; i < num; i++)
{
if(jiaopeip[i] < pc)
{
jiaopeiflag[i] = ;
t++;
}
}
t = t/ * ;//t必须为偶数,产生t/2个0-9交配断点
srand((unsigned)time(NULL));
temp1 = ; //temp1号染色体和temp2染色体交配
for(i = ; i < t/; i++) //如果有5个染色体需要交配,但是实际上t/2代表只有4个染色体会真正的交配,剩下的1个再加上5个不需要交配的染色体直接进入下一代。
{
point1 = rand() % cities;//交配点1
point2 = rand() % cities;//交配点2
//选出一个需要交配的染色体1
for(j = temp1;j < num; j++)
{
if(jiaopeiflag[j] == )
{
temp1 = j;
break;
}
}
//选出另一个需要交配的染色体2与1交配
for(j = temp1+; j < num; j++)
{
if(jiaopeiflag[j] == )
{
temp2 = j;
break;
}
}
//进行基因交配
if(point1 > point2) //保证point1<=point2
{
temp = point1;
point1 = point2;
point2 = temp;
}
//初始化
memset(map1,-,sizeof(map1));
memset(map2,-,sizeof(map2));
//断点之间的基因产生映射
for(k = point1; k <= point2; k++)
{
map1[group[temp1].city[k]] = group[temp2].city[k];
map2[group[temp2].city[k]] = group[temp1].city[k];
}
//断点两边的基因互换
for(k = ; k < point1; k++)
{
temp = group[temp1].city[k];
group[temp1].city[k] = group[temp2].city[k];
group[temp2].city[k] = temp;
}
for(k = point2+; k < cities; k++)
{
temp = group[temp1].city[k];
group[temp1].city[k] = group[temp2].city[k];
group[temp2].city[k] = temp;
}
//printf("处理冲突---------------------\n");
//处理染色体1产生的冲突基因
for(k = ; k < point1; k++)
{
for(kk = point1; kk <= point2; kk++)
{
if(group[temp1].city[k] == group[temp1].city[kk])
{
group[temp1].city[k] = map1[group[temp1].city[k]]; //如果相等则进行映射操作
//find
for(kkk = point1;kkk <= point2; kkk++)
{
if(group[temp1].city[k] == group[temp1].city[kkk]) //考虑如果映射一次仍然具有相同的城市,则再进行一次映射操作
{
flag = ;
break;
}
}
if(flag == ) //flag不断判断同一染色体中是否还存在相同的城市
{
kk = point1 - ;
flag = ;
}
else
{
flag = ;
break;
}
}
} }
for(k = point2+; k < cities; k++)
{
for(kk = point1; kk <= point2; kk++)
{
if(group[temp1].city[k] == group[temp1].city[kk])
{
group[temp1].city[k] = map1[group[temp1].city[k]];
//find
for(kkk = point1;kkk <= point2; kkk++)
{
if(group[temp1].city[k] == group[temp1].city[kkk])
{
flag = ;
break;
}
}
if(flag == )
{
kk = point1 - ;
flag = ;
}
else
{
flag = ;
break;
}
}
}
}
//处理2染色体产生的冲突基因
for(k = ;k < point1; k++)
{
for(kk = point1; kk <= point2; kk++)
{
if(group[temp2].city[k] == group[temp2].city[kk])
{
group[temp2].city[k] = map2[group[temp2].city[k]];
//find
for(kkk = point1;kkk <= point2; kkk++)
{
if(group[temp2].city[k] == group[temp2].city[kkk])
{
flag = ;
break;
}
}
if(flag == )
{
kk = point1 - ;
flag = ;
}
else
{
flag = ;
break;
}
}
}
}
for(k = point2+; k < cities; k++)
{
for(kk = point1; kk <= point2; kk++)
{
if(group[temp2].city[k] == group[temp2].city[kk])
{
group[temp2].city[k] = map2[group[temp2].city[k]];
//find
for(kkk = point1; kkk <= point2; kkk++)
{
if(group[temp2].city[k] == group[temp2].city[kkk])
{
flag = ;
break;
}
}
if(flag == )
{
kk = point1 - ;
flag = ;
}
else
{
flag = ;
break;
}
}
}
}
temp1 = temp2 + ;
}
} void bianyi()
{
int i,j;
int t;
int temp1,temp2,point;
double bianyip[num]; //染色体的变异概率
int bianyiflag[num];//染色体的变异情况
for(i = ;i < num; i++)//初始化
bianyiflag[i]=;
//随机产生变异概率
srand((unsigned)time(NULL));
for(i = ; i < num; i++)
{
bianyip[i] = (rand()%);
bianyip[i] /= ;
}
//确定可以变异的染色体
t=;
for(i = ; i < num; i++)
{
if(bianyip[i] < pm)
{
bianyiflag[i] = ;
t++;
}
}
//变异操作,即交换染色体的两个节点
srand((unsigned)time(NULL));
for(i = ; i < num; i++)
{
if(bianyiflag[i] == )
{
temp1 = rand() % ;
temp2 = rand() % ;
point = group[i].city[temp1];
group[i].city[temp1] = group[i].city[temp2];
group[i].city[temp2] = point;
}
}
}
int main()
{
int i,j,t;
init();
groupproduce();
//初始种群评价
pingjia();
t=;
while(t++ < MAXX)
{
xuanze();
jiaopei();
bianyi();
pingjia();
}
//最终种群的评价
printf("\n输出最终的种群评价\n");
for(i = ; i < num; i++)
{
for(j = ;j < cities; j++)
{
printf("%4d",group[i].city[j]);
}
cout << " adapt:" << group[i].adapt << " p:" << group[i].p << endl;
//printf(" adapt:%4d, p:%.4f\n",group[i].adapt,group[i].p);
}
printf("最优解为%d号染色体\n",bestsolution);
system("pause");
return ;
}
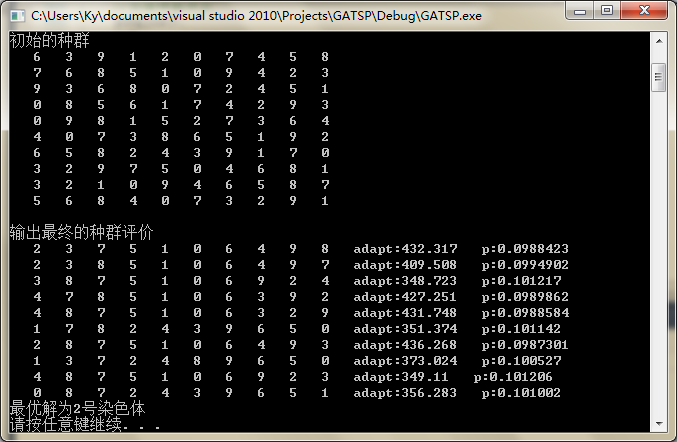
6.结果显示
我的城市为10个,坐标为
41 94
37 84
53 67
25 62
7 64
2 99
68 58
71 44
54 62
83 69
输出结果如图:
7.参考
1.http://blog.csdn.net/mylovestart/article/details/8977005#cpp
2.http://blog.csdn.net/yeruby/article/details/13161853
转:遗传算法解决TSP问题的更多相关文章
- 遗传算法解决TSP问题实现以及与最小生成树的对比
摘要: 本实验采用遗传算法实现了旅行商问题的模拟求解,并在同等规模问题上用最小生成树算法做了一定的对比工作.遗传算法在计算时间和占用内存上,都远远优于最小生成树算法. 程序采用Microsoft vi ...
- 遗传算法解决TSP问题
1实验环境 实验环境:CPU i5-2450M@2.50GHz,内存6G,windows7 64位操作系统 实现语言:java (JDK1.8) 实验数据:TSPLIB,TSP采样实例库中的att48 ...
- 用遗传算法解决TSP问题
浅谈遗传算法:https://www.cnblogs.com/AKMer/p/9479890.html Description \(小m\)在踏上寻找\(小o\)的路程之后不小心碰到了大魔王\(fat ...
- tsp问题——遗传算法解决
TSP问题最简单的求解方法是枚举法. 它的解是多维的.多局部极值的.趋于无穷大的复杂解的空间.搜索空间是n个点的全部排列的集合.大小为(n-1)! .能够形象地把解空间看成是一个无穷大的丘陵地带,各山 ...
- 遗传算法解决寻路问题——Python描述
概要 我的上一篇写遗传算法解决排序问题,当中思想借鉴了遗传算法解决TSP问题,本质上可以认为这是一类问题,就是这样认为:寻找到一个序列X,使F(X)最大. 详解介绍 排序问题:寻找一个序列,使得这个序 ...
- 遗传算法解决旅行商问题(TSP)
这次的文章是以一份报告的形式贴上来,代码只是简单实现,难免有漏洞,比如循环输入的控制条件,说是要求输入1,只要输入非0就行.希望会帮到以后的同学(*^-^*) 一.问题描述 旅行商问题(Traveli ...
- 基础遗传算法的TSP问题
一.简介 旅行商问题是一个经典的组合优化问题.一个经典的旅行商问题可以描述为:一个商品推销员要去若干个城市推销商品,该推销员从一个城市出发,需要经过所有城市后,回到出发地.应如何选择行进路线,以使总的 ...
- C++实现禁忌搜索解决TSP问题
C++实现禁忌搜索解决TSP问题 使用的搜索方法是Tabu Search(禁忌搜索) 程序设计 1) 文件读入坐标点计算距离矩阵/读入距离矩阵 for(int i = 0; i < CityNu ...
- SA:利用SA算法解决TSP(数据是14个虚拟城市的横纵坐标)问题——Jason niu
%SA:利用SA算法解决TSP(数据是14个虚拟城市的横纵坐标)问题——Jason niu X = [16.4700 96.1000 16.4700 94.4400 20.0900 92.5400 2 ...
随机推荐
- [Ajax系列]Ajax介绍
Ajax简介: Ajax是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. What ? AJAX=异步JavaScript和XML AJAX是一种用于创建快读动态网页的技术 通过在后台语 ...
- Django form 中文提交 错误
在文件头部添加 刻解决 import sys reload(sys) sys.setdefaultencoding("utf-8")
- mysql数据库行级锁的使用(二)
项目上的另外一个需求是: 在做统计的时候需要将当前表锁定不能更新当前表记录 直接上代码 package com.robert.RedisTest; import java.sql.Connection ...
- Linux 查看文件内容
cat 由第一行开始显示档案内容 格式: cat [选项] [文件]... -A, --show-all 等价于 -vET -b, -- 对非空输出行编号 -e 等价于 -vE -E, --在每行 ...
- Java中为什么main()中不能创建内部类对象?
对main方法而言,虽然写在类中,它是游离于任何类之外的,因此某类的非静态内部类对它而言是不直接可见的,也就无法直接访问 . 1:非静态内部类,必须有一个外部类的引用才能创建. 2:在外部类的非静态方 ...
- RegExp正则校验之Java及R测试
前言: 正则表达式(英语:Regular Expression)原属于计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列符合某个句法规则的字符串.在很多文本编辑器里边,正则表达式通常被用 ...
- VS2013编译python源码
系统:win10 手头有个python模块,是用C写的,想编译安装就需要让python调用C编译器.直接编译发现使用的是vc9编译,不支持C99标准(两个槽点:为啥VS2008都还不支持C99?手头这 ...
- 【VS2013】设定Nuget代理
@tags "visual studio 2013" nuget vs2013中用nuget想必是一件很爽的事情,就像java里面用maven来安装各种包一样.有时候网络不好,nu ...
- JQuery获取子节点的第一个元素
$.children()//全部子节点 $.children(':first')//子节点的第一个
- fedora22有时不能启动
[3.327871][drm:intel_set_pch_fifo_underrun_reporting [i915]] *ERROR* uncleared pch fifo underrun on ...