详解xml文件描述,读取方法以及将对象存放到xml文档中,并按照指定的特征寻找的方案
主要的几个功能:
1.完成多条Emp信息的XML描述
2.读取XML文档解析Emp信息
3.将Emp(存放在List中)对象转换为XML文档
4.在XML文档中查找指定特征的Emp信息
dom4j,jaxen 官网下载页面: http://sourceforge.net/projects/dom4j/files/dom4j-2.0.0-ALPHA-2/
也可以在网盘上面下载:http://yunpan.cn/cwaNde7UYN83d 提取码 e247
本文作者:souvc
本文出自:http://www.cnblogs.com/liuhongfeng/p/4572923.html
1 完成多条Emp信息的XML描述
1.1 问题
现有多条Emp信息数据,如表-1所示:
表- 1 Emp信息数据
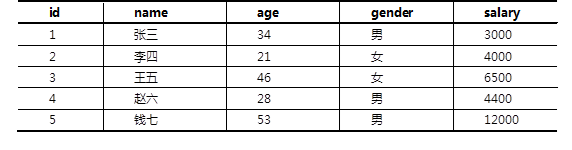
表-1中,每一行数据表示一条Emp信息。要求完成表-1中Emp信息数据的XML描述。
1.2 步骤
实现此案例需要按照如下步骤进行。
步骤一:创建XML文件
首先,创建名为EmpList.xml的XML文件;然后,在该文件中使用处理指令设置属性version以及属性encoding的值,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
步骤二:确定根元素
XML要求必须有根元素,所谓根元素就是不被其它元素包围,并且根元素只能有一个。本案例使用<list>作为根元素,表示该元素内可以包含多条子元素作为Emp信息数据,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?> <list> </list>
注意,在该文档中,不能再定义与list平级的XML元素。
步骤三:定义表示Emp信息数据的元素
首先,在根元素 <list> 下,定义一个子元素 <emp></emp>,用于表示一条Emp信息,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp>
</emp>
</list>
步骤四:为 <emp> 元素定义 id 属性
为元素 <emp> 定义属性id,用于表示Emp信息数据中的id,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
</emp>
</list>
步骤五:为 <emp> 元素定义子元素
为元素 <emp> 定义子元素 <name>、<age>、<gender> 和 <salary>,分别表示Emp信息数据中的name、age、gender以及salary。并为这四个子元素添加文本信息,以记载 Emp 的相关信息数据,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
<name>张三</name>
<age>34</age>
<gender>男</gender>
<salary>3000</salary>
</emp>
</list>
步骤六:实现多条Emp信息数据的XML描述
一个 <emp> 元素表示一条 Emp 数据,因此,可以用多个 <emp> 元素来描述剩余的多条Emp信息数据。代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
<name>张三</name>
<age>34</age>
<gender>男</gender>
<salary>3000</salary>
</emp>
<emp id="2">
<name>李四</name>
<age>21</age>
<gender>女</gender>
<salary>4000</salary>
</emp>
<emp id="3">
<name>王五</name>
<age>46</age>
<gender>女</gender>
<salary>6500</salary>
</emp>
<emp id="4">
<name>赵六</name>
<age>28</age>
<gender>男</gender>
<salary>4400</salary>
</emp>
<emp id="5">
<name>钱七</name>
<age>53</age>
<gender>男</gender>
<salary>12000</salary>
</emp>
</list>
1.3 完整代码
本案例中,EmpList.xml文件的完整内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
<name>张三</name>
<age>34</age>
<gender>男</gender>
<salary>3000</salary>
</emp>
<emp id="2">
<name>李四</name>
<age>21</age>
<gender>女</gender>
<salary>4000</salary>
</emp>
<emp id="3">
<name>王五</name>
<age>46</age>
<gender>女</gender>
<salary>6500</salary>
</emp>
<emp id="4">
<name>赵六</name>
<age>28</age>
<gender>男</gender>
<salary>4400</salary>
</emp>
<emp id="5">
<name>钱七</name>
<age>53</age>
<gender>男</gender>
<salary>12000</salary>
</emp>
</list>
2 读取XML文档解析Emp信息
2.1 问题
解析上一案例中创建的XML文档EmpList.xml。首先,将每一个<emp>节点中的属性和子元素封装为一个Emp对象;然后,将Emp对象存储到List集合中并输出到控制台。
封装emp对象的代码:
package com.souvc.xml;
public class Emp {
private int id;
private String name;
private int age;
private String gender;
// private String element;
private double salary;
public Emp() {
}
public Emp(int id, String name, int age, String gender, double salary) {
super();
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public String toString() {
return "id=" + id + ",name=" + name + ",age=" + age + ",gender=" + gender
+ ",salary=" + salary;
}
}
2.2 方案
dom4j是一个Java的XML API,用来读写XML文件。dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极端易用的特点,同时它也是一个开放源代码的软件。使用dom4j来实现对XML文档的解析,详细过程如下:
1)使用dom4j需要导入dom4j对应的jar包。
dom4j,jaxen 官网下载页面: http://sourceforge.net/projects/dom4j/files/dom4j-2.0.0-ALPHA-2/
也可以在网盘上面下载:http://yunpan.cn/cwaNde7UYN83d 提取码 e247
2)创建SAXReader类的对象来实现读取XML文档,代码如下:
SAXReader reader = new SAXReader();
3)使用SAXReader类的read方法获取Document对象,Document 对象是一棵文档树的根,可为我们提供对文档数据的最初(或最顶层)的访问入口,代码如下:
Document doc = reader.read(new File("EmpList.xml"));
4)使用Document对象的getRootElement方法获取要解析的XML文档的根元素,该方法返回值类型为Element。 Element 对象表示 XML文档中的元素。元素可包含属性、其它元素或文本。如果元素含有文本,则在文本节点中表示该文本,代码如下:
Element root = doc.getRootElement();
5)接下来,可以使用Element对象提供的方法继续解析XML文档,例如:其elements方法用来获取当前元素下的所有子元素,代码如下:
List<Element> elements = root.elements();
2.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:导入dom4j对应的jar包
在当前工程下导入dom4j对应的jar包。
dom4j,jaxen 官网下载页面: http://sourceforge.net/projects/dom4j/files/dom4j-2.0.0-ALPHA-2/
也可以在网盘上面下载:http://yunpan.cn/cwaNde7UYN83d 提取码 e247
并且把EmpList.xml 文件放到工程目录下面,方便读取。

步骤二:新建类及测试方法
首先,新建类TestDom;然后在该类中新建测试方法testReadXml,代码如下所示:
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
}
步骤三:创建SAXReader类的对象,获取Document对象
创建SAXReader类的对象来实现读取XML文档;然后,使用SAXReader类的read方法获取Document对象,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤四:获取根元素
使用Document对象的getRootElement方法获取EmpList.xml文档的根元素,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤五:获取<list>节点下的所有子元素
使用Element对象的elements方法获取<list>节点下的所有子元素,即所有的<emp>节点,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤六:封装Emp对象,存储到List集合中
1)创建存储的数据类型为Emp类型的List集合emps;
2)循环上一步中的elements集合,每循环一次获取一个emp元素。在循环中使用Element对象的attribute方法获取id 属性对应的Attribute对象,再使用Attribute对象的getValue方法就可以获取到属性id对应的文本信息,即Emp对象的属性id的 信息;
3)在循环中,使用Element对象的elementText方法获取节 点<name>、<age>、<gender>以及<salary>对应的文本信息,即Emp对象的属 性name、age、gender以及salary。
4)在循环中,将上述获取到的信息封装为Emp对象,存储到集合emps中。
代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
// 保存所有员工对象的集合
List<Emp> emps = new ArrayList<Emp>();
for (Element element : elements) {
int id = Integer.parseInt(element.attribute("id").getValue());
String name = element.elementText("name");
int age = Integer.parseInt(element.elementText("age"));
String gender = element.elementText("gender");
double salary = Double.parseDouble(element
.elementText("salary"));
Emp emp = new Emp(id, name, age, gender, salary);
emps.add(emp);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤七:输出集合
将emps集合的信息输出到控制台,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
// 保存所有员工对象的集合
List<Emp> emps = new ArrayList<Emp>();
for (Element element : elements) {
int id = Integer.parseInt(element.attribute("id").getValue());
String name = element.elementText("name");
int age = Integer.parseInt(element.elementText("age"));
String gender = element.elementText("gender");
double salary = Double.parseDouble(element
.elementText("salary"));
Emp emp = new Emp(id, name, age, gender, salary);
emps.add(emp);
}
System.out.println("解析完毕");
System.out.println(emps);
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤八:运行
运行testReadXml方法,控制台输出结果如下所示:
解析完毕
解析完毕
[id=1,name=张三,age=34,gender=男,salary=3000.0, id=2,name=李四,age=21,gender=女,salary=4000.0, id=3,name=王五,age=46,gender=女,salary=6500.0, id=4,name=赵六,age=28,gender=男,salary=4400.0, id=5,name=钱七,age=53,gender=男,salary=12000.0]
从输出结果可以看出,已经对EmpList.xml文档进行解析,将每一个<emp>节点中的属性和子元素封装为一个Emp对象并将Emp对象存储到List集合中。
2.4 完整代码
本案例中,类TestDom的完整代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用DOM解析XML文件
*/
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
// 保存所有员工对象的集合
List<Emp> emps = new ArrayList<Emp>();
for (Element element : elements) {
int id = Integer.parseInt(element.attribute("id").getValue());
String name = element.elementText("name");
int age = Integer.parseInt(element.elementText("age"));
String gender = element.elementText("gender");
double salary = Double.parseDouble(element
.elementText("salary"));
Emp emp = new Emp(id, name, age, gender, salary);
emps.add(emp);
}
System.out.println("解析完毕");
System.out.println(emps);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3 将Emp(存放在List中)对象转换为XML文档
3.1 问题
在List集合中存储了如下数据:
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
请将集合emps中的所有Emp对象转换为XML文件的形式。
3.2 方案
使用dom4j建立XML文档的过程如下:
1)创建文档对象,代码如下:
Document doc = DocumentHelper.createDocument();
2)创建根节点,代码如下:
Element root = doc.addElement("list");
3)在节点下添加注释、属性、子节点,Element提供如下方法:
addComment:方法添加注释 addAttribute:添加属性 addElement:添加子元素
4)通过XMLWriter 生成物理文件。
3.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:添加测试方法testWriteXml
首先在TestDom类中新建测试方法testWriteXml;然后在该测试方法中,添加List集合存储Emp对象的代码,代码如下所示:
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
public class TestDom {
/**
* 测试写xml
*/
@Test
public void testWriteXml() {
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
}
}
步骤二:创建文档对象
使用DocumentHelper类的静态方法createDocument创建文档对象Document,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 测试写xml
*/
@Test
public void testWriteXml() {
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
try {
Document doc = DocumentHelper.createDocument();
} catch (Exception e) {
e.printStackTrace();
}
}
步骤三:创建根节点
使用Document类的addElement方法,创建根节点<list>,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 测试写xml
*/
@Test
public void testWriteXml() {
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
try {
Document doc = DocumentHelper.createDocument();
// 添加根标记
Element root = doc.addElement("list");
} catch (Exception e) {
e.printStackTrace();
}
}
步骤四:添加子元素
首先,循环集合emps,在循环中获取Emp对象的信息;然后,在循环中使用Element类的addAttribute方法在该元素下添加 属性,属性的值为对应Emp对象中的成员变量的值;使用addElement方法在该元素下添加子元素;使用addText方法为该子元素添加文本,该文 本也为对应Emp对象中成员变量的值,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 测试写xml
*/
@Test
public void testWriteXml() {
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
try {
Document doc = DocumentHelper.createDocument();
// 添加根标记
Element root = doc.addElement("list");
for (Emp emp : emps) {
// 向根元素中添加名为emp的子元素
Element ele = root.addElement("emp");
// 为emp元素添加属性id,其值为cp
ele.addAttribute("id", emp.getId() + "");
ele.addElement("name").addText(emp.getName());
ele.addElement("age").addText(emp.getAge() + "");
ele.addElement("gender").addText(emp.getGender());
ele.addElement("salary").addText(emp.getSalary() + "");
}
} catch (Exception e) {
e.printStackTrace();
}
}
步骤五:生成物理文件
通过XMLWriter 生成物理文件,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 测试写xml
*/
@Test
public void testWriteXml() {
List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000));
try {
Document doc = DocumentHelper.createDocument();
// 添加根标记
Element root = doc.addElement("list");
for (Emp emp : emps) {
// 向根元素中添加名为emp的子元素
Element ele = root.addElement("emp");
// 为emp元素添加属性id
ele.addAttribute("id", emp.getId() + "");
ele.addElement("name").addText(emp.getName());
ele.addElement("age").addText(emp.getAge() + "");
ele.addElement("gender").addText(emp.getGender());
ele.addElement("salary").addText(emp.getSalary() + "");
}
// 写出
XMLWriter writer = new XMLWriter();
FileOutputStream fos = new FileOutputStream("emps.xml");
writer.setOutputStream(fos);
writer.write(doc);
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
步骤六:运行
运行testWriteXml方法,会在当前工程目录下生成emps.xml文件,该文件中的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<list>
<emp id="1">
<name>张三</name>
<age>33</age>
<gender>男</gender>
<salary>9000.0</salary>
</emp>
<emp id="2">
<name>李四</name>
<age>26</age>
<gender>男</gender>
<salary>5000.0</salary>
</emp>
<emp id="3">
<name>王五</name>
<age>48</age>
<gender>男</gender>
<salary>34000.0</salary>
</emp>
</list>
3.4 完整代码
本案例的完整代码如下所示:
package com.souvc.xml; import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List; import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test; public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
// 保存所有员工对象的集合 List<Emp> emps = new ArrayList<Emp>(); for (Element element : elements) {
int id = Integer.parseInt(element.attribute("id").getValue());
String name = element.elementText("name");
int age = Integer.parseInt(element.elementText("age"));
String gender = element.elementText("gender");
double salary = Double.parseDouble(element
.elementText("salary"));
Emp emp = new Emp(id, name, age, gender, salary);
emps.add(emp); } System.out.println("解析完毕"); System.out.println(emps);
} catch (Exception e) {
e.printStackTrace();
} } /**
*
* 测试写xml
*
*/
@Test
public void testWriteXml() { List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000)); try {
Document doc = DocumentHelper.createDocument();
// 添加根标记
Element root = doc.addElement("list");
for (Emp emp : emps) { // 向根元素中添加名为emp的子元素 Element ele = root.addElement("emp"); // 为emp元素添加属性id,其值为cp ele.addAttribute("id", emp.getId() + ""); ele.addElement("name").addText(emp.getName()); ele.addElement("age").addText(emp.getAge() + ""); ele.addElement("gender").addText(emp.getGender()); ele.addElement("salary").addText(emp.getSalary() + ""); } // 写出 XMLWriter writer = new XMLWriter(); FileOutputStream fos = new FileOutputStream("emps.xml"); writer.setOutputStream(fos); writer.write(doc);
System.out.println("生成文档完毕!");
writer.close(); } catch (Exception e) {
e.printStackTrace();
} } }
4 在XML文档中查找指定特征的Emp信息
4.1 问题
在上一案例中,我们创建了emps.xml文件,本案例要求查找该文件中属性id的值为2的<emp>节点,并读取该节点下子节点<name>的文本信息。另外,要求使用XPath来实现。
4.2 方案
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。我们使用DOM定位节点时,大部分时间需要一层一层的处理,如果有了XPath,我们定位节点将变得很轻松。它可以根据路 径,属性,甚至是条件进行节点的检索。例如本案例中,检索属性id的值为2的<emp>节点,则可以使用如下路径表达式:
/list/emp[@id='2']
上述表达式中还使用谓语条件。所谓"谓语条件",就是对路径表达式的附加条件。所有的条件,都写在方括号"[]"中,表示对节点进行进一步的筛选。
4.3 步骤
实现此案例需要按照如下步骤进行。
步骤一:新建测试方法
在TestDom类中新建测试方法findId,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用XPath查找指定信息
*/
@Test
public void findId() {
}
}
步骤二:创建SAXReader类的对象,获取Document对象
首先,创建SAXReader类的对象来实现读取XML文档;然后,使用SAXReader类的read方法获取Document对象,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用XPath查找指定信息
*/
@Test
public void findId() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("emps.xml"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤三: 使用XPath和谓语条件查找节点
使用Element对象的selectNodes方法,获取XPath和谓语条件为“/list/emp[@id='2']”的所有元素,即查找到所有id为2的emp元素,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用XPath查找指定信息
*/
@Test
public void findId() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("emps.xml"));
// 查找id为2的用户信息
List list = doc.selectNodes("/list/emp[@id='2']");
System.out.println("选取了:" + list.size() + "条数据");
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤四: 获取<emp>节点下<name>子节点的文本信息
循环遍历上一步得到的list集合,在循环中使用Element对象的elementText方法获取<emp>节点下<name>子节点的文本信息,代码如下所示:
import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class TestDom {
/**
* 使用XPath查找指定信息
*/
@Test
public void findId() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("emps.xml"));
// 查找id为1的用户信息
List list = doc.selectNodes("/list/emp[@id='2']");
System.out.println("选取了:" + list.size() + "条数据");
for (Object o : list) {
Element e = (Element) o;
System.out.println("name:" + e.elementText("name"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
步骤五:运行
运行findId方法,控制台输出结果如下:
选取了:1条数据
name:李四
从输出结果可以看出,已经查找到了emps.xml文件中属性id的值为2的<emp>节点,并读取了该节点下子节点<name>的文本信息。
4.4 完整代码
本案例的完整代码如下所示:
package com.souvc.xml; import java.io.File;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List; import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test; public class TestDom {
/**
* 使用DOM解析XML文件
*/
@Test
public void testReadXml() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("EmpList.xml"));
// 获取根节点list
Element root = doc.getRootElement();
// 获取list下的所有子节点emp
List<Element> elements = root.elements();
// 保存所有员工对象的集合 List<Emp> emps = new ArrayList<Emp>(); for (Element element : elements) {
int id = Integer.parseInt(element.attribute("id").getValue());
String name = element.elementText("name");
int age = Integer.parseInt(element.elementText("age"));
String gender = element.elementText("gender");
double salary = Double.parseDouble(element
.elementText("salary"));
Emp emp = new Emp(id, name, age, gender, salary);
emps.add(emp); } System.out.println("解析完毕"); System.out.println(emps);
} catch (Exception e) {
e.printStackTrace();
} } /**
*
* 测试写xml
*
*/
@Test
public void testWriteXml() { List<Emp> emps = new ArrayList<Emp>();
emps.add(new Emp(1, "张三", 33, "男", 9000));
emps.add(new Emp(2, "李四", 26, "男", 5000));
emps.add(new Emp(3, "王五", 48, "男", 34000)); try {
Document doc = DocumentHelper.createDocument();
// 添加根标记
Element root = doc.addElement("list");
for (Emp emp : emps) { // 向根元素中添加名为emp的子元素 Element ele = root.addElement("emp"); // 为emp元素添加属性id,其值为cp ele.addAttribute("id", emp.getId() + ""); ele.addElement("name").addText(emp.getName()); ele.addElement("age").addText(emp.getAge() + ""); ele.addElement("gender").addText(emp.getGender()); ele.addElement("salary").addText(emp.getSalary() + ""); } // 写出 XMLWriter writer = new XMLWriter(); FileOutputStream fos = new FileOutputStream("emps.xml"); writer.setOutputStream(fos); writer.write(doc);
System.out.println("生成文档完毕!");
writer.close(); } catch (Exception e) {
e.printStackTrace();
} } /**
*
* 使用XPath查找指定信息
*
*/ @Test
public void findId() {
try {
// 创建SAXReader
SAXReader reader = new SAXReader();
// 读取指定文件
Document doc = reader.read(new File("emps.xml"));
// 查找id为2的用户信息
List list = doc.selectNodes("/list/emp[@id='2']");
System.out.println("选取了:" + list.size() + "条数据");
for (Object o : list) {
Element e = (Element) o;
System.out.println("name:" + e.elementText("name"));
}
} catch (Exception e) { e.printStackTrace(); }
} }
提供一下源码:http://yunpan.cn/cw7g6bmbAySAV 提取码 3e37
本文作者:souvc
本文出自:http://www.cnblogs.com/liuhongfeng/p/4572923.html
详解xml文件描述,读取方法以及将对象存放到xml文档中,并按照指定的特征寻找的方案的更多相关文章
- python之xml 文件的读取方法
''' xml 文件的读取方法 ''' #!/usr/bin/env python # -*- coding: utf- -*- import xml.etree.ElementTree as ET ...
- [转]文件IO详解(二)---文件描述符(fd)和inode号的关系
原文:https://www.cnblogs.com/frank-yxs/p/5925563.html 文件IO详解(二)---文件描述符(fd)和inode号的关系 ---------------- ...
- python 解析docx文档的方法,以及利用Python从docx文档提取插入的文本对象和图片
首先安装docx模块,通过pip install docx或者在docx官方链接上下载安装都可以 下面来看下如何解析docx文档:文档格式如下 有3个部分组成 1 正文:text文档 2 一个表格. ...
- Cookie的使用、Cookie详解、HTTP cookies 详解、获取cookie的方法、客户端获取Cookie、深入解析cookie
Cookie是指某些网站为了辨别用户身份.进行session跟踪而存储在用户本地终端上的数据(通常经过加密),比如说有些网站需要登录才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我 ...
- c#操作XML文件的通用方法
转载地址:http://www.studyofnet.com/news/36.html 原址没找到 sing System; using System.Data; using System.Confi ...
- ubuntu apache2配置详解(含虚拟主机配置方法)
ubuntu apache2配置详解(含虚拟主机配置方法) 在Windows下,Apache的配置文件通常只有一个,就是httpd.conf.但我在Ubuntu Linux上用apt-get inst ...
- WinForm中DataGridView对XML文件的读取
转自http://www.cnblogs.com/a1656344531/archive/2012/11/28/2792863.html c#读取XML XML文件是一种常用的文件格式,例如Win ...
- (转)linux命令详解之useradd命令使用方法
linux命令详解之useradd命令使用方法 原文:http://blog.csdn.net/u011537073/article/details/51987121 Linux 系统是一个多用户多任 ...
- Java文件操作①——XML文件的读取
一.邂逅XML 文件种类是丰富多彩的,XML作为众多文件类型的一种,经常被用于数据存储和传输.所以XML在现今应用程序中是非常流行的.本文主要讲Java解析和生成XML.用于不同平台.不同设备间的数据 ...
随机推荐
- ok6410 android driver(5)
Test the android driver by JNI (Java Native Interface), In the third article, we know how to compile ...
- easyui-treegrid节点选择
easyui-treegrid本身不能实现选中父节点子节点全选,必须通过另外的方法来实现,这里说下如何通过修改节点样式添加checkbox来实现级联选择效果 首先需要格式化节点的样式 formatte ...
- Unity烂笔头1-自定义INSPECTOR属性窗口节点项
1.添加输入框和标签 LevelScript: using UnityEngine; using System.Collections; public class LevelScript : Mono ...
- javascript运算符的优先级
最基木的运算符优先级就是所谓的“先乘除,后加减”.对于优先顺序处于同一层次上的运算符,按照从左到右出现的顺序计算.下面给出javascript定义的所有运算符的优先级.运算符 优先顺序成员选择.括号. ...
- 字符串与json之间的相互转化
先在数据库中建表: 再从后台将表取出来,然后转化为json格式,再将其执行ToString()操作后,赋值给前台的隐藏域. 注意引用using Newtonsoft.Json; 前台利用js将隐藏域中 ...
- 操作AppConfig.xml中AppSettings对应值字符串
//查询AppSettings的key public static List sql() { List list = new List(); ...
- 微软Asp.net MVC5生命周期流程图
.NET WEB Development blog 发布了Asp.net MVC5生命周期文档, 这个文档类似Asp.net应用程序生命周期,您以前开发ASP.NET WEB应用程序应该 ...
- Java中的GOF23(23中设计模式)--------- 工厂模式(Factory)
Java中的GOF23(23中设计模式)--------- 工厂模式(Factory) 在给大家介绍工厂模式之前,我想和大家聊聊面向对象的那点事,在这里,引入三个概念. 开闭原则(Open Close ...
- [ASP.NET MVC] 使用Bootstrap套件
[ASP.NET MVC] 使用Bootstrap套件 前言 在开发Web项目的时候,除了一些天赋异禀的开发人员之外,大多数的开发人员应该都跟我一样,对于如何建构出「美观」的用户接口而感到困扰.这时除 ...
- wap网站safari浏览器和微信cooke不能登录问题
wap网站safari浏览器cooke不能登录问题: http://wenku.baidu.com/link?url=VnPxl43PySYVygt09vkQ7xwxOD0JCXNtw3Fx7100j ...