kafka背着你做了什么?
Kafka中有broker、主题、分区、副本等概念,底层有日志和日志分片。
我们先简单介绍一下这些概念,做个类比。
broker可以简单理解为一台物理机,其实一台机器上可以有多个broker进程,但是为防止单机故障导致多个broker崩溃的情况出现,一般一台机器上只运行一个broker进程。所以把broker理解成一台服务器就好。
主题的出现是为了让消息队列能从逻辑上区分不同的消息类型。如果没有主题这个概念,那么消息队列就变成大杂烩了,什么类型的消息都有,都混在一起。就好比一个excel表格中只有一个sheet页面,所有的学生信息、课程信息、成绩信息等不同类型的消息都塞到一个表格中了,那么就会感觉很乱。主题其实可以类比excel中的sheet页,一个excel中可以有多个sheet页面,每个sheet页面存放不同类型的信息,比如sheet1页存放学生信息,sheet2页存放课程信息,sheet3存放成绩信息等。
分区的出现是为了解决单个文件读写的瓶颈问题。我们还是拿excel表格作为例子,现在有一个员工表,公司有一万名员工,如果只有一份excel表格,大家都要往里填写自己的员工信息,那么这个1个员工在填写的时候,其他9999人只能干等着。这样串行的方式其实是效率很低的。那么如果引入分区的概念,比如我把excel表复制100份,然后分别重命名一下,员工1-99号.xls 员工100-199号.xls 员工200-299号.xls········这样就相当于有100个员工可以同时写入他们的信息到各自对应的excel表中了。只要读取所有员工信息的时候能先进行合并然后从100个文件中读取就行。这样理论上就实现了100倍的提速。所以分区的出现简单说是为了提升写入消息的并发度,从而提升写入速度。
副本的出现是为了解决某个分区突然坏掉的情况。还是拿上面的excel表格举例。100个excel表格中的数据是互不重叠的,那么如果1个excel文件出现损坏打不开了。那么其实相当于就有100个员工信息丢失了。这是一个大问题,需要解决。那么解决方法其实很简单,现在好多人在用的wps自动备份、百度云盘自动备份、坚果云自动备份。只要检测到你的excel文件有变化,就会自动上传一份新的excel文件到云端。如果你本机的excel崩溃了打不开了,那么从wps云盘或者百度云盘或者坚果云下载一份回来就可以恢复数据。kafka也是类似的处理,把每个分区的数据都备份到不同的物理机器上去,平时99%的时间是派不上用场的,只有主分区挂了,这些备份分区才有转正的机会。
那么下面来说说当我们用kafka命令行工具来创建一个topic的时候,它底层做了什么事情。
比如我们用
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic page_visits
这个语句作用是:创建一个topic,topic名称是page_visits。要分成个5分区,这5个分区都不需要副本。
注意:--replication-factor 1 不代表复制一份的意思,而是每个分区只有一份文件,也就是1代表只有主分区,没有副本。2代表1个主分区,一个副本分区。设置为1的时候相当于坏了一个就丢了一部分数据。生产环境建议3起步。
当运行了这个语句后,因为我们是单机版本的kafka,所以所有的5个分区都会分布在这台机器上。运行完这个脚本,可以发现kafka日志存储文件夹中多出了5个文件夹。名称分别是page_visits-0 ; page_visits-1 ; page_visits-2 ; page_visits-3 ; page_visits-4 ;如图所示:

每个 文件夹里有2个文件,如下图

这个.log结尾的就是存储消息的文件了,.index结尾的是索引文件。
那么如果我往这个消息队列中大量插入消息,会变成什么样子呢?
这里我运行一个测试程序指定往page_visits-0分区大量插入消息后,我们的page_visits-0文件夹下的文件变成了如下所示:

这些.log结尾的文件其实都是日志分片。
这里我把log.segment.bytes 设置为10MB
当我不断向page_visits-0分区插入消息的时候,它会不断检查最初的000000000000000.log是不是已经达到10MB大小了。如果超过了10MB大小了,那么00000000000.log就会分裂成为两个文件,原来的00000000000.log被关闭,禁止继续写入。紧接着的消息都会被写入到新的.log文件中。在这里我们可以看到,第二个.log文件是0000000000000368769.log。那么为什么第二个文件的名字是0000000000000368769.log呢?因为是规则是第二个文件名为上一个segment文件最后一条消息的offset值。也就是说0000000000000.log这个文件总共存储了368769条消息。发送给page_visits-0分区的第368770条消息就会被存储为000000000000368769.log这个文件的第一条消息。以此类推00000000000737337.log的第一条消息就是page_visits-0分区的第737338条消息。
到这里,我们对.log文件大致有个了解了。
那么我们到这里先思考一个问题。假如我们想读取page_visits-0分区的第737399条数据,kafka底层是如何扫描的?
假如没有.index文件,只有.log文件,那么方法就是先把所有的.log结尾的文件名中的数字都拿出来,升序排列。找到737399是介于737337和1105814之间,那么就可以确定是在00000000000737337.log这个文件中,这时候就只能从头扫描到最后。这个顺序遍历是非常耗时的。所以就有了.index文件的出现。.index构造非常简单,就是以更细致的间隔记录一个值
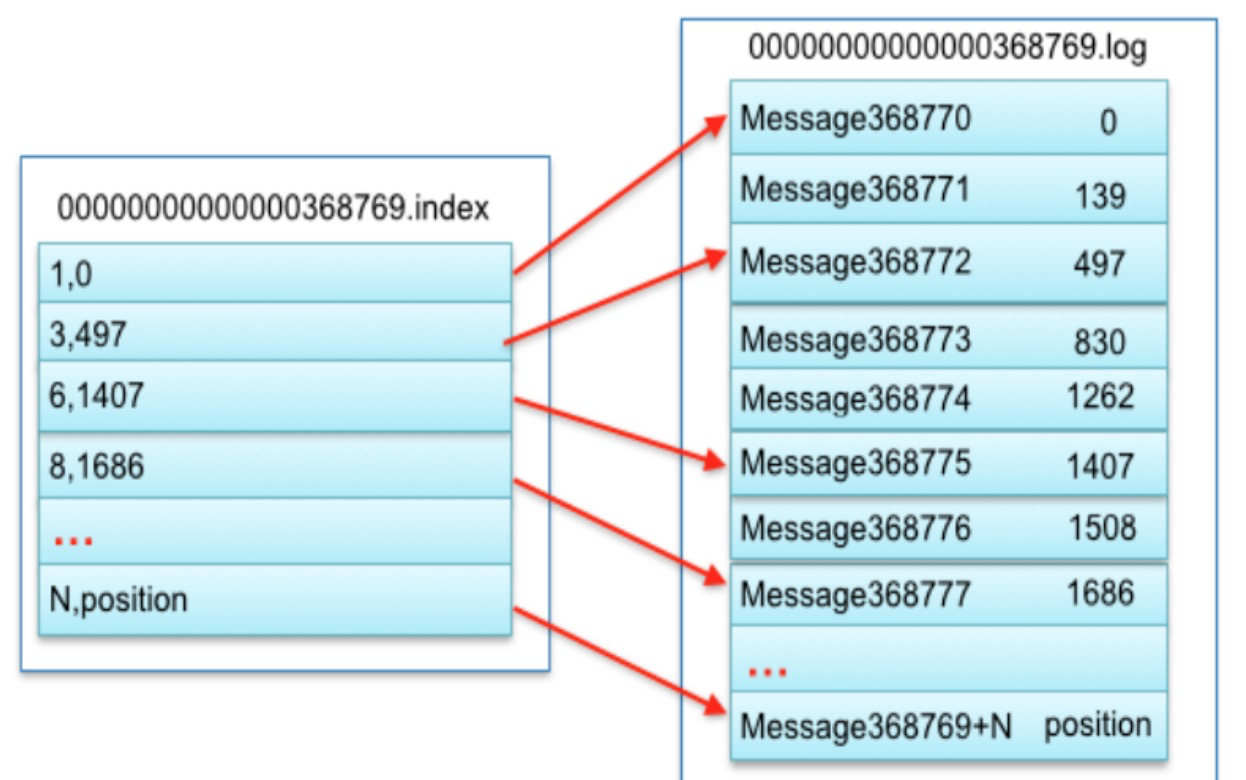
如上图,我逐个解释一下,首先看到左侧文件是0000000000368769.index文件,右侧是0000000000368769.log文件。
第一行 1,0 第一个1代表第368770(368769+1)条记录所在的位置是0000000000368769.log文件中物理偏移地址为0的地方
第二行 3,497 第一个3代表第368772(368769+3)条记录所在的位置是0000000000368769.log文件中物理偏移地址为497的地方
第三行 6,1407 第一个6代表第368775(368769+6)条记录所在的位置是0000000000368769.log文件中物理偏移地址为1407的地方
···········
有了这个索引文件,page_visits-0分区的第737399条数据就很简单了,首先我们能确定它就在00000000000737337.log这个文件中,那么737399-737337=62
所以我们去00000000000737337.index中二分查找有没有等于62的索引点,如果找到直接就能得到物理偏移地址了。如果没有刚好等于62的索引点,利用二分法查找相对offset小于或者等于62的索引条目中最大的那个相对offset。比如index中只有60和65的索引记录点,那么先返回60的索引点对应的物理偏移地址。然后从这个位置开始向后顺序遍历,直到找到page_visits-0分区的第737399条数据。
ok,今天先写到这,后续再开一篇文章对kafka中的.log文件中的存储的消息头和消息体进行一个分析。
kafka背着你做了什么?的更多相关文章
- RabbitMq、ActiveMq、Kafka和Redis做Mq对比
转载自:https://blog.csdn.net/qiqizhiyun/article/details/79848834 一.RabbitMq RabbitMQ是一个Advanced Message ...
- 消息队列之事务消息,RocketMQ 和 Kafka 是如何做的?
每个时代,都不会亏待会学习的人. 大家好,我是 yes. 今天我们来谈一谈消息队列的事务消息,一说起事务相信大家都不陌生,脑海里蹦出来的就是 ACID. 通常我们理解的事务就是为了一些更新操作要么都成 ...
- kafka使用SASL_PLAINTEXT做用户认证
使用SASL/PLAIN认证 server端1.配置brokerkafka_server_jaas.conf内容KafkaServer {org.apache.kafka.common.securit ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- kafka
2016-11-13 20:48:43 简单说明什么是kafka? Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息 ...
- Kafka如何创建topic?
Kafka创建topic命令很简单,一条命令足矣:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-facto ...
- Kafka设计解析(二)- Kafka High Availability (上)
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/04/24/KafkaColumn2 摘要 Kafka在0.8以前的版本中,并不提供High Av ...
- Kafka设计解析(一)- Kafka背景及架构介绍
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- 【原创】Kafka topic常见命令解析
本文着重介绍几个常用的topic命令行命令,包括listTopic,createTopic,deleteTopic和describeTopic等.由于alterTopic并不是很常用,本文中就不涉及了 ...
随机推荐
- Logstash学习之路(二)Elasticsearch导入json数据文件
一.数据从文件导入elasticsearch 1.数据准备: 1.数据文件:test.json 2.索引名称:index 3.数据类型:doc 4.批量操作API:bulk {"index& ...
- 关于Objects类的getClass方法为什么可以得到子类的地址的思考
这一段时间,总是很纠结为什么Objects中的getClass方法可以返回包含子类地址信息的东西(我不确定返回值类型). 因为在Java中,我们定义的父类,我想破脑袋也想不出怎么可以得到子类的信息. ...
- Apache的Mod_rewrite学习(RewriteRule重写规则的语法) 转
RewriteRuleSyntax: RewriteRule Pattern Substitution [flags] 一条RewriteRule指令,定义一条重写规则,规则间的顺序非常重要.对Apa ...
- 2018年第九届蓝桥杯B组(201806-----递增三元组)
给定三个整数数组 A = [A1, A2, - AN], B = [B1, B2, - BN], C = [C1, C2, - CN], 请你统计有多少个三元组(i, j, k) 满足: 1 < ...
- Serverless 如何应对 K8s 在离线场景下的资源供给诉求
本文整理自腾讯云云原生产品团队的专家产品经理韩沛在 Techo 开发者大会云原生专题的分享内容--Kubernetes 混部与弹性容器.本次分享主要分为三部分:基于 K8s 的应用混部.提升应用混部效 ...
- 【Java基础】枚举类与注解
枚举类与注解 枚举类的使用 当需要定义一组常量时,强烈建议使用枚举类. 枚举类的理解:类的对象只有有限个,确定的. 若枚举只有一个对象, 则可以作为一种单例模式的实现方式. 枚举类的属性: 枚举类对象 ...
- MySQL常用字符串函数和日期函数
数据函数 SELECT ABS(-8); /*绝对值*/ SELECT CEILING(9.4); /*向上取整*/ SELECT FLOOR(9.4); /*向下取整*/ SELECT RAND() ...
- a[i][j] 和 a[j][i] 有什么区别?
本文以一个简单的程序开头--数组赋值: int LEN = 10000;int[][] arr = new int[LEN][LEN]; for (int i = 0; i < LEN; i++ ...
- 【System】I/O密集型和CPU密集型工作负载之间有什么区别
CPU密集型(CPU-bound) CPU密集型也叫计算密集型,指的是系统的硬盘.内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/ ...
- 关于postgresql中numeric和decimal的精度和标度问题
精度即数的有效数字个数 2.5的有效数字个数是2,但是053.2的有效数字个数是3 标度是小数点的位数 例如numeric(2,1),即这个数必须是两位,并且小数后面最多有一位,多出来的小数会被四舍五 ...