同一份数据,Redis为什么要存两次
前言
在 Redis 中,有一种数据类型,当在存储的时候会同时采用两种数据结构来进行分别存储,那么 Redis 为什么要这么做呢?这么做会造成同一份数据占用两倍空间吗?
五种基本类型之集合对象
Redis 中的集合对象是一个包含字符串类型元素的无序集合,集合中元素唯一不可重复。
集合对象的底层数据结构有两种:intset 和 hashtable。内部通过编码来进行区分:
| 编码属性 | 描述 | object encoding命令返回值 |
|---|---|---|
| OBJ_ENCODING_INTSET | 使用整数集合实现的集合对象 | intset |
| OBJ_ENCODING_HT | 使用字典实现的集合对象 | hashtable |
intset 编码
intset(整数集合)可以保存类型为 int16_t,int32_t,int64_t 的整数值,并且保证集合中没有重复元素。
intset 数据结构定义如下(源码 inset.h 内):
typedef struct intset {
uint32_t encoding;//编码方式
uint32_t length;//当前集合中的元素数量
int8_t contents[];//集合中具体的元素
} intset;
下图就是一个 intset 的集合对象存储简图:
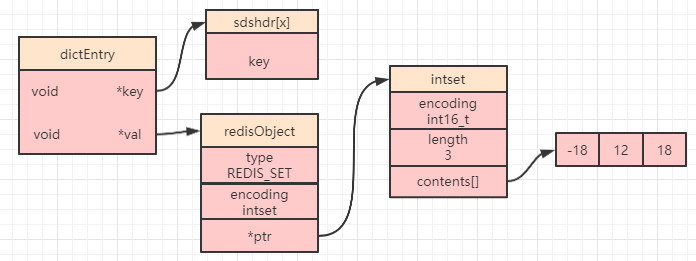
encoding
在 intset 内部的 encoding 记录了当前整数集合的数据存储类型,主要有三种:
INTSET_ENC_INT16
此时contents[]内的每个元素都是一个int16_t类型的整数值,范围是:-32768 ~ 32767(-2 的 15 次方 ~ 2 的 15 次方 - 1)。INTSET_ENC_INT32
此时contents[]内的每个元素都是一个int32_t类型的整数值,范围是:-2147483648 ~ 2147483647(-2 的 31 次方 ~ 2 的 31 次方 - 1)。INTSET_ENC_INT64
此时contents[]内的每个元素都是一个int64_t类型的整数值,范围是:-9223372036854775808 ~ 9223372036854775807(-2 的 63 次方 ~ 2 的 63 次方 - 1)。
contents[]
contents[] 虽然结构的定义上写的是 int8_t 类型,但是实际存储类型是由上面的 encoding 来决定的。
整数集合的升级
假如一开始整数集合中的元素都是 16 位的,采用 int16_t 类型来存储,此时需要再存储一个 32 位的整数,那么就需要对原先的整数集合进行升级,升级之后才能将 32 位的整数存储到整数集合内。这就涉及到了整数集合的类型升级,升级过程主要有 4 个步骤:
- 根据新添加元素的类型来扩展底层数组空间的大小,按照升级后现有元素的位数来分配新的空间。
- 将现有的元素进行类型转换,并将转换类型后的元素从后到前逐个重新放回到数组内。
- 将新元素放到数组的头部或者尾部(因为触发升级的条件就是当前数组的整数类型无法存储新元素,所以新元素要么比现有元素都大,要么就比现有元素都小)。
- 将
encoding属性修改为最新的编码,并且同步修改length属性。
PS:和字符串对象的编码一样,整数集合的类型一旦发生升级,将会保持编码,无法降级。
升级示例
假如我们有一个集合存储的
encoding是int16_t,内部存储了3个元素: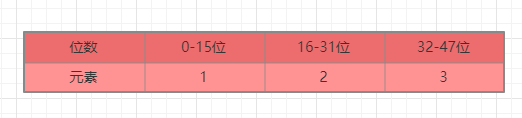
这时候需要插入一个整数
50000,发现存储不下去,而50000是一个int32_t类型整数,所以需要申请新空间,申请空间大小为4 * 32 - 48=80。

- 现在新的数组内要放置
4个元素,原来的数组排在第3,所以需要将升级后的3移动到64-95位。

- 继续将升级后的
2移动到32-63位。

- 继续将升级后的
1移动到0-31位。

- 然后会将
50000放到96-127位。

- 最后会修改
encoding和length属性,修改之后就完成了本次的升级。
hashtable 编码
hashtable 结构在前面讲述哈希对象的时候进行过详细分析,想详细了解的可以点击这里。
intset 和 hashtable 编码转换
当一个集合满足以下两个条件时,Redis 会选择使用 intset 编码:
- 集合对象保存的所有元素都是整数值。
- 集合对象保存的元素数量小于等于
512个(这个阈值可以通过配置文件set-max-intset-entries来控制)。
一旦集合中的元素不满足上面两个条件,则会选择使用hashtable编码。
集合对象常用命令
- sadd key member1 member2:将一个或多个元素
member加入到集合key当中,并返回添加成功的数目,如果元素已存在则被忽略。 - sismember key member:判断元素
member是否存在集合key中。 - srem key member1 member2:移除集合
key中的元素,不存在的元素会被忽略。 - smove source dest member:将元素
member从集合source中移动到dest中,如果member不存在,则不执行任何操作。 - smembers key:返回集合
key中所有元素。
了解了操作集合对象的常用命令,我们就可以来验证下前面提到的哈希对象的类型和编码了,在测试之前为了防止其他 key 值的干扰,我们先执行 flushall 命令清空 Redis 数据库。
依次执行如下命令:
sadd num 1 2 3 //设置 3 个整数的集合,会使用 intset 编码
type num //查看类型
object encoding num //查看编码
sadd name 1 2 3 test //设置 3 个整数和 1 个字符串的集合,会使用 hashtable 编码
type name //查看类型
object encoding name //查看编码
得到如下效果:

可以看到,当设置的元素里面只有整数时,集合使用的就是 intset 编码,当设置的元素中含有非整数时,使用的就是 hashtable 编码。
五种基本类型之有序集合对象
Redis 中的有序集合和集合的区别是有序集合中的每个元素都会关联一个 double 类型的分数,然后按照分数从小到大的顺序进行排列。换句话说,有序集合的顺序是由我们自己设值的时候通过分数来确定的。
有序集合对象的底层数据结构有两种:skiplist 和 ziplist。内部同样是通过编码来进行区分:
| 编码属性 | 描述 | object encoding命令返回值 |
|---|---|---|
| OBJ_ENCODING_SKIPLIST | 使用跳跃表实现的有序集合对象 | skiplist |
| OBJ_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象 | ziplist |
skiplist 编码
skiplist 即跳跃表,有时候也简称为跳表。使用 skiplist 编码的有序集合对象使用了 zset 结构来作为底层实现,而zset 中同时包含了一个字典和一个跳跃表。
跳跃表
跳跃表是一种有序的数据结构,其主要特点是通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
大部分情况下,跳跃表的效率可以等同于平衡树,但是跳跃表的实现却远远比平衡树的实现简单,所以 Redis 选择了使用跳跃表来实现有序集合。
下图是一个普通的有序链表,我们如果想要找到 35 这个元素,只能从头开始遍历到尾(链表中元素不支持随机访问,所以不能用二分查找,而数组中可以通过下标随机访问,所以二分查找一般适用于有序数组),时间复杂度是 O(n)。

那么假如我们可以直接跳到链表的中间,那就可以节省很多资源了,这就是跳表的原理,如下图所示就是一个跳表的数据结构示例:
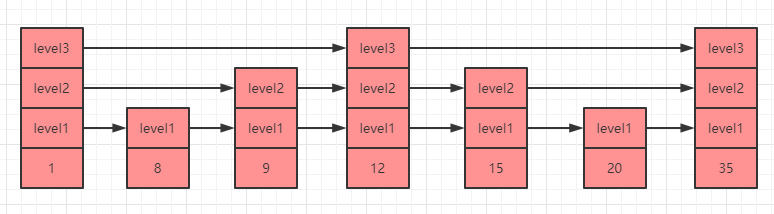
上图中 level1,level2,level3 就是跳表的层级,每一个 level 层级都有一个指向下一个相同 level 层级元素的指针,比如上图我们遍历寻找元素 35 的时候就有三种方案:
- 第
1种就是执行level1层级的指针,需要遍历7次(1->8->9->12->15->20->35)才能找到元素35。 - 第
2种就是执行level2层级的指针,只需要遍历5次(1->9->12->15->35)就能找到元素35。 - 第
3种就是执行level3层级的元素,这时候只需要遍历3次(1->12->35)就能找到元素35了,大大提升了效率。
skiplist 的存储结构
跳跃表中的每个节点是一个 zskiplistNode 节点(源码 server.h 内):
typedef struct zskiplistNode {
sds ele;//元素
double score;//分值
struct zskiplistNode *backward;//后退指针
struct zskiplistLevel {//层
struct zskiplistNode *forward;//前进指针
unsigned long span;//当前节点到下一个节点的跨度(跨越的节点数)
} level[];
} zskiplistNode;
- level(层)
level 即跳跃表中的层,其是一个数组,也就是说一个节点的元素可以拥有多个层,即多个指向其他节点的指针,程序可以通过不同层级的指针来选择最快捷的路径提升访问速度。
level 是在每次创建新节点的时候根据幂次定律(power law)随机生成的一个介于 1~32 之间的数字。
forward(前进指针)
每个层都会有一个指向链表尾部方向元素的指针,遍历元素的时候需要使用到前进指针。
span(跨度)
跨度记录了两个节点之间的距离,需要注意的是,如果指向了 NULL 的话,则跨度为 0。
backward(后退指针)
和前进指针不一样的是后退指针只有一个,所以每次只能后退至前一个节点(上图中没有画出后退指针)。
ele(元素)
跳跃表中元素是一个 sds 对象(早期版本使用的是 redisObject 对象),元素必须唯一不能重复。
score(分值)
节点的分值是一个 double 类型的浮点数,跳跃表中会将节点按照分值按照从小到大的顺序排列,不同节点的分值可以重复。
上面介绍的只是跳跃表中的一个节点,多个 zskiplistNode 节点组成了一个 zskiplist 对象:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//跳跃表的头节点和尾结点指针
unsigned long length;//跳跃表的节点数
int level;//所有节点中最大的层数
} zskiplist;
到这里你可能以为有序集合就是用这个 zskiplist 来实现的,然而实际上 Redis 并没有直接使用 zskiplist 来实现,而是用 zset 对象再次进行了一层包装。
typedef struct zset {
dict *dict;//字典对象
zskiplist *zsl;//跳跃表对象
} zset;
所以最终,一个有序集合如果使用了 skiplist 编码,其数据结构如下图所示:
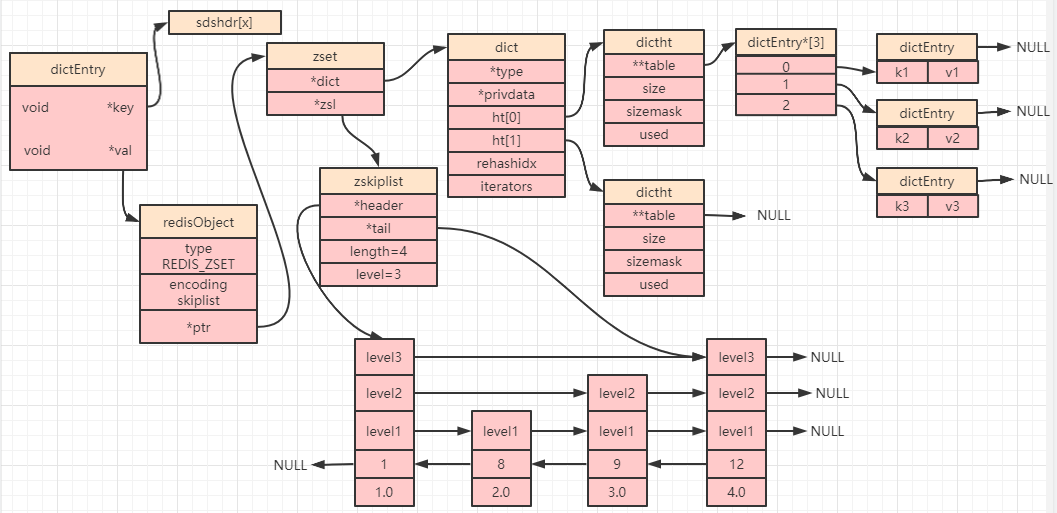
上图中上面一部分中的字典中的 key 就是对应了有序集合中的元素(member),value 就对应了分值(score)。上图中下面一部分中跳跃表整数 1,8,9,12 也是对应了元素(member),最后一排的 double 型数字就是分值(score)。
也就是说字典和跳跃表中的数据都指向了我们存储的元素(两种数据结构最终指向的是同一个地址,所以数据并不会出现冗余存储),Redis 为什么要这么做呢?
为什么同时选择使用字典和跳跃表
有序集合直接使用跳跃表或者单独使用字典完全可以独自实现,但是我们想一下,如果单独使用跳跃表来实现,那么虽然可以使用跨度大的指针去遍历元素来找到我们需要的数据,但是其复杂度仍然达到了 O(logN),而字典中获取一个元素的复杂度是 O(1),而如果单独使用字典虽然获取元素很快,但是字典是无序的,所以如果要范围查找就需要对其进行排序,这又是一个耗时的操作,所以 Redis 综合了两种数据结构来最大程度的提升性能,这也是 Redis 设计的精妙之处。
ziplist 编码
压缩列表在列表对象和哈希对象都有使用到,想详细了解的可以点击这里。
ziplist 和 skiplist 编码转换
当有序集合对象同时满足以下两个条件时,会使用 ziplist 编码进行存储:
- 有序集合对象中保存的元素个数小于
128个(可以通过配置zset-max-ziplist-entries修改)。 - 有序集合对象中保存的所有元素的总长度小于
64字节(可以通过配置zset-max-ziplist-value修改)。
有序集合对象常用命令
- zadd key score1 member1 score2 member2:将一个或多个元素(
member)及其score添加到有序集合key中。 - zscore key member:返回有序集合
key中member成员的score。 - zincrby key num member:将有序集合
key中的member加上num,num可以为负数。 - zcount key min max:返回有序集合
key中score值在[min,max]区间的member数量。 - zrange key start stop:返回有序集合
key中score从小到大排列后在[start,stop]区间的所有member。 - zrevrange key start stop:返回有序集合
key中score从大到小排列后在[start,stop]区间的所有member。 - zrangebyscore key min max:返回有序集合中按
score从小到大排列后在[min,max]区间的所有元素。注意这里默认是闭区间,但是可以在max和min的数值前面加上(或者[来控制开闭区间。 - zrevrangebyscore key max min:返回有序集合中按
score从大到小排列后在[min,max]区间的所有元素。注意这里默认是闭区间,但是可以在max和min的数值前面加上(或者[来控制开闭区间。 - zrank key member:返回有序集合中
member中元素排名(从小到大),返回的结果从0开始计算。 - zrevrank key member:返回有序集合中
member中元素排名(从大到小),返回的结果从0开始计算。 - zlexcount key min max:返回有序集合中
min和max之间的member数量。注意这个命令中的min和max前面必须加(或者[来控制开闭区间,特殊值-和+分别表示负无穷和正无穷。
了解了操作有序集合对象的常用命令,我们就可以来验证下前面提到的哈希对象的类型和编码了,在测试之前为了防止其他 key 值的干扰,我们先执行 flushall 命令清空 Redis 数据库。
在执行命令之前,我们先把配置文件中的参数 zset-max-ziplist-entries 修改为 2,然后重启 Redis 服务。
重启完成之后依次执行如下命令:
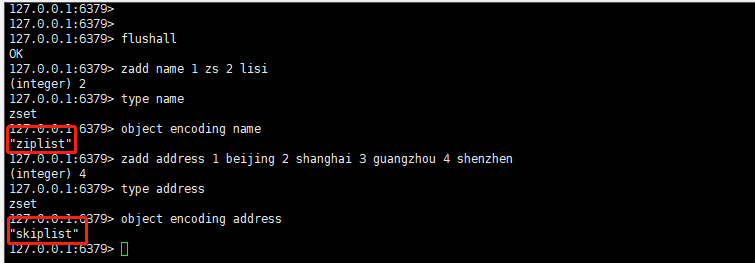
zadd name 1 zs 2 lisi //设置 2 个元素会使用 ziplist
type name //查看类型
object encoding name //查看编码
zadd address 1 beijing 2 shanghai 3 guangzhou 4 shenzhen //设置4个元素则会使用 skiplist编码
type address //查看类型
object encoding address //查看编码
得到如下效果:
总结
本文主要分析了集合对象和有序集合对象的底层存储结构 intset 和 skiplist 的实现原理,并且重点分析了有序集合如何实现排序以及为何同时使用两种数据结构(字典和跳表)同时进行进行存储数据的原因。
同一份数据,Redis为什么要存两次的更多相关文章
- 全球共有多少MySQL实例在运行?这里有一份数据
摘要 Shadowserver Foundation在5月31日发布了一份全网的MySQL扫描报告,共发现了暴露在公网的360万个MySQL实例.因为这份报告基数够大,而且信息也非常完整,从数据库专业 ...
- IM群聊消息究竟是存1份(即扩散读)还是存多份(即扩散写)?
1.前言 IM的群聊消息,究竟存1份(即扩散读方式)还是存多份(即扩散写方式)? 上一篇文章<IM群聊消息的已读回执功能该怎么实现?>是说,“很容易想到,是存一份”,被网友们骂了,大家争论 ...
- 【运维技术】redis(一主两从三哨兵模式搭建)记录
redis(一主两从三哨兵模式搭建)记录 目的: 让看看这篇文章的的人能够知道:软件架构.软件的安装.配置.基本运维的操作.高可用测试.也包含我自己,能够节省对应的时间. 软件架构: 生产环境使用三台 ...
- MySQL查询今天/昨天/本周、上周、本月、上个月份数据的sql代码
MySQL查询本周.上周.本月.上个月份数据的sql代码 作者: 字体:[增加 减小] 类型:转载 时间:2012-11-29我要评论 MySQL查询的方式很多,下面为您介绍的MySQL查询实现的是查 ...
- Java中double类型的数据精确到小数点后两位
Java中double类型的数据精确到小数点后两位 多余位四舍五入,四种方法 一: double f = 111231.5585;BigDecimal b = new BigDecimal(f); d ...
- hdfs du命令是算的一份数据
As you can see, hadoop fsck and hadoop fs -dus report the effective HDFS storage space used, i.e. th ...
- 用easyui从servlet传递json数据到前端页面的两种方法
用easyui从servlet传递json数据到前端页面的两种方法 两种方法获取的数据在servlet层传递的方法相同,下面为Servlet中代码,以查询表中所有信息为例. //重写doGet方法 p ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略.redis 提供 6种数据淘汰策略: voltile-lru:从已设置过期时间的数据集(server.db[i].expires) ...
随机推荐
- [日常摸鱼]luogu3398仓鼠找sugar-树链剖分
https://www.luogu.org/problemnew/show/P3398 题意:一颗$n$个点的树,$q$次询问两条链$(a,b),(c,d)$是否有交 树剖裸题orz 一开始的想法是求 ...
- Tomcat文件包含漏洞的搭建与复现:CVE-2020-1938
Tomcat文件包含漏洞的搭建与复现:CVE-2020-1938 漏洞描述 2020年2月20日,国家信息安全漏洞共享平台(CNVD)发布了Apache Tomcat文件包含漏洞(CNVD-2020- ...
- angular8 大地老师学习笔记---第九课
父组件:news组件 <app-header [title]="title" [msg]="msg" [run]='run' [home]='this'& ...
- redis源码学习之lua执行原理
聊聊redis执行lua原理 从一次面试场景说起 "看你简历上写的精通redis" "额,还可以啦" "那你说说redis执行lua脚本的原理&q ...
- win10新版wsl2使用指南
本篇文章会介绍win10中wsl2的安装和使用以及遇到的常见问题比如如何固定wsl2地址等问题的总结. 一.wsl2简介 wsl是适用于 Linux 的 Windows 子系统,安装指南:适用于 Li ...
- Abp vNext异常处理的缺陷/改造方案
吐槽Abp Vnext异常处理! 哎呀,是一个喷子 目前项目使用Abp VNext开发,免不了要全局处理异常.提示服务器异常信息. 1. Abp官方异常处理 Abp项目默认会启动内置的异常处理,默认不 ...
- Python代码打包成exe可执行程序
首先,打包成exe可执行程序是针对windows平台来说的. 目前比较主流的打包工具就是pyinstaller. 参考:Using PyInstaller 首先安装pyinstaller: pip i ...
- Git 使用中遇见的各种问题及解决办法
一.修改提交代码的用户名以及提交邮箱,(推荐使用方法2,一劳永逸) 方法1(修改.git/config文件): step1:进入工程.git文件夹 step2:vim config step3:末行添 ...
- 关于SM4 加密算法
国密SM4算法 与DES和AES算法相似,国密SM4算法是一种分组加密算法.SM4分组密码算法是一种迭代分组密码算法,由加解密算法和密钥扩展算法组成. SM4是一种Feistel结构的分组密码算法,其 ...
- 【转载】Vue.nextTick 的原理和用途
对于 Vue.nextTick 方法,自己有些疑惑.在查询了各种资料后,总结了一下其原理和用途,如有错误,请不吝赐教. 概览 官方文档说明: 用法: 在下次 DOM 更新循环结束之后执行延迟回调.在修 ...