MongoDB学习4:MongoDB复制集机制和原理,搭建复制集
1.复制集的作用
1.1 MongoDB复制集的主要意义在于实现服务高可用
1.2 它的实现依赖于两个方面的功能:
· 数据写入时将数据迅速复制到另一个独立节点上
· 在接收写入的节点发生故障时自动选举出一个新的替代节点
1.3 在实现高可用的同时,复制集实现了其他几个附加作用:
· 数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
· 读写分离:不同类型的压力分别在不同的节点上执行
· 异地容灾:在数据中心故障时快速切换到异地
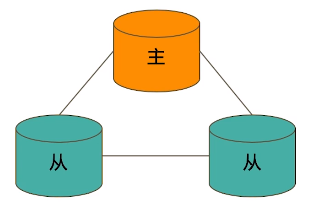
2.典型复制集结构
2.1 一个典型的复制集由3个以上具有投票权的节点组成,包括:
· 一个主节点(PRIMARY):接受写入操作和选举时投票
· 两个(或多个)从节点(SECONDARY):复制主节点上的新数据和选举时投票
· 不推荐使用Arbiter(投票节点,即不做数据存储只用来投票)
3. 数据是如何复制的?
- 当一个修改操作,无论是插入、更新或删除,到达主节点时,它对数据的操作将被记录下来(经过一些必要的转换),这些记录成为oplog
- 从节点通过在主节点上打开一个tailable游标不断获取新进入主节点的oplog,并在自己的数据上回放,以此保持与主节点数据一致

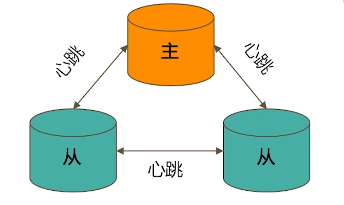
4. 通过选举完成故障恢复
- 具有投票权的节点之间两两互相发送心跳(默认2s)
- 当5次心跳未收到时判断为节点失联
- 如果失联的是主节点,从节点会发起选举,选出新的主节点
- 如果失联的是从节点则不会产生新的选举
- 选举基于 RAFT一致性算法 实现,选举成功的必要条件是大多数投票节点存活
- 复制集最多可以有50个节点,但具有投票权的节点最多7个
影响选举的因素
- 整个集群必须有大多数节点存活
- 被选举为主节点的节点必须:
- 能够与多数节点建立连接
- 具有较新的oplog
- 具有较高的优先级(如果有配置)
复制集节点具有以下常见选项
- 是否具有投票权(v 参数):有则参与投票
- 优先级(priority 参数):优先级越高的节点越优先成为主节点。优先级为0的节点无法成为主节点
- 隐藏(hidden 参数):复制数据,但对应用不可见。隐藏节点可以具有投票权,但优先级必须为0
- 延迟(slaveDelay 参数):复制n秒之前的数据,保持与主节点的时间差
复制集注意事项
- 关于硬件
- 因为正常的复制集节点都有可能成为主节点,它们的地位是一样的,因此硬件配置上必须一致
- 为了保证节点不会同时宕机,各个节点使用的硬件必须具有独立性
- 关于软件
- 复制集各节点软件版本必须一致,防止出现不可预知的问题
- 增加节点不会增加系统写性能 !
5. 在一台机器上运行3个实例来搭建一个简单的复制集
5.1 通过实验将学会:
如何启动一个MongoDB实例
如何将3个MongoDB实例搭建成一个复制集
如何对复制集运行参数做一些常规调整
5.2 创建数据目录
mkdir -p /data/db{1,2,3}
5.3 准备配置文件并启动实例
复制集的每个MongoDB进程应该位于不同的服务器。我们现在在一台机器上运行3个进程,因此要为他们各自配置:
- 不同的端口(示例将使用28017、28019、28019)
- 不同的数据目录
- /data/db1
- /data/db2
- /data/db3
- 不同的日志文件路径
- /data/db1/mongod.log
- /data/db2/mongod.log
- /data/db3/mongod.log
- 三个配置文件:
- /data/db1/mongod.conf
systemLog:
destination: file
path: /data/db1/mongod.log # log path
logAppend: true
storage:
dbPath: /data/db1 # data directory
net:
bindIp: 0.0.0.0
port: 28017
replication:
replSetName: rs0
processManagement:
fork: true
- /data/db2/mongod.conf
systemLog:
destination: file
path: /data/db2/mongod.log # log path
logAppend: true
storage:
dbPath: /data/db2 # data directory
net:
bindIp: 0.0.0.0
port: 28018
replication:
replSetName: rs0
processManagement:
fork: true
- /data/db3/mongod.conf
systemLog:
destination: file
path: /data/db3/mongod.log # log path
logAppend: true
storage:
dbPath: /data/db3 # data directory
net:
bindIp: 0.0.0.0
port: 28019
replication:
replSetName: rs0
processManagement:
fork: true
- 使用如下命令启动MongoDB实例(成功启动终端会显示success)
./mongod -f /data/db1/mongod.conf
./mongod -f /data/db2/mongod.conf
./mongod -f /data/db3/mongod.conf
- 使用
ps -ef | grep mongod来确认已经正确运行

5.4 配置复制集
- 方法1(此方式需要hostname能被解析,输入
hostname -f可以查看)
#假定使用28017做为主节点
./mongo --port 28017 # 进入mongodb的终端
> rs.initiate()
>rs.add("localhost:28018") # 如果localhost不行可改为本机ip
>rs.add("localhost:28019")
- 方法2
#假定使用28017做为主节点
./mongo --port 28017 # 进入mongodb的终端
# 如果localhost不行可改为本机ip
> rs.initiate({
_id:"rs0",
members:[{
_id:0,
host:"localhost:28017"
},{
_id:1,
host:"localhost:28018"
},{
_id:2,
host:"localhost:28019"
}]
})
- 使用
rs.status()可以查看复制集状态
5.5 验证复制集
- MongoDB主节点进行写入
# mongo localhost:28017
> db.test.insert({a:1})
> db.test.insert({a:2})
- MongoDB从节点进行读取
# mongo localhost:28018
> rs.salvaOk()
> db.test.find()
可以看到MongoDB几乎是没有延迟的,数据就可以同步到子节点上,建议在生产环境上一定要使用MongoDB的复制集
MongoDB学习4:MongoDB复制集机制和原理,搭建复制集的更多相关文章
- MongoDB学习笔记:MongoDB 数据库的命名、设计规范
MongoDB学习笔记:MongoDB 数据库的命名.设计规范 第一部分,我们先说命名规范. 文档 设计约束 UTF-8 字符 不能包含 \0 字符(空字符),这个字符标识建的结尾 . 和 $ ...
- MongoDB学习笔记——MongoDB 连接配置
MongoDB连接标准格式: mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[dat ...
- MongoDB学习笔记~MongoDB实体中的值对象
回到目录 注意,这里说的值对象是指在MongoDB实体类中的,并不是DDD中的值对象,不过,两者也是联系,就是它是对类的补充,自己本身没有存在的价值,而在值对象中,也是不需要有主键Id的,这与DDD也 ...
- MongoDB学习笔记系列
回到占占推荐博客索引 该来的总会来的,Ef,Redis,MVC甚至Sqlserver都有了自己的系列,MongoDB没有理由不去整理一下,这个系列都是平时在项目开发时总结出来的,希望可以为各位一些帮助 ...
- MongoDB学习笔记系列~目录
MongoDB学习笔记~环境搭建 (2015-03-30 10:34) MongoDB学习笔记~MongoDBRepository仓储的实现 (2015-04-08 12:00) MongoDB学习笔 ...
- MongoDB 学习笔记(原创)
MongoDB 学习笔记 mongodb 数据库 nosql 一.数据库的基本概念及操作 SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis学习(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
随机推荐
- 《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》论文总结
Aurora总结 说明:本文为论文 <Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relation ...
- ant design pro 实战 : 使用 ztree
应当指出,antd 是有 ztree 组件的,但是太简单,无法满足复杂的业务需求. 所以我还是决定使用zTree. 用 npm | cnpm 或者 yarn | tyarn 安装,这一步略. 在 js ...
- javascript : 点击按钮,把某标签中的内容复制到剪贴板
需求如题. 静态页面如下. 需要的库:jquery(不用应该也能做). 浏览器:PC chrome 68 Mobile MIUI9.5(Android 7) <p>1.用电脑打开网址:&l ...
- 题解 洛谷 P3210 【[HNOI2010]取石头游戏】
考虑到先手和后手都使用最优策略,所以可以像对抗搜索一样,设 \(val\) 为先手收益减去后手收益的值.那么先手想让 \(val\) 尽可能大,后手想让 \(val\) 尽可能小. 继续分析题目性质, ...
- 附002.Nginx全系列大总结
Nginx全系列总结如下,后期不定期更新. 欢迎基于学习.交流目的的转载和分享,禁止任何商业盗用,同时希望能带上原文出处,尊重ITer的成果,也是尊重知识. 若发现任何错误或纰漏,留言反馈或右侧添加本 ...
- 贪心法-------Saruman's army
此题的策略是选取可用范围最右边的点,一般来说该点辐射两边,左侧辐射,右侧辐射,所以用两个循环,第一个循环找出该点,第二个循环求出最右边的点 源代码: #include<iostream># ...
- lambda之美
github源码 大前提:jdk8 允许lambda表达式 最好在maven中加入 <properties> <java.version>1.8</java.vers ...
- css中使用浮动的情况和清除浮动的方法
1.使用浮动时出现的情况: (1)使块元素在一行显示 (2)使内嵌元素支持宽高 (3)不设置宽高的时候宽度由内容撑开 (4)换行不被解析(故使用行内元素的时候清除间隙的方法可以使用浮动) (5)元素添 ...
- Spring报错: org.springframework.beans.factory.CannotLoadBeanClassException: Cannot find class [xxx]
如果确实没有这个类,就挨个将总项目,子项目clean,install一下,注意他们的依赖关系.
- Python删除元组
Python删除元组: 删除元组中的某一个元素: # 删除元组中的元素 tuple_1 = ('a','b','c','d','e') # 删除第 2 个元素 tuple_1 = tuple_1[:1 ...