C/C++的二分查找
假设有一种温度传感器,已经测得它的电压和温度的对应关系,将电压值以ADC转换后的数字量的值表示,形成温度-AD值的对照表,如下。

大致成一条反比关系的曲线。
ADC的底层驱动已经写好,对外有一个接口可以实时读取该传感器的AD值。现在要求,读出AD值以后,通过二分查找,查找它对应的温度值,然后存到另一个结构体中,供后续其它模块使用。
写二分查找函数,可以这么构思。
把AD值看作X轴,温度值看作Y轴。函数有一个输入,一个输出。输入就是从底层接口获取的ad值,输出就是查到的对应的温度值。所以首先可以有两个参数,前者作为形参,接收输入;后者设定为一个指针,指向外面定义的一个存储输出的变量。其它参数有:两张表(AD和温度),还有限制查找范围的表格的大小。
因此函数头可以写成下面这个样子。前两个是const SW类型的指针,指向两张表,然后是表格的大小和输入输出。(所有基础类型定义在其它头文件里,此处SW表示signed word,是signed short类型)
B look_up_table_sw(const SW * p_XTable_SW, const SW * p_YTable_SW, UW TableSize_UW, SW ValueX_SW, SW *ValueY_SW)
函数返回的类型是“B”布尔类型,查到或者没查到。
接下来考虑函数的实现。
最开始应该做个安全检查,确保指针不是空的,表格是有的。
if (p_XTable_SW != NULL && p_YTable_SW != NULL && TableSize_UW > 0)
{
//......
}
保证这一步起码没问题后,再开始工作。
首先,看看AD值是不是超出AD表格的上下限,超出了也算找到,查到的温度值就取作温度相应的最高和最低值。
if (ValueX_SW <= p_XTable_SW[0])
{
*ValueY_SW = p_YTable_SW[0];
ret = TRUE;
}
else if (ValueX_SW >= p_XTable_SW[TableSize_UW - 1])
{
*ValueY_SW = p_YTable_SW[TableSize_UW - 1];
ret = TRUE;
}
else
{
//......
}
在else{}中继续补充代码。此时,说明AD值是在查找范围之内的,下面才是二分查找的重点。
二分查找的思想,其实可以用一种猜数字的小游戏举例。
魔术师对女孩说:“你在1-100随便想一个数字,你只要每次告诉我猜大了还是猜小了,我一定能在10次以内猜到它。”女孩想好了一个数字(假如是88),魔术师每次都猜中间的数,不是整数就向下取整。第一次猜50,女孩说小了,那么魔术师瞬间就排除掉了一半的数,前1~49都不用想了。第二次猜75,女孩说小了。第三次猜87,小了。第四次猜93,大了。第五次猜90,大了。第六次就猜到了88。
二分查找实际上是个效率很高的查找算法,但是要求表格是张有序表,适用于不会怎么变但又查找频繁的表格,就像本次要求中的,AD值和温度值有明确的一一对应的、关系简单的表格。
所以首先定义出表示猜大还是猜小的变量,和表示猜的中间数的变量。在一个循环中不断查找,每次循环开始,刷新猜的中间数。结构如下。
UW nLow = 0x00; UW nHigh = TableSize_UW - 1; UW nMid = (nHigh + nLow) / 2; while (nLow < nHigh)
{
nMid = (nHigh + nLow) / 2;
//......
}
在while{}中继续补充代码。考虑哪些情况下退出循环。
循环判断条件写的是查找下限小于上限,这是最最保底的判断了,实际上只要能确定到要找的值在哪里,也就是说,我知道它是第几个,或在第几个的边上一点点,就可以了。
比如我知道它是第三个,那么它就是Y轴数组里的Y(3),我知道它在第三个和第四个之间,那么它就在Y(3)和Y(4)之间,可以用某种方法(比如插值)算出来,这可以放到后面进行。简单来说,退出这个循环的情形就是,我知道它在哪里了。
补充如下。
if (nMid == nLow)
{
break;
}
else if (((ValueX_SW >= p_XTable_SW[nMid]) && (ValueX_SW <= p_XTable_SW[nMid + 1])) || ((ValueX_SW <= p_XTable_SW[nMid]) && (ValueX_SW >= p_XTable_SW[nMid - 1])))
{
break;
}
else if (ValueX_SW > p_XTable_SW[nMid])
{
nLow = nMid + 1;
}
else
{
nHigh = nMid - 1;
}
第一个if依然是个保底的判断,这里可以自己演算一下,nMid最次的结果就是向下取整,最后和下限是一样的值。然而一般在第二个else if中就可以跳出循环了,这一步就是确定了AD值的具体位置。然后是两个没确定位置的情况,让下限变成原来的中间数(猜小了,往上猜),或让上限变成原来的中间数(猜大了,往下猜)。每次循环都会刷新的nMid,就是每次重猜的数。代码里的nMid表示的数组里的序号。
好,到这里,我知道了AD值的具体位置,但还有有三种情况。
①它正好是我猜的数(nMid)。
②它在我猜的数右边一点。(nMid和nMid+1之间)
③它在我猜的数左边一点。(nMid和nMid-1之间)
第一种好处理,它是X轴的第nMid个,对应的当然也就是Y轴的第nMid个。
if (p_XTable_SW[nMid] == ValueX_SW)
{
*ValueY_SW = p_YTable_SW[nMid];
ret = TRUE;
}
第二种和第三种怎么处理,画个图更好理解。比如说下面的例子,a是从接口获取的AD值,通过上面的查找,确定了它在第二个和第三个值之间。现在nMid就是2,a落在nMid和nMid+1之间。当然,我想知道的温度b也落在了Y轴的nMid和nMid+1之间。
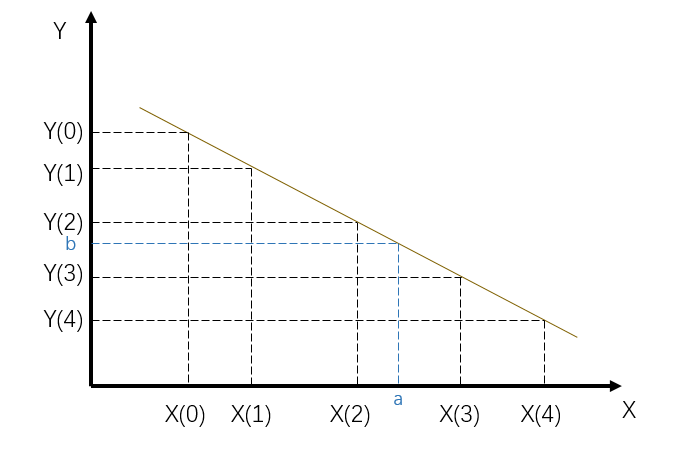
(画直线只是简单表示反比关系)
这里我采取线性插值的方式计算b是多少。所谓线性插值就是假设相邻点之间是条直线,斜率是一样的。
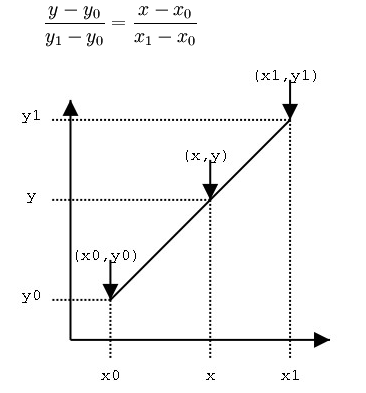
我们把局部画一下,就像这样:
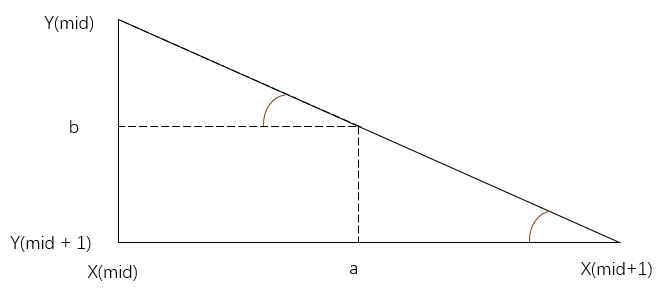
可以用斜率或正切相等的方式,也可以用相似三角形,总之原理其实一样,得到如下的关系式:
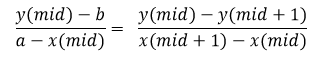
进而:
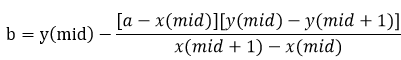
第三种情况在左边,是完全一样的,只要整体减小一格,把原来的x(mid)替换成x(mid-1),原来的x(mid+1)替换成x(mid),y(mid+1)替换成y(mid),y(mid)替换成y(mid-1)就行了。
正比关系的推导过程是一样一样的。
因此三种情况的代码如下:
if (p_XTable_SW[nMid] == ValueX_SW)
{
*ValueY_SW = p_YTable_SW[nMid];
ret = TRUE;
}
else if (ValueX_SW < p_XTable_SW[nMid])
{
*ValueY_SW = p_YTable_SW[nMid-1] - (ValueX_SW - p_XTable_SW[nMid-1]) * (p_YTable_SW[nMid-1] - p_YTable_SW[nMid]) / (p_XTable_SW[nMid] - p_XTable_SW[nMid-1]);
ret = TRUE;
}
else
{
*ValueY_SW = p_YTable_SW[nMid] - (ValueX_SW- p_XTable_SW[nMid]) * (p_YTable_SW[nMid]-p_YTable_SW[nMid + 1]) / (p_XTable_SW[nMid + 1] - p_XTable_SW[nMid]);
ret = TRUE;
}
这样,二分查找函数就写完了,最后:
return ret;
整项工作要求的完整的二分查找函数的实现,放在lookup.cpp中,如下。
#include "lookup_pub.h" B look_up_table_sw(const SW * p_XTable_SW, const SW * p_YTable_SW, UW TableSize_UW, SW ValueX_SW, SW *ValueY_SW)
{
B ret = FALSE; if (p_XTable_SW != NULL && p_YTable_SW != NULL && TableSize_UW > 0)
{
if (ValueX_SW <= p_XTable_SW[0])
{
*ValueY_SW = p_YTable_SW[0];
ret = TRUE;
}
else if (ValueX_SW >= p_XTable_SW[TableSize_UW - 1])
{
*ValueY_SW = p_YTable_SW[TableSize_UW - 1];
ret = TRUE;
}
else
{
UW nLow = 0x00; UW nHigh = TableSize_UW - 1; UW nMid = (nHigh + nLow) / 2; while (nLow < nHigh)
{
nMid = (nHigh + nLow) / 2; if (nMid == nLow)
{
break;
}
else if (((ValueX_SW >= p_XTable_SW[nMid]) && (ValueX_SW <= p_XTable_SW[nMid + 1])) || ((ValueX_SW <= p_XTable_SW[nMid]) && (ValueX_SW >= p_XTable_SW[nMid - 1])))
{
break;
}
else if (ValueX_SW > p_XTable_SW[nMid])
{
nLow = nMid + 1;
}
else
{
nHigh = nMid - 1;
}
} if (p_XTable_SW[nMid] == ValueX_SW)
{
*ValueY_SW = p_YTable_SW[nMid];
ret = TRUE;
}
else if (ValueX_SW < p_XTable_SW[nMid])
{
*ValueY_SW = p_YTable_SW[nMid-1] - (ValueX_SW - p_XTable_SW[nMid-1]) * (p_YTable_SW[nMid-1] - p_YTable_SW[nMid]) / (p_XTable_SW[nMid] - p_XTable_SW[nMid-1]);
ret = TRUE;
}
else
{
*ValueY_SW = p_YTable_SW[nMid] - (ValueX_SW- p_XTable_SW[nMid]) * (p_YTable_SW[nMid]-p_YTable_SW[nMid + 1]) / (p_XTable_SW[nMid + 1] - p_XTable_SW[nMid]);
ret = TRUE;
}
}
} return ret;
}
其它补充的源代码附在后面。
App_Typedefine.h中对基础类型作宏定义。
#ifndef _APP_TYPEDEFINE_H_
#define _APP_TYPEDEFINE_H_ // ==== basic type ====
typedef unsigned char UBYTE;
typedef signed char SBYTE;
typedef unsigned short UWORD;
typedef signed short SWORD; typedef unsigned char BOOL;
typedef unsigned char BOOLEAN; typedef float FLOAT;
typedef double DOUBLE; typedef unsigned char APP_RESULT;
#define APP_E_NOT_OK (0x01U)
#define APP_E_OK (0x00U) typedef UBYTE UB;
typedef SBYTE SB;
typedef UWORD UW;
typedef SWORD SW; typedef FLOAT F; typedef BOOL B; //typedef void VOID
#define VOID void // Definition of local function
#define LOCFUNC static // Definition of a function
#define PUBFUNC // MACRO used for BOOL type
#ifdef FALSE
#undef FALSE
#endif
#define FALSE ((BOOL)0) #ifdef TRUE
#undef TRUE
#endif
#define TRUE (!FALSE) // MACRO used for inline function, used for optimization
#ifdef CSPLUS
#define INLINE
#else
#define INLINE inline
#endif // MACRO used for const
#ifdef CONST
#undef CONST
#endif
#define CONST const // MACRO used for static variable
#define LOCVAR static // MACRO used for static functions
#define LOCFUNC static // Keep Same as MPU_NULL_PST_GUARD_LowAddress
#define NULL_PST ((void*)0xFEE00000) // Definition of NULL-pointer
#ifndef NULL
#define NULL (0)
#endif // Definition of an invalid pointer value
#define PTR_INVALID (0xFEE00000) #define NULL_POINTER(type) ((type *) PTR_INVALID) // min-max-constants for integer data types
#define UB_MAX ((UB)255)
#define UB_MIN ((UB)0) #define UBYTE_MAX ((UB)255)
#define UBYTE_MIN ((UB)0) #define SB_MAX ((SB)127)
#define SB_MIN ((SB)-128) #define SBYTE_MAX ((SB)127)
#define SBYTE_MIN ((SB)-128) #define UW_MAX ((UW)65535)
#define UW_MIN ((UW)0) #define UWORD_MAX ((UW)65535)
#define UWORD_MIN ((UW)0) #define SW_MAX ((SW)32767)
#define SW_MIN ((SW)-32768) #define SWORD_MAX ((SW)32767)
#define SWORD_MIN ((SW)-32768) #define UL_MIN ((UL)0)
#define UL_MAX ((UL)4294967295) #define ULONG_MIN ((UL)0)
#define ULONG_MAX ((UL)4294967295) #define SL_MAX ((SL)2147483647)
#define SL_MIN ((SL)-2147483648) #define SLONG_MAX ((SL)2147483647)
#define SLONG_MIN ((SL)-2147483648) #endif
lookup_pub.h对查找函数作外部声明,引用了基础类型的头文件。
#ifndef LOOKUP_PUB_H_INCLUDED
#define LOOKUP_PUB_H_INCLUDED #include "App_TypeDefine.h" extern B look_up_table_sw(const SW * pSrcTable_SW, const SW * pDestTable_SW, UW TableSize_UW, SW ValueSrc_SW, SW *ValueDest_SW); #endif
HwaAdc_pub.h中定义了用于存值、供其它模块使用的结构体,以及adc处理函数的外部声明。
#ifndef _HWA_ADC_PUB_INCLUDED_
#define _HWA_ADC_PUB_INCLUDED_ #include "App_TypeDefine.h" #define ADC_TABLE_SIZE 27 typedef struct
{
UB state_UB;
SW value_SW;
}HWA_TEMP_ADC_INFO_ST; typedef struct
{
HWA_TEMP_ADC_INFO_ST TempInCar_st;
// form ADC }IF_HWA_ADC_READ_INFO_ST; typedef struct
{
IF_HWA_ADC_READ_INFO_ST Adc_st; }IF_SRU_HWA_INFO_READ_PACKET_ST; extern const SW HWA_ADC_AD_Table_SW[ADC_TABLE_SIZE]; extern VOID hwa_adc_process(VOID); #undef EXTERN
#endif
HwaAdc.cpp定义了一个内联函数,用于把查到的温度值存到上面定义的结构体内。实现了adc处理函数,调用查找函数然后传送找到的温度值。为便于测试,所以写成下面这样,ad值自己手动输入,将传出去的结果显示出来。
其中定义的normvalue是起放大作用的,因为查找函数返回SW类型,查找后算的值也会向下取整,但是算出的有可能是个浮点数,那就体现不出小数点后面的精度了,所以先放大,再计算,最后返回的整数就能看到小数点后面几位。
#include "lookup_pub.h"
#include "HwaAdc_pub.h"
#include <iostream> //展现精度
#define normvalue 100 IF_SRU_HWA_INFO_READ_PACKET_ST hwa_t5_write_pst; const SW HWA_ADC_AD_Table_SW[ADC_TABLE_SIZE] = {
22,25,29,33,38,
45,52,61,73,86,
102,123,147,178,217,
265,326,403,502,629,
794,1010,1293,1670,
2174,2856,3787
}; const SW HWA_ADC_INDOOR_TEMP_Table_SW[ADC_TABLE_SIZE] = {
90 * normvalue,85 * normvalue,80 * normvalue,75 * normvalue,70 * normvalue,
65 * normvalue,60 * normvalue,55 * normvalue,50 * normvalue,45 * normvalue,
40 * normvalue,35 * normvalue,30 * normvalue,25 * normvalue,20 * normvalue,
15 * normvalue,10 * normvalue,5 * normvalue,0 * normvalue,-5 * normvalue,
-10 * normvalue,-15 * normvalue,-20 * normvalue,-25 * normvalue,
-30 * normvalue,-35 * normvalue,-40 * normvalue
}; INLINE VOID VDB_Set_Temp_InCar_V(SW val_sw)
{
hwa_t5_write_pst.Adc_st.TempInCar_st.value_SW = val_sw;
} VOID hwa_adc_process(VOID)
{
UW adc_value_uw;
SW adc_value_sw; //TempInCar_sw
//adc_value_uw = analog_if_query_channel(HWA_ADC_CH_INDOOR_TEMP);
std::cout << "Enter ad value input:";
while (std::cin >> adc_value_uw)
{
if (look_up_table_sw(HWA_ADC_AD_Table_SW, HWA_ADC_INDOOR_TEMP_Table_SW, ADC_TABLE_SIZE, (SW)adc_value_uw,
&adc_value_sw))
{
VDB_Set_Temp_InCar_V(adc_value_sw);
}
std::cout << "ad value from analogif is " << adc_value_uw << ",";
std::cout << "TEMP value set out is:" << hwa_t5_write_pst.Adc_st.TempInCar_st.value_SW << "\n";
std::cout << "Enter ad value input:";
} }
最后是主函数main.cpp。
#include "HwaAdc_pub.h"
#include <stdlib.h> int main()
{
hwa_adc_process(); system("pause");
}
测试结果
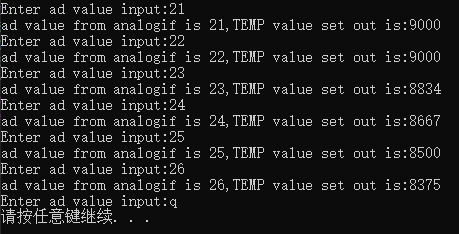
AD值刚开始输入21,超出范围, 所以温度取到90度。
输入23,24,可以看到是88.34度,86.67度。
C/C++的二分查找的更多相关文章
- jvascript 顺序查找和二分查找法
第一种:顺序查找法 中心思想:和数组中的值逐个比对! /* * 参数说明: * array:传入数组 * findVal:传入需要查找的数 */ function Orderseach(array,f ...
- Java实现的二分查找算法
二分查找又称折半查找,它是一种效率较高的查找方法. 折半查找的算法思想是将数列按有序化(递增或递减)排列,查找过程中采用跳跃式方式查找,即先以有序数列的中点位置为比较对象,如果要找的元素值小 于该中点 ...
- 从一个NOI题目再学习二分查找。
二分法的基本思路是对一个有序序列(递增递减都可以)查找时,测试一个中间下标处的值,若值比期待值小,则在更大的一侧进行查找(反之亦然),查找时再次二分.这比顺序访问要少很多访问量,效率很高. 设:low ...
- java实现二分查找
/** * 二分查找 * @param a * @param n * @param value * @return * @date 2016-10-8 * @author shaobn */ publ ...
- 最新IP地址数据库 二分逼近&二分查找 高效解析800万大数据之区域分布
最新IP地址数据库 来自 qqzeng.com 利用二分逼近法(bisection method) ,每秒300多万, 比较高效! 原来的顺序查找算法 效率比较低 readonly string i ...
- c#-二分查找-算法
折半搜索,也称二分查找算法.二分搜索,是一种在有序数组中查找某一特定元素的搜索算法. A 搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束: B 如果某一特定元素大于或者小 ...
- 【Python】二分查找算法
二分查找:在一段数字内,找到中间值,判断要找的值和中间值大小的比较.如果中间值大一些,则在中间值的左侧区域继续按照上述方式查找.如果中间值小一些,则在中间值的右侧区域继续按照上述方式查找.直到找到我们 ...
- PHP实现文本快速查找 - 二分查找
PHP实现文本快速查找 - 二分查找法 起因 先说说事情的起因,最近在分析数据时经常遇到一种场景,代码需要频繁的读某一张数据库的表,比如根据地区ID获取地区名称.根据网站分类ID获取分类名称.根据关键 ...
- java二分查找举例讨论
最近做笔试题有这么一个关于二分查找的例子. 给一个有序数组,和一个查找目标,用二分查找找出目标所在index,如果不存在,则返回-1-(其应该出现的位置),比如在0,6,9,15,18中找15,返回3 ...
- JAVA源码走读(二)二分查找与Arrays类
给数组赋值:通过fill方法. 对数组排序:通过sort方法,按升序.比较数组:通过equals方法比较数组中元素值是否相等.查找数组元素:通过binarySearch方法能对排序好的数组进行二分查找 ...
随机推荐
- unity webview
uniwebview http://uniwebview.onevcat.com/manual Unity3D研究院之在Android中打开WebView(三十) http://www.xuanyus ...
- HDU多校-1004-Vacation(思维)
Tom and Jerry are going on a vacation. They are now driving on a one-way road and several cars are i ...
- [BUUOJ记录] [极客大挑战 2019]RCE ME
前面考察取反或者异或绕过,后面读Flag那里我用脏方法过了,没看出来考察啥 进入题目给出源码: <?php error_reporting(0); if(isset($_GET['code']) ...
- [BUUOJ记录] [ACTF2020 新生赛]Upload
简单的上传题,考察绕过前端Js验证,phtml拓展名的应用 打开题目点亮小灯泡后可以看到一个上传点 传一个php测试一下: 发现有文件拓展名检查,F12发现是Js前端验证: 审查元素直接删掉,继续上传 ...
- 最小生成树MST
定义 在一给定的无向联通带权图\(G = (V, E, W)\)中,\((u, v)\) 代表连接顶点 \(u\) 与顶点 \(v\) 的边,而 \(w(u, v)\) 代表此边的权重,若存在 \(T ...
- netty如何进行单元测试
一种特殊的Channel 实现——EmbeddedChannel,它是Netty 专门为改进针对ChannelHandler 的单元测试而提供的. 将入站数据或者出站数据写入到EmbeddedChan ...
- Appium之定位元素
常用的appium元素定位工具: (1)Android SDK 中提供的元素定位工具uiautomatorviewer: (2)AppiumDesktop提供的元素定位工具Appium Inspec ...
- 痞子衡嵌入式:IAR在线调试时设不同复位类型可能会导致i.MXRT下调试现象不一致(J-Link / CMSIS-DAP)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是IAR在线调试时设不同复位类型可能会导致i.MXRT下调试现象不一致. 做Cortex-M内核MCU嵌入式软件开发,可用的集成开发环境( ...
- 整理的网上的MySQL优化文章总结
MySQL优化 Linux优化 IO优化 调整Linux默认的IO调度算法. IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调 ...
- Windows下安装Nginx及负载均衡
1.下载Windows版本的Nginx http://nginx.org/en/download.html 2.解压Nginx包,配置conf文件下的nginx.conf文件 3.配置说明: #use ...