一文带你定制unittest测试用例的名称
在之前的文章中,我在之前的文章中提到过,这里呢,考虑后,感觉之前的写法不够优雅,于是乎呢,我自己抽空去研究了下,主要是新写方法,这样呢,以后的要使用的时候,可以直接去使用,而不是每次换个环境就要修改环境中的unittest的类库。
首先呢,我们对main方法进行修改
# -*- coding: utf-8 -*- import sys
import argparse
import os
from load import defaultTestLoader from unittest import runner
from unittest.signals import installHandler __unittest = True MAIN_EXAMPLES = """\
Examples:
%(prog)s test_module - run tests from test_module
%(prog)s module.TestClass - run tests from module.TestClass
%(prog)s module.Class.test_method - run specified test method
%(prog)s path/to/test_file.py - run tests from test_file.py
""" MODULE_EXAMPLES = """\
Examples:
%(prog)s - run default set of tests
%(prog)s MyTestSuite - run suite 'MyTestSuite'
%(prog)s MyTestCase.testSomething - run MyTestCase.testSomething
%(prog)s MyTestCase - run all 'test*' test methods
in MyTestCase
""" def _convert_name(name):
# on Linux / Mac OS X 'foo.PY' is not importable, but on
# Windows it is. Simpler to do a case insensitive match
# a better check would be to check that the name is a
# valid Python module name.
if os.path.isfile(name) and name.lower().endswith('.py'):
if os.path.isabs(name):
rel_path = os.path.relpath(name, os.getcwd())
if os.path.isabs(rel_path) or rel_path.startswith(os.pardir):
return name
name = rel_path
# on Windows both '\' and '/' are used as path
# separators. Better to replace both than rely on os.path.sep
return name[:-3].replace('\\', '.').replace('/', '.')
return name def _convert_names(names):
return [_convert_name(name) for name in names] def _convert_select_pattern(pattern):
if not '*' in pattern:
pattern = '*%s*' % pattern
return pattern class TestProgram(object):
"""A command-line program that runs a set of tests; this is primarily
for making test modules conveniently executable.
"""
# defaults for testing
module=None
verbosity = 1
failfast = catchbreak = buffer = progName = warnings = testNamePatterns = None
_discovery_parser = None def __init__(self, module='__main__', defaultTest=None, argv=None,
testRunner=None, testLoader=defaultTestLoader,
exit=True, verbosity=1, failfast=None, catchbreak=None,
buffer=None, warnings=None, *, tb_locals=False):
if isinstance(module, str):
self.module = __import__(module)
for part in module.split('.')[1:]:
self.module = getattr(self.module, part)
else:
self.module = module
if argv is None:
argv = sys.argv self.exit = exit
self.failfast = failfast
self.catchbreak = catchbreak
self.verbosity = verbosity
self.buffer = buffer
self.tb_locals = tb_locals
if warnings is None and not sys.warnoptions:
# even if DeprecationWarnings are ignored by default
# print them anyway unless other warnings settings are
# specified by the warnings arg or the -W python flag
self.warnings = 'default'
else:
# here self.warnings is set either to the value passed
# to the warnings args or to None.
# If the user didn't pass a value self.warnings will
# be None. This means that the behavior is unchanged
# and depends on the values passed to -W.
self.warnings = warnings
self.defaultTest = defaultTest
self.testRunner = testRunner
self.testLoader = testLoader
self.progName = os.path.basename(argv[0])
self.parseArgs(argv)
self.runTests() def usageExit(self, msg=None):
if msg:
print(msg)
if self._discovery_parser is None:
self._initArgParsers()
self._print_help()
sys.exit(2) def _print_help(self, *args, **kwargs):
if self.module is None:
print(self._main_parser.format_help())
print(MAIN_EXAMPLES % {'prog': self.progName})
self._discovery_parser.print_help()
else:
print(self._main_parser.format_help())
print(MODULE_EXAMPLES % {'prog': self.progName}) def parseArgs(self, argv):
self._initArgParsers()
if self.module is None:
if len(argv) > 1 and argv[1].lower() == 'discover':
self._do_discovery(argv[2:])
return
self._main_parser.parse_args(argv[1:], self)
if not self.tests:
# this allows "python -m unittest -v" to still work for
# test discovery.
self._do_discovery([])
return
else:
self._main_parser.parse_args(argv[1:], self) if self.tests:
self.testNames = _convert_names(self.tests)
if __name__ == '__main__':
# to support python -m unittest ...
self.module = None
elif self.defaultTest is None:
# createTests will load tests from self.module
self.testNames = None
elif isinstance(self.defaultTest, str):
self.testNames = (self.defaultTest,)
else:
self.testNames = list(self.defaultTest)
self.createTests() def createTests(self, from_discovery=False, Loader=None):
if self.testNamePatterns:
self.testLoader.testNamePatterns = self.testNamePatterns
if from_discovery:
loader = self.testLoader if Loader is None else Loader()
self.test = loader.discover(self.start, self.pattern, self.top)
elif self.testNames is None:
self.test = self.testLoader.loadTestsFromModule(self.module)
else:
self.test = self.testLoader.loadTestsFromNames(self.testNames,
self.module) def _initArgParsers(self):
parent_parser = self._getParentArgParser()
self._main_parser = self._getMainArgParser(parent_parser)
self._discovery_parser = self._getDiscoveryArgParser(parent_parser) def _getParentArgParser(self):
parser = argparse.ArgumentParser(add_help=False) parser.add_argument('-v', '--verbose', dest='verbosity',
action='store_const', const=2,
help='Verbose output')
parser.add_argument('-q', '--quiet', dest='verbosity',
action='store_const', const=0,
help='Quiet output')
parser.add_argument('--locals', dest='tb_locals',
action='store_true',
help='Show local variables in tracebacks')
if self.failfast is None:
parser.add_argument('-f', '--failfast', dest='failfast',
action='store_true',
help='Stop on first fail or error')
self.failfast = False
if self.catchbreak is None:
parser.add_argument('-c', '--catch', dest='catchbreak',
action='store_true',
help='Catch Ctrl-C and display results so far')
self.catchbreak = False
if self.buffer is None:
parser.add_argument('-b', '--buffer', dest='buffer',
action='store_true',
help='Buffer stdout and stderr during tests')
self.buffer = False
if self.testNamePatterns is None:
parser.add_argument('-k', dest='testNamePatterns',
action='append', type=_convert_select_pattern,
help='Only run tests which match the given substring')
self.testNamePatterns = [] return parser def _getMainArgParser(self, parent):
parser = argparse.ArgumentParser(parents=[parent])
parser.prog = self.progName
parser.print_help = self._print_help parser.add_argument('tests', nargs='*',
help='a list of any number of test modules, '
'classes and test methods.') return parser def _getDiscoveryArgParser(self, parent):
parser = argparse.ArgumentParser(parents=[parent])
parser.prog = '%s discover' % self.progName
parser.epilog = ('For test discovery all test modules must be '
'importable from the top level directory of the '
'project.') parser.add_argument('-s', '--start-directory', dest='start',
help="Directory to start discovery ('.' default)")
parser.add_argument('-p', '--pattern', dest='pattern',
help="Pattern to match tests ('test*.py' default)")
parser.add_argument('-t', '--top-level-directory', dest='top',
help='Top level directory of project (defaults to '
'start directory)')
for arg in ('start', 'pattern', 'top'):
parser.add_argument(arg, nargs='?',
default=argparse.SUPPRESS,
help=argparse.SUPPRESS) return parser def _do_discovery(self, argv, Loader=None):
self.start = '.'
self.pattern = 'test*.py'
self.top = None
if argv is not None:
# handle command line args for test discovery
if self._discovery_parser is None:
# for testing
self._initArgParsers()
self._discovery_parser.parse_args(argv, self) self.createTests(from_discovery=True, Loader=Loader) def runTests(self):
if self.catchbreak:
installHandler()
if self.testRunner is None:
self.testRunner = runner.TextTestRunner
if isinstance(self.testRunner, type):
try:
try:
testRunner = self.testRunner(verbosity=self.verbosity,
failfast=self.failfast,
buffer=self.buffer,
warnings=self.warnings,
tb_locals=self.tb_locals)
except TypeError:
# didn't accept the tb_locals argument
testRunner = self.testRunner(verbosity=self.verbosity,
failfast=self.failfast,
buffer=self.buffer,
warnings=self.warnings)
except TypeError:
# didn't accept the verbosity, buffer or failfast arguments
testRunner = self.testRunner()
else:
# it is assumed to be a TestRunner instance
testRunner = self.testRunner
self.result = testRunner.run(self.test)
if self.exit:
sys.exit(not self.result.wasSuccessful()) main = TestProgram
手写这里的 只需要改动下TestProgram的里面的

即可,我们需要的config的代码其实很简单,如下
testname="leizi"
就是我们改下测试用例的名称。那么我们接下来看下我们怎么去改造 defaultTestLoader。修改后的代码如下。
"""Loading unittests.""" import os
import re
import sys
import traceback
import types
import functools
import warnings
from config import testname
from fnmatch import fnmatch, fnmatchcase
from unittest import case, suite, util __unittest = True # what about .pyc (etc)
# we would need to avoid loading the same tests multiple times
# from '.py', *and* '.pyc'
VALID_MODULE_NAME = re.compile(r'[_a-z]\w*\.py$', re.IGNORECASE) class _FailedTest(case.TestCase):
_testMethodName = None def __init__(self, method_name, exception):
self._exception = exception
super(_FailedTest, self).__init__(method_name) def __getattr__(self, name):
if name != self._testMethodName:
return super(_FailedTest, self).__getattr__(name)
def testFailure():
raise self._exception
return testFailure def _make_failed_import_test(name, suiteClass):
message = 'Failed to import test module: %s\n%s' % (
name, traceback.format_exc())
return _make_failed_test(name, ImportError(message), suiteClass, message) def _make_failed_load_tests(name, exception, suiteClass):
message = 'Failed to call load_tests:\n%s' % (traceback.format_exc(),)
return _make_failed_test(
name, exception, suiteClass, message) def _make_failed_test(methodname, exception, suiteClass, message):
test = _FailedTest(methodname, exception)
return suiteClass((test,)), message def _make_skipped_test(methodname, exception, suiteClass):
@case.skip(str(exception))
def testSkipped(self):
pass
attrs = {methodname: testSkipped}
TestClass = type("ModuleSkipped", (case.TestCase,), attrs)
return suiteClass((TestClass(methodname),)) def _jython_aware_splitext(path):
if path.lower().endswith('$py.class'):
return path[:-9]
return os.path.splitext(path)[0] class TestLoader(object):
"""
This class is responsible for loading tests according to various criteria
and returning them wrapped in a TestSuite
"""
testMethodPrefix = testname
sortTestMethodsUsing = staticmethod(util.three_way_cmp)
testNamePatterns = None
suiteClass = suite.TestSuite
_top_level_dir = None def __init__(self):
super(TestLoader, self).__init__()
self.errors = []
# Tracks packages which we have called into via load_tests, to
# avoid infinite re-entrancy.
self._loading_packages = set() def loadTestsFromTestCase(self, testCaseClass):
"""Return a suite of all test cases contained in testCaseClass"""
if issubclass(testCaseClass, suite.TestSuite):
raise TypeError("Test cases should not be derived from "
"TestSuite. Maybe you meant to derive from "
"TestCase?")
testCaseNames = self.getTestCaseNames(testCaseClass)
if not testCaseNames and hasattr(testCaseClass, 'runTest'):
testCaseNames = ['runTest']
loaded_suite = self.suiteClass(map(testCaseClass, testCaseNames))
return loaded_suite # XXX After Python 3.5, remove backward compatibility hacks for
# use_load_tests deprecation via *args and **kws. See issue 16662.
def loadTestsFromModule(self, module, *args, pattern=None, **kws):
"""Return a suite of all test cases contained in the given module"""
# This method used to take an undocumented and unofficial
# use_load_tests argument. For backward compatibility, we still
# accept the argument (which can also be the first position) but we
# ignore it and issue a deprecation warning if it's present.
if len(args) > 0 or 'use_load_tests' in kws:
warnings.warn('use_load_tests is deprecated and ignored',
DeprecationWarning)
kws.pop('use_load_tests', None)
if len(args) > 1:
# Complain about the number of arguments, but don't forget the
# required `module` argument.
complaint = len(args) + 1
raise TypeError('loadTestsFromModule() takes 1 positional argument but {} were given'.format(complaint))
if len(kws) != 0:
# Since the keyword arguments are unsorted (see PEP 468), just
# pick the alphabetically sorted first argument to complain about,
# if multiple were given. At least the error message will be
# predictable.
complaint = sorted(kws)[0]
raise TypeError("loadTestsFromModule() got an unexpected keyword argument '{}'".format(complaint))
tests = []
for name in dir(module):
obj = getattr(module, name)
if isinstance(obj, type) and issubclass(obj, case.TestCase):
tests.append(self.loadTestsFromTestCase(obj)) load_tests = getattr(module, 'load_tests', None)
tests = self.suiteClass(tests)
if load_tests is not None:
try:
return load_tests(self, tests, pattern)
except Exception as e:
error_case, error_message = _make_failed_load_tests(
module.__name__, e, self.suiteClass)
self.errors.append(error_message)
return error_case
return tests def loadTestsFromName(self, name, module=None):
"""Return a suite of all test cases given a string specifier. The name may resolve either to a module, a test case class, a
test method within a test case class, or a callable object which
returns a TestCase or TestSuite instance. The method optionally resolves the names relative to a given module.
"""
parts = name.split('.')
error_case, error_message = None, None
if module is None:
parts_copy = parts[:]
while parts_copy:
try:
module_name = '.'.join(parts_copy)
module = __import__(module_name)
break
except ImportError:
next_attribute = parts_copy.pop()
# Last error so we can give it to the user if needed.
error_case, error_message = _make_failed_import_test(
next_attribute, self.suiteClass)
if not parts_copy:
# Even the top level import failed: report that error.
self.errors.append(error_message)
return error_case
parts = parts[1:]
obj = module
for part in parts:
try:
parent, obj = obj, getattr(obj, part)
except AttributeError as e:
# We can't traverse some part of the name.
if (getattr(obj, '__path__', None) is not None
and error_case is not None):
# This is a package (no __path__ per importlib docs), and we
# encountered an error importing something. We cannot tell
# the difference between package.WrongNameTestClass and
# package.wrong_module_name so we just report the
# ImportError - it is more informative.
self.errors.append(error_message)
return error_case
else:
# Otherwise, we signal that an AttributeError has occurred.
error_case, error_message = _make_failed_test(
part, e, self.suiteClass,
'Failed to access attribute:\n%s' % (
traceback.format_exc(),))
self.errors.append(error_message)
return error_case if isinstance(obj, types.ModuleType):
return self.loadTestsFromModule(obj)
elif isinstance(obj, type) and issubclass(obj, case.TestCase):
return self.loadTestsFromTestCase(obj)
elif (isinstance(obj, types.FunctionType) and
isinstance(parent, type) and
issubclass(parent, case.TestCase)):
name = parts[-1]
inst = parent(name)
# static methods follow a different path
if not isinstance(getattr(inst, name), types.FunctionType):
return self.suiteClass([inst])
elif isinstance(obj, suite.TestSuite):
return obj
if callable(obj):
test = obj()
if isinstance(test, suite.TestSuite):
return test
elif isinstance(test, case.TestCase):
return self.suiteClass([test])
else:
raise TypeError("calling %s returned %s, not a test" %
(obj, test))
else:
raise TypeError("don't know how to make test from: %s" % obj) def loadTestsFromNames(self, names, module=None):
"""Return a suite of all test cases found using the given sequence
of string specifiers. See 'loadTestsFromName()'.
"""
suites = [self.loadTestsFromName(name, module) for name in names]
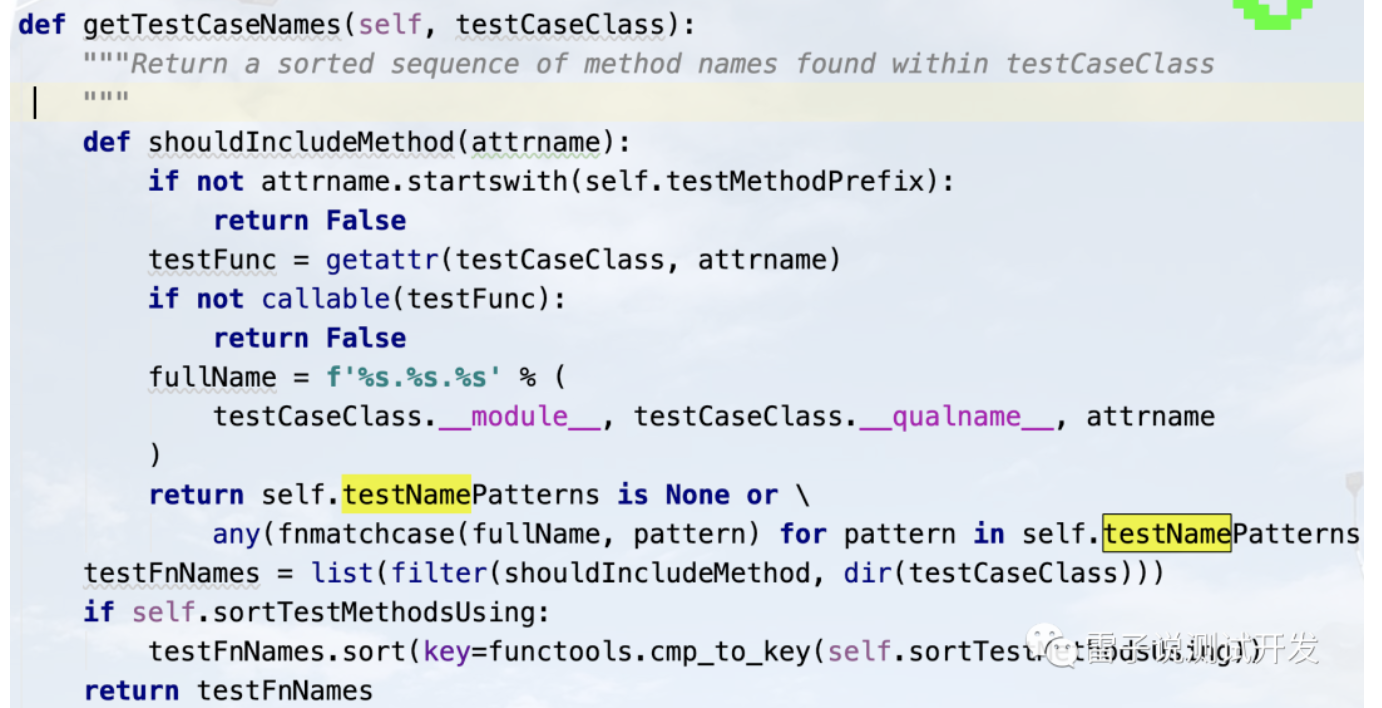
return self.suiteClass(suites) def getTestCaseNames(self, testCaseClass):
"""Return a sorted sequence of method names found within testCaseClass
"""
def shouldIncludeMethod(attrname):
if not attrname.startswith(self.testMethodPrefix):
return False
testFunc = getattr(testCaseClass, attrname)
if not callable(testFunc):
return False
fullName = f'%s.%s.%s' % (
testCaseClass.__module__, testCaseClass.__qualname__, attrname
)
return self.testNamePatterns is None or \
any(fnmatchcase(fullName, pattern) for pattern in self.testNamePatterns)
testFnNames = list(filter(shouldIncludeMethod, dir(testCaseClass)))
if self.sortTestMethodsUsing:
testFnNames.sort(key=functools.cmp_to_key(self.sortTestMethodsUsing))
return testFnNames def discover(self, start_dir, pattern='test*.py', top_level_dir=None):
"""Find and return all test modules from the specified start
directory, recursing into subdirectories to find them and return all
tests found within them. Only test files that match the pattern will
be loaded. (Using shell style pattern matching.) All test modules must be importable from the top level of the project.
If the start directory is not the top level directory then the top
level directory must be specified separately. If a test package name (directory with '__init__.py') matches the
pattern then the package will be checked for a 'load_tests' function. If
this exists then it will be called with (loader, tests, pattern) unless
the package has already had load_tests called from the same discovery
invocation, in which case the package module object is not scanned for
tests - this ensures that when a package uses discover to further
discover child tests that infinite recursion does not happen. If load_tests exists then discovery does *not* recurse into the package,
load_tests is responsible for loading all tests in the package. The pattern is deliberately not stored as a loader attribute so that
packages can continue discovery themselves. top_level_dir is stored so
load_tests does not need to pass this argument in to loader.discover(). Paths are sorted before being imported to ensure reproducible execution
order even on filesystems with non-alphabetical ordering like ext3/4.
"""
set_implicit_top = False
if top_level_dir is None and self._top_level_dir is not None:
# make top_level_dir optional if called from load_tests in a package
top_level_dir = self._top_level_dir
elif top_level_dir is None:
set_implicit_top = True
top_level_dir = start_dir top_level_dir = os.path.abspath(top_level_dir) if not top_level_dir in sys.path:
# all test modules must be importable from the top level directory
# should we *unconditionally* put the start directory in first
# in sys.path to minimise likelihood of conflicts between installed
# modules and development versions?
sys.path.insert(0, top_level_dir)
self._top_level_dir = top_level_dir is_not_importable = False
is_namespace = False
tests = []
if os.path.isdir(os.path.abspath(start_dir)):
start_dir = os.path.abspath(start_dir)
if start_dir != top_level_dir:
is_not_importable = not os.path.isfile(os.path.join(start_dir, '__init__.py'))
else:
# support for discovery from dotted module names
try:
__import__(start_dir)
except ImportError:
is_not_importable = True
else:
the_module = sys.modules[start_dir]
top_part = start_dir.split('.')[0]
try:
start_dir = os.path.abspath(
os.path.dirname((the_module.__file__)))
except AttributeError:
# look for namespace packages
try:
spec = the_module.__spec__
except AttributeError:
spec = None if spec and spec.loader is None:
if spec.submodule_search_locations is not None:
is_namespace = True for path in the_module.__path__:
if (not set_implicit_top and
not path.startswith(top_level_dir)):
continue
self._top_level_dir = \
(path.split(the_module.__name__
.replace(".", os.path.sep))[0])
tests.extend(self._find_tests(path,
pattern,
namespace=True))
elif the_module.__name__ in sys.builtin_module_names:
# builtin module
raise TypeError('Can not use builtin modules '
'as dotted module names') from None
else:
raise TypeError(
'don\'t know how to discover from {!r}'
.format(the_module)) from None if set_implicit_top:
if not is_namespace:
self._top_level_dir = \
self._get_directory_containing_module(top_part)
sys.path.remove(top_level_dir)
else:
sys.path.remove(top_level_dir) if is_not_importable:
raise ImportError('Start directory is not importable: %r' % start_dir) if not is_namespace:
tests = list(self._find_tests(start_dir, pattern))
return self.suiteClass(tests) def _get_directory_containing_module(self, module_name):
module = sys.modules[module_name]
full_path = os.path.abspath(module.__file__) if os.path.basename(full_path).lower().startswith('__init__.py'):
return os.path.dirname(os.path.dirname(full_path))
else:
# here we have been given a module rather than a package - so
# all we can do is search the *same* directory the module is in
# should an exception be raised instead
return os.path.dirname(full_path) def _get_name_from_path(self, path):
if path == self._top_level_dir:
return '.'
path = _jython_aware_splitext(os.path.normpath(path)) _relpath = os.path.relpath(path, self._top_level_dir)
assert not os.path.isabs(_relpath), "Path must be within the project"
assert not _relpath.startswith('..'), "Path must be within the project" name = _relpath.replace(os.path.sep, '.')
return name def _get_module_from_name(self, name):
__import__(name)
return sys.modules[name] def _match_path(self, path, full_path, pattern):
# override this method to use alternative matching strategy
return fnmatch(path, pattern) def _find_tests(self, start_dir, pattern, namespace=False):
"""Used by discovery. Yields test suites it loads."""
# Handle the __init__ in this package
name = self._get_name_from_path(start_dir)
# name is '.' when start_dir == top_level_dir (and top_level_dir is by
# definition not a package).
if name != '.' and name not in self._loading_packages:
# name is in self._loading_packages while we have called into
# loadTestsFromModule with name.
tests, should_recurse = self._find_test_path(
start_dir, pattern, namespace)
if tests is not None:
yield tests
if not should_recurse:
# Either an error occurred, or load_tests was used by the
# package.
return
# Handle the contents.
paths = sorted(os.listdir(start_dir))
for path in paths:
full_path = os.path.join(start_dir, path)
tests, should_recurse = self._find_test_path(
full_path, pattern, namespace)
if tests is not None:
yield tests
if should_recurse:
# we found a package that didn't use load_tests.
name = self._get_name_from_path(full_path)
self._loading_packages.add(name)
try:
yield from self._find_tests(full_path, pattern, namespace)
finally:
self._loading_packages.discard(name) def _find_test_path(self, full_path, pattern, namespace=False):
"""Used by discovery. Loads tests from a single file, or a directories' __init__.py when
passed the directory. Returns a tuple (None_or_tests_from_file, should_recurse).
"""
basename = os.path.basename(full_path)
if os.path.isfile(full_path):
if not VALID_MODULE_NAME.match(basename):
# valid Python identifiers only
return None, False
if not self._match_path(basename, full_path, pattern):
return None, False
# if the test file matches, load it
name = self._get_name_from_path(full_path)
try:
module = self._get_module_from_name(name)
except case.SkipTest as e:
return _make_skipped_test(name, e, self.suiteClass), False
except:
error_case, error_message = \
_make_failed_import_test(name, self.suiteClass)
self.errors.append(error_message)
return error_case, False
else:
mod_file = os.path.abspath(
getattr(module, '__file__', full_path))
realpath = _jython_aware_splitext(
os.path.realpath(mod_file))
fullpath_noext = _jython_aware_splitext(
os.path.realpath(full_path))
if realpath.lower() != fullpath_noext.lower():
module_dir = os.path.dirname(realpath)
mod_name = _jython_aware_splitext(
os.path.basename(full_path))
expected_dir = os.path.dirname(full_path)
msg = ("%r module incorrectly imported from %r. Expected "
"%r. Is this module globally installed?")
raise ImportError(
msg % (mod_name, module_dir, expected_dir))
return self.loadTestsFromModule(module, pattern=pattern), False
elif os.path.isdir(full_path):
if (not namespace and
not os.path.isfile(os.path.join(full_path, '__init__.py'))):
return None, False load_tests = None
tests = None
name = self._get_name_from_path(full_path)
try:
package = self._get_module_from_name(name)
except case.SkipTest as e:
return _make_skipped_test(name, e, self.suiteClass), False
except:
error_case, error_message = \
_make_failed_import_test(name, self.suiteClass)
self.errors.append(error_message)
return error_case, False
else:
load_tests = getattr(package, 'load_tests', None)
# Mark this package as being in load_tests (possibly ;))
self._loading_packages.add(name)
try:
tests = self.loadTestsFromModule(package, pattern=pattern)
if load_tests is not None:
# loadTestsFromModule(package) has loaded tests for us.
return tests, False
return tests, True
finally:
self._loading_packages.discard(name)
else:
return None, False defaultTestLoader = TestLoader() def _makeLoader(prefix, sortUsing, suiteClass=None, testNamePatterns=None):
loader = TestLoader()
loader.sortTestMethodsUsing = sortUsing
loader.testMethodPrefix = prefix
loader.testNamePatterns = testNamePatterns
if suiteClass:
loader.suiteClass = suiteClass
return loader def getTestCaseNames(testCaseClass, prefix, sortUsing=util.three_way_cmp, testNamePatterns=None):
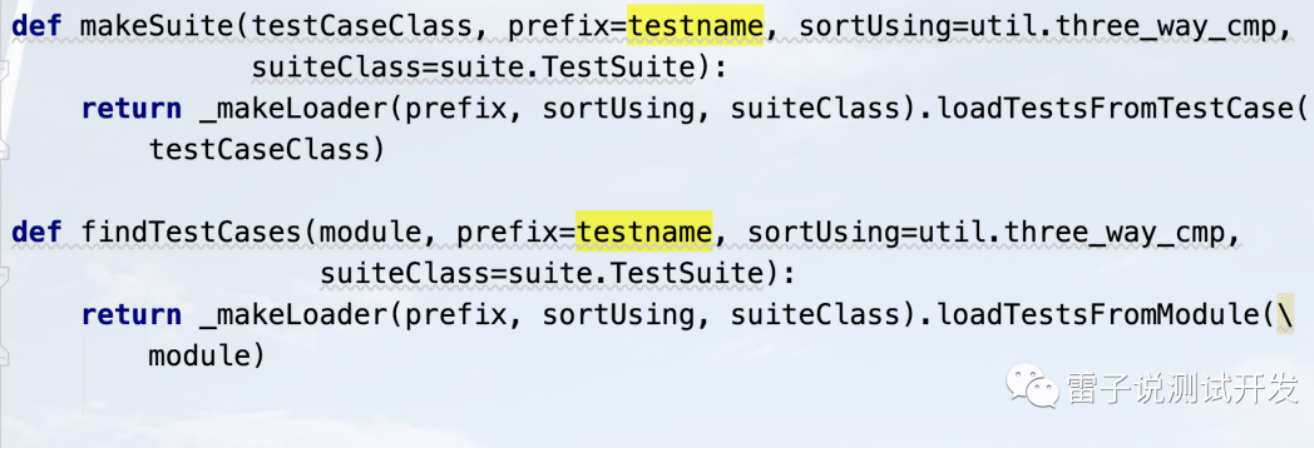
return _makeLoader(prefix, sortUsing, testNamePatterns=testNamePatterns).getTestCaseNames(testCaseClass) def makeSuite(testCaseClass, prefix=testname, sortUsing=util.three_way_cmp,
suiteClass=suite.TestSuite):
return _makeLoader(prefix, sortUsing, suiteClass).loadTestsFromTestCase(
testCaseClass) def findTestCases(module, prefix=testname, sortUsing=util.three_way_cmp,
suiteClass=suite.TestSuite):
return _makeLoader(prefix, sortUsing, suiteClass).loadTestsFromModule(\
module)
主要修改如下:
1.首先修改testMethodPrefix,我们可以看到,接下来再去加载的时候,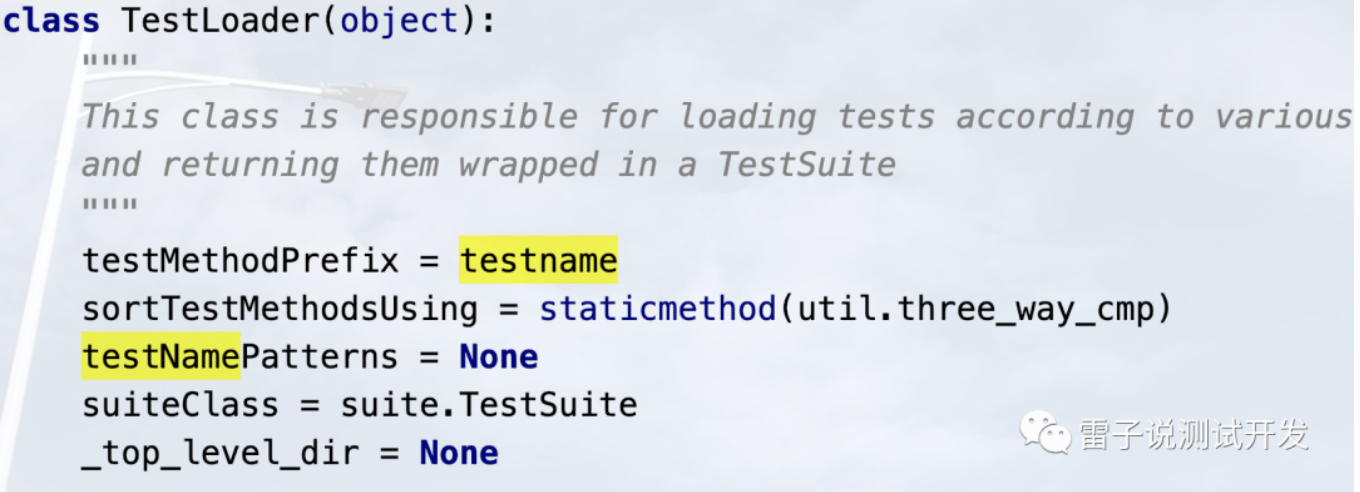
会使用到这个地方,这是是获取测试用例名称的。这里我们修改完毕后,
去加载测试用例的时候,也需要修改,修改完毕后,我们可以去写以一个方式去测试下。
我们首先去写一个测试方法,如下:
# -*- coding: utf-8 -*-
import unittest
from newmain import main class testone(unittest.TestCase):
def setUp(self) -> None: pass def leizi1(self):
print("leizitest")
self.assertTrue(True)
def tearDown(self) -> None: pass def leizi2(self):
print("leizitest")
self.assertTrue(True)
def testone(self):
print("test test")
self.assertFalse(False)
if __name__=="__main__":
main()
这里的我们的方法都是按照新定义后的方法去写的,那么我们看下执行情况。

一共执行了两个测试用例,其实我们写了三个,但是第三个由于不是leizi开通的,所以这里就没有适配,当然了,我们还可以增加一个方法,对这里的进行兼容,我们可以兼容不同命名的方法。
这篇文章其实是之前文章的升级,但是由于,之前考虑的不足,导致了代码有一定的局限性,在本次修改后,可能暂时是满足了,但是如果还需要定制的时候,我们尽量不要直接改写类库的代码,而是在代码在外面进程封装改动后使用。

一文带你定制unittest测试用例的名称的更多相关文章
- Istio是啥?一文带你彻底了解!
原标题:Istio是啥?一文带你彻底了解! " 如果你比较关注新兴技术的话,那么很可能在不同的地方听说过 Istio,并且知道它和 Service Mesh 有着牵扯. 这篇文章可以作为了解 ...
- 【转帖】Istio是啥?一文带你彻底了解!
Istio是啥?一文带你彻底了解! http://www.sohu.com/a/270131876_463994 原始位置来源: https://cizixs.com 如果你比较关注新兴技术的话,那么 ...
- JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!
序言 Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度. 本文档隶属于< ...
- unittest测试用例的执行顺序
unittest的测试顺序为:有几个测试用例,测试固件就会执行多少次. 例如:只有一个测试用例时: setup--testcase1--teardown import unittest class F ...
- 一文带您了解5G的价值与应用
一文带您了解5G的价值与应用 5G最有趣的一点是:大多数产品都是先有明确应用场景而后千呼万唤始出来.而5G则不同,即将到来的5G不仅再一次印证了科学技术是第一生产力还给不少用户带来了迷茫——我们为什么 ...
- 一文带你了解elasticsearch
一文带你了解elasticsearch cxf2102100人评论160人阅读2019-07-02 21:31:36 elasticsearch es基本概念 es术语介绍 文档Document ...
- 一文带你了解 C# DLR 的世界
一文带你了解 C# DLR 的世界 在很久之前,我写了一片文章dynamic结合匿名类型 匿名对象传参,里面我以为DLR内部是用反射实现的.因为那时候是心中想当然的认为只有反射能够在运行时解析对象的成 ...
- 一文带你看清HTTP所有概念(转)
一文带你看清HTTP所有概念 上一篇文章我们大致讲解了一下 HTTP 的基本特征和使用,大家反响很不错,那么本篇文章我们就来深究一下 HTTP 的特性.我们接着上篇文章没有说完的 HTTP 标头继 ...
- 一文带你了解js数据储存及深复制(深拷贝)与浅复制(浅拷贝)
背景 在日常开发中,偶尔会遇到需要复制对象的情况,需要进行对象的复制. 由于现在流行标题党,所以,一文带你了解js数据储存及深复制(深拷贝)与浅复制(浅拷贝) 理解 首先就需要理解 js 中的数据类型 ...
随机推荐
- Selenium学习整理(Python)
1 准备软件 Selenium IDE firebug-2.0.19.xpi firepath-0.9.7-fx.xpi Firefox_46.0.1.5966_setup.exe 由于火狐浏览器高版 ...
- windows环境下利用Gitblit搭建Git服务器并实现自动部署Web站点目录
Git服务搭建多见于linux环境,但windows主机也不少,目前网上文章诸多不全,且以讹传讹,不甚清楚.下面介绍windows环境下的自动部署和发布. 所需环境及资源:Java环境.Gitblit ...
- HDU—2021-发工资咯(水题,有点贪心的思想)
作为杭电的老师,最盼望的日子就是每月的8号了,因为这一天是发工资的日子,养家糊口就靠它了,呵呵 但是对于学校财务处的工作人员来说,这一天则是很忙碌的一天,财务处的小胡老师最近就在考虑一个问题:如果每 ...
- [BUUOJ记录] [ZJCTF 2019]NiZhuanSiWei
考察PHP伪协议+反序列化,都比较简单 进入题目给出源码: <?php $text = $_GET["text"]; $file = $_GET["file&quo ...
- [BUUOJ记录] [ACTF2020 新生赛]BackupFile、Exec
两道题都比较简单,所以放到一块记下来吧,不是水博客,师傅们轻点打 BackupFile 题目提示“Try to find out source file!”,访问备份文件/index.php.bak获 ...
- 从String中移除空白字符的多种方式!?
字符串,是Java中最常用的一个数据类型了.我们在日常开发时候会经常使用字符串做很多的操作.比如字符串的拼接.截断.替换等. 这一篇文章,我们介绍一个比较常见又容易被忽略的一个操作,那就是移除字符串中 ...
- 09. jenkins配置不同用户显示不同视图
jenkins配置不同用户显示不同视图 一.新建用户 1.1 新建用户 Manage Jenkins -> Manage Users -> 新建用户 1.2 我创建了三个用户,分别 ...
- 用Maven给一个Maven工程打包,使用阿里云镜像解决mvn clean package出错的问题,使用plugin解决没有主清单属性的问题
本来在STS里做了一个极简Maven工程,内中只有一个Main方法的Java类,然后用新装的Maven3.6.3给它打包. 结果,Maven罢工,输出如下: C:\personal\programs\ ...
- 执行Python程序出现“SyntaxError: Non-UTF-8 code starting with '\xb6'...”错误怎么办?
如果文件中有中文,直接执行python xx.py会出现以下错误: SyntaxError: Non-UTF- code starting with '\xb6' in file XX.py on l ...
- Python中自己不熟悉的知识点记录
重点笔记: Python 它是动态语言 动态语言的定义:动态编程语言 是 高级程序设计语言 的一个类别,在计算机科学领域已被广泛应用.它是一类 在 运行时可以改变其结构的语言 : ...