设计模式(二十一)——解释器模式(Spring 框架中SpelExpressionParser源码分析)
1 四则运算问题
通过解释器模式来实现四则运算,如计算 a+b-c 的值,具体要求
1) 先输入表达式的形式,比如 a+b+c-d+e, 要求表达式的字母不能重复
2) 在分别输入 a ,b, c, d, e 的值
3) 最后求出结果:如图

2 传统方案解决四则运算问题分析
1) 编写一个方法,接收表达式的形式,然后根据用户输入的数值进行解析,得到结果
2) 问题分析:如果加入新的运算符,比如 * / ( 等等,不利于扩展,另外让一个方法来解析会造成程序结构混乱, 不够清晰.
3) 解决方案:可以考虑使用解释器模式, 即: 表达式 -> 解释器(可以有多种) -> 结果
3 解释器模式基本介绍
基本介绍
1) 在编译原理中,一个算术表达式通过词法分析器形成词法单元,而后这些词法单元再通过语法分析器构建语法分析树,最终形成一颗抽象的语法分析树。这里的词法分析器和语法分析器都可以看做是解释器
2) 解释器模式(Interpreter Pattern):是指给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器, 使用该解释器来解释语言中的句子(表达式)
3) 应用场景
- 应用可以将一个需要解释执行的语言中的句子表示为一个抽象语法树
- 一些重复出现的问题可以用一种简单的语言来表达
- 一个简单语法需要解释的场景
4) 这样的例子还有,比如编译器、运算表达式计算、正则表达式、机器人等
4 解释器模式的原理类图
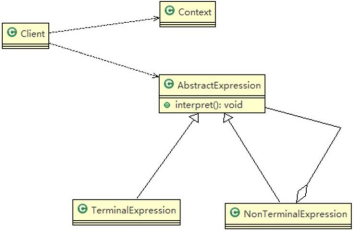
- 对原理类图的说明-即(解释器模式的角色及职责)
1) Context: 是环境角色,含有解释器之外的全局信息.
2) AbstractExpression: 抽象表达式, 声明一个抽象的解释操作,这个方法为抽象语法树中所有的节点所共享
3) TerminalExpression: 为终结符表达式, 实现与文法中的终结符相关的解释操作
4) NonTermialExpression: 为非终结符表达式,为文法中的非终结符实现解释操作.
5) 说明: 输入 Context he TerminalExpression 信息通过 Client 输入即可
5 解释器模式来实现四则
1) 应用实例要求
通过解释器模式来实现四则运算, 如计算 a+b-c 的值
2) 思路分析和图解(类图)
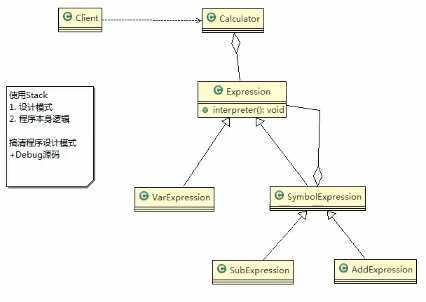
3)代码实现

package com.lin.interpret;
import java.util.HashMap;
/**
* 抽象类表达式,通过 HashMap 键值对, 可以获取到变量的值
*
* @author Administrator
*
*/
public abstract class Expression {
// a + b - c
// 解释公式和数值, key 就是公式(表达式) 参数[a,b,c], value 就是就是具体值
// HashMap {a=10, b=20}
public abstract int interpreter(HashMap<String, Integer> var);
}
package com.lin.interpret;
import java.util.HashMap;
/**
* 抽象运算符号解析器 这里,每个运算符号,都只和自己左右两个数字有关系, 但左右两个数字有可能也是一个解析的结果,无论何种类型,都是 Expression
* 类的实现类
*
* @author Administrator
*
*/
public class SymbolExpression extends Expression {
protected Expression left;
protected Expression right;
public SymbolExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
//因为 SymbolExpression 是让其子类来实现,因此 interpreter 是一个默认实现
@Override
public int interpreter(HashMap<String, Integer> var) {
return 0;
}
}
package com.lin.interpret;
import java.util.HashMap;
public class SubExpression extends SymbolExpression {
public SubExpression(Expression left, Expression right) {
super(left, right);
}
//求出 left 和 right 表达式相减后的结果
public int interpreter(HashMap<String, Integer> var) {
return super.left.interpreter(var) - super.right.interpreter(var);
}
}
package com.lin.interpret;
import java.util.HashMap;
/**
* 变量的解释器
*
* @author Administrator
*
*/
public class VarExpression extends Expression {
private String key; // key=a,key=b,key=c
public VarExpression(String key) {
this.key = key;
}
// var 就是{a=10, b=20}
// interpreter 根据 变量名称,返回对应值
@Override
public int interpreter(HashMap<String, Integer> var) {
return var.get(this.key);
}
}
package com.lin.interpret; import java.util.HashMap;
import java.util.Stack; public class Calculator { // 定义表达式
private Expression expression; // 构造函数传参,并解析 public Calculator(String expStr) { // expStr = a+b
// 安排运算先后顺序
Stack<Expression> stack = new Stack<>();
// 表达式拆分成字符数组
char[] charArray = expStr.toCharArray();// [a, +, b] Expression left = null;
Expression right = null;
// 遍历我们的字符数组, 即遍历 [a, +, b]
// 针对不同的情况,做处理
for (int i = 0; i < charArray.length; i++) {
switch (charArray[i]) {
case '+': //
left = stack.pop();// 从 stack 取 出 left => "a"
right = new VarExpression(String.valueOf(charArray[++i]));// 取出右表达式 "b"
stack.push(new AddExpression(left, right));// 然后根据得到 left 和 right 构建 AddExpresson 加入stack
break;
case '-': //
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new SubExpression(left, right));
break;
default:
// 如果是一个 Var 就创建要给 VarExpression 对象,并 push 到 stack
stack.push(new VarExpression(String.valueOf(charArray[i]))); break;
}
}
//当遍历完整个 charArray 数组后,stack 就得到最后 Expression
this.expression = stack.pop();
} public int run(HashMap<String, Integer> var) {
//最后将表达式 a+b 和 var = {a=10,b=20}
//然后传递给 expression 的 interpreter 进行解释执行
return this.expression.interpreter(var);
}
}
package com.lin.interpret;
import java.util.HashMap;
/**
* 加法解释器
*
* @author Administrator
*
*/
public class AddExpression extends SymbolExpression {
public AddExpression(Expression left, Expression right) {
super(left, right);
}
//处理相加
//var 仍然是 {a=10,b=20}..
//一会我们 debug 源码,就 ok
public int interpreter(HashMap<String, Integer> var) {
//super.left.interpreter(var) : 返回 left 表达式对应的值 a = 10
//super.right.interpreter(var): 返回 right 表达式对应值 b = 20
return super.left.interpreter(var) + super.right.interpreter(var);
}
}
package com.lin.interpret; import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap; public class Client { public static void main(String[] args) throws IOException {
String expStr = getExpStr(); // a+b
HashMap<String, Integer> var = getValue(expStr);// var {a=10, b=20} Calculator calculator = new Calculator(expStr);
System.out.println("运算结果:" + expStr + "=" + calculator.run(var));
} // 获得表达式
public static String getExpStr() throws IOException {
System.out.print("请输入表达式:");
return (new BufferedReader(new InputStreamReader(System.in))).readLine();
} // 获得值映射
public static HashMap<String, Integer> getValue(String expStr) throws IOException {
HashMap<String, Integer> map = new HashMap<>(); for (char ch : expStr.toCharArray()) {
if (ch != '+' && ch != '-') {
if (!map.containsKey(String.valueOf(ch))) {
System.out.print("请输入" + String.valueOf(ch) + "的值:");
String in = (new BufferedReader(new InputStreamReader(System.in))).readLine();
map.put(String.valueOf(ch), Integer.valueOf(in));
}
}
} return map;
} }
6 解释器模式在 Spring 框架应用的源码剖析
1) Spring 框架中 SpelExpressionParser 就使用到解释器模式
2) 代码分析
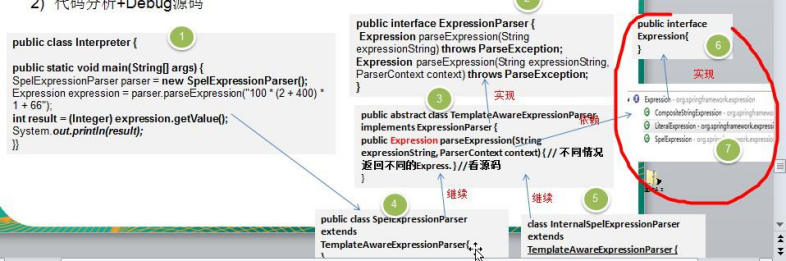
3)说明

7 解释器模式的注意事项和细节
1) 当有一个语言需要解释执行,可将该语言中的句子表示为一个抽象语法树,就可以考虑使用解释器模式,让程序具有良好的扩展性
2) 应用场景:编译器、运算表达式计算、正则表达式、机器人等
3) 使用解释器可能带来的问题:解释器模式会引起类膨胀、解释器模式采用递归调用方法,将会导致调试非常复杂、效率可能降低.
仅供参考,有错误还请指出!
有什么想法,评论区留言,互相指教指教。
觉得不错的可以点一下右边的推荐哟!
设计模式(二十一)——解释器模式(Spring 框架中SpelExpressionParser源码分析)的更多相关文章
- 设计模式(十五)——命令模式(Spring框架的JdbcTemplate源码分析)
1 智能生活项目需求 看一个具体的需求 1) 我们买了一套智能家电,有照明灯.风扇.冰箱.洗衣机,我们只要在手机上安装 app 就可以控制对这些家电工作. 2) 这些智能家电来自不同的厂家,我们不想针 ...
- Spring框架之spring-webmvc源码完全解析
Spring框架之spring-webmvc源码完全解析 Spring框架提供了构建Web应用程序的全功能MVC模块.Spring MVC分离了控制器.模型对象.分派器以及处理程序对象的角色,支持多种 ...
- Spring框架之beans源码完全解析
导读:Spring可以说是Java企业开发里最重要的技术.而Spring两大核心IOC(Inversion of Control控制反转)和AOP(Aspect Oriented Programmin ...
- Spring框架之AOP源码完全解析
Spring框架之AOP源码完全解析 Spring可以说是Java企业开发里最重要的技术.Spring两大核心IOC(Inversion of Control控制反转)和AOP(Aspect Orie ...
- Spring框架之jms源码完全解析
Spring框架之jms源码完全解析 我们在前两篇文章中介绍了Spring两大核心IOC(Inversion of Control控制反转)和AOP(Aspect Oriented Programmi ...
- Spring框架之事务源码完全解析
Spring框架之事务源码完全解析 事务的定义及特性: 事务是并发控制的单元,是用户定义的一个操作序列.这些操作要么都做,要么都不做,是一个不可分割的工作单位.通过事务将逻辑相关的一组操作绑定在一 ...
- Spring框架之jdbc源码完全解析
Spring框架之jdbc源码完全解析 Spring JDBC抽象框架所带来的价值将在以下几个方面得以体现: 1.指定数据库连接参数 2.打开数据库连接 3.声明SQL语句 4.预编译并执行SQL语句 ...
- Spring框架之websocket源码完全解析
Spring框架之websocket源码完全解析 Spring框架从4.0版开始支持WebSocket,先简单介绍WebSocket协议(详细介绍参见"WebSocket协议中文版" ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
随机推荐
- Redis 实战 —— 01. Redis 数据结构简介
一些数据库和缓存服务器的特性和功能 P4 名称 类型 数据存储选项 查询类型 附加功能 Redis 使用内存存储(in-memory)的非关系数据库 字符串.列表.哈希表.集合.有序集合 每种数据类型 ...
- ALV中的分隔条(SPLITTER_CONTROL)
如上图,可以做成左右的分割,当然也可以做成上下的分割效果,在每个分割的容器内,显示各自的内容. 需要使用的class: cl_gui_splitter_container, cl_gui_custom ...
- 24V转5V稳压芯片,高效率的同步降压DC-DC变换器3A输出电流
PW2330开发了一种高效率的同步降压DC-DC变换器3A输出电流.PW2330在4.5V到30V的宽输入电压范围内工作集成主开关和同步开关,具有非常低的RDS(ON)以最小化传导损失.PW2330采 ...
- 前端知识(二)08-Vue.js的路由-谷粒学院
目录 一.锚点的概念 二.路由的作用 三.路由实例 1.复制js资源 2.创建 路由.html 3.引入js 4.编写html 5.编写js 一.锚点的概念 案例:百度百科 特点:单页Web应用,预先 ...
- 02_Python基础
2.1 第一条编程语句 print("Hello, Python!") print("To be, or not to be, it's a question." ...
- 免安装的tomcat转服务
一:确保tomcat 在点击bin\startup 文件可以正常启动访问: 二:本机安装有JDK: 三:本机环境变量配置:JAVA_HOME:C:\Java\jdk1.7.0_17; 四:本机Tomc ...
- Go 和 Syscall
曹春晖:谈一谈 Go 和 Syscall https://juejin.im/post/6844903845475139597
- (转载)微软数据挖掘算法:Microsoft 目录篇
本系列文章主要是涉及内容为微软商业智能(BI)中一系列数据挖掘算法的总结,其中涵盖各个算法的特点.应用场景.准确性验证以及结果预测操作等,所采用的案例数据库为微软的官方数据仓库案例(Adventure ...
- ByteDance 2019 春招题目
牛客网字节跳动笔试真题:https://www.nowcoder.com/test/16516564/summary 分了 2 次做,磕磕碰碰才写完,弱鸡悲鸣. 1. 聪明的编辑 题目:Link . ...
- 某商城系统(V1.3-2020-01-10)前台命令执行漏洞
漏洞文件: ./inc/module/upload_img.php 先跟进 del_file 函数: 在 del_file 函数中首先执行了unlink操作,然后接着进行了file_exists 判断 ...