Elasticsearch第三篇:查询详解
从第一篇开始,我用的ES版本就是7.8.0的,与低版本略有不同,不同点可以参考官方介绍,最大的不同就是抛弃 type 这一概念,为了方便测试,首先建立一个学生成绩的索引库(在建立的同时,规定字段类型,并指定IK中文分词)
PUT http://localhost:9200/db_student
{
"mappings": {
"properties": {
"class": {
"type": "integer",
"store": true,
"index":true
},
"chinese": {
"type": "integer",
"store": true,
"index":true
},
"english": {
"type": "integer",
"store": true,
"index":true
},
"math": {
"type": "integer",
"store": true,
"index":true
},
"name": {
"type": "text",
"store": true,
"index":true
},
"school": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
}
}
}
}
为了方便测试,需要先插入测试数据,如下,一共插入8条记录
PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Vincent",
"school":"华南理工大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Kitty",
"school":"华南理工大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Thomas",
"school":"华南师范大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Lucy",
"school":"华南师范大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Lily",
"school":"华南农业大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Coco",
"school":"华南农业大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Allen",
"school":"中山大学"
} PUT http://localhost:/db_student/_doc/
{"chinese":,
"class":,
"english":,
"math":,
"name":"Zack",
"school":"中山大学"
}
打开 Kibana 可以看到已经插入的数据,如下
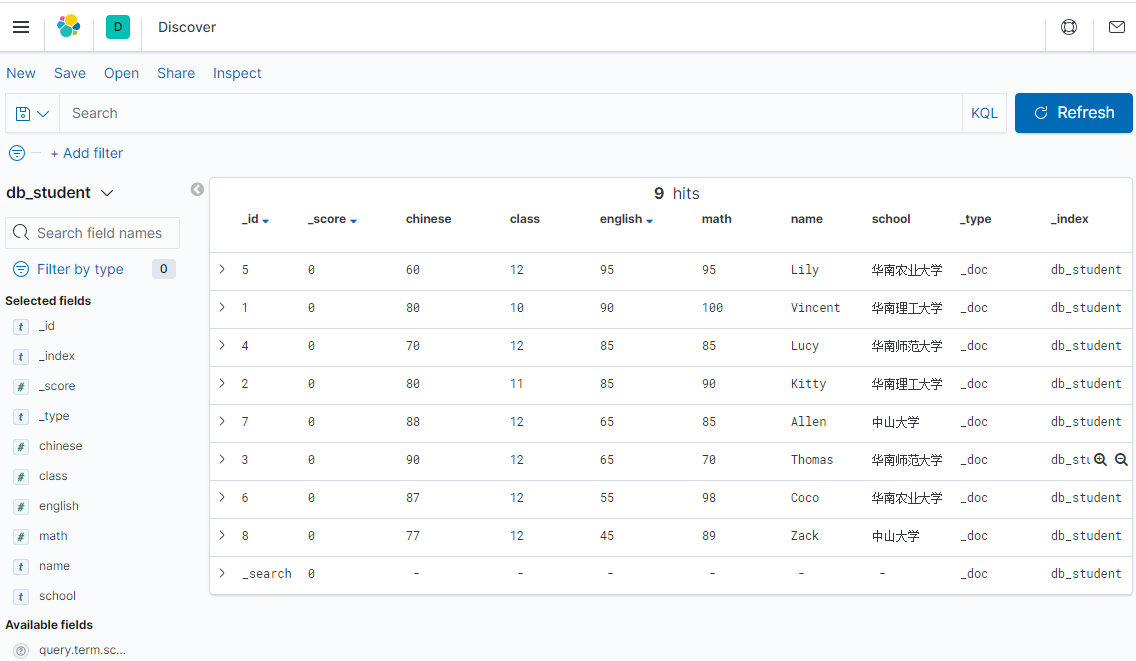
数据已经插入,现在可以来实现基本的查询了。
1、查询所有索引库、所有文档
POST http://localhost:9200/_search
{
"query": {
"match_all": {}
}
}
2、查询索引库 db_student 所有文档
POST http://localhost:9200/db_student/_search
或者是 http://localhost:9200/db_student/_doc/_search
{
"query": {
"match_all": {}
}
}
3、根据文档编号 id=1 来获取文档
GET http://localhost:/db_student/_doc/
4、查询 class=10 的学生
注意:term 在这里相当于 = 的逻辑,但是如果是字符串,还可以是包含的逻辑。
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"class":}}
]
}
}
}
5、And 逻辑查询,如查询 class=10 并且 name=vincent 的文档
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"name":"vincent"}},
{"term":{"class":}}
]
}
}
}
6、模糊查询,例如,查询 school 包含 “华南” 的文档
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"match":{"school":"华南"}}
]
}
}
}
也可以是term
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"school":"华南"}}
]
}
}
}
7、范围查询,查询 english 大于等于90,小于等于100的文档
注意:from、to 都是闭包的,包含等于
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"range":{"english":{"from":,"to":}}}
]
}
}
}
还可以查大于、小于的逻辑,例如查询 english 大于90的文档
注意:gt 表示大于, lt 表示小于 ,这两者都不包含等于
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"range":{"english":{"gt":}}}
]
}
}
}
8、高亮显示,例如 name 高亮
POST http://localhost:/db_student/_search
{
"query": {
"term":{"name":"vincent"}
},
"highlight":{
"pre_tags" : "<a class='red'>",
"post_tags" : "</a>",
"fields" : {
"name" : {}
}
}
}
查询结果是:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": {
"value": ,
"relation": "eq"
},
"max_score": .,
"hits": [
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": .,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Vincent",
"school": "华南理工大学"
},
"highlight": {
"name": [
"<a class='red'>Vincent</a>"
]
}
}
]
}
}
9、分页和排序,先按照 english 倒序,再按 math 升序,每页3条记录,取第一页
POST http://localhost:/db_student/_search
{
"query": {
"match_all":{}
},
"from": ,
"size": ,
"sort":{
"english" : {"order" : "desc"},
"math": {"order" : "asc"} }
}
查询结果是
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": {
"value": ,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Lily",
"school": "华南农业大学"
},
"sort": [
,
]
},
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Vincent",
"school": "华南理工大学"
},
"sort": [
,
]
},
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Lucy",
"school": "华南师范大学"
},
"sort": [
,
]
}
]
}
}
聚合查询、统计查询等等, 稍后补上
Elasticsearch第三篇:查询详解的更多相关文章
- ElasticSearch第四步-查询详解
ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense ElasticSearch第三步-中文分词 ElasticSea ...
- 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳
学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 JERRY_Z. ~ 2020 / 10 / 25 转载请注明出处!️ 目录 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 ...
- elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群))
一.分词器 1. 认识分词器 1.1 Analyzer 分析器 在ES中一个Analyzer 由下面三种组件组合而成: character filter :字符过滤器,对文本进行字符过滤处理,如 ...
- Mysql高手系列 - 第9篇:详解分组查询,mysql分组有大坑!
这是Mysql系列第9篇. 环境:mysql5.7.25,cmd命令中进行演示. 本篇内容 分组查询语法 聚合函数 单字段分组 多字段分组 分组前筛选数据 分组后筛选数据 where和having的区 ...
- Mysql高手系列 - 第12篇:子查询详解
这是Mysql系列第12篇. 环境:mysql5.7.25,cmd命令中进行演示. 本章节非常重要. 子查询 出现在select语句中的select语句,称为子查询或内查询. 外部的select查询语 ...
- 《手把手教你》系列技巧篇(三十一)-java+ selenium自动化测试- Actions的相关操作-番外篇(详解教程)
1.简介 上一篇中,宏哥说的宏哥在最后提到网站的反爬虫机制,那么宏哥在自己本地做一个网页,没有那个反爬虫的机制,谷歌浏览器是不是就可以验证成功了,宏哥就想验证一下自己想法,于是写了这一篇文章,另外也是 ...
- 《手把手教你》系列技巧篇(三十六)-java+ selenium自动化测试-单选和多选按钮操作-番外篇(详解教程)
1.简介 前边几篇文章是宏哥自己在本地弄了一个单选和多选的demo,然后又找了网上相关联的例子给小伙伴或童鞋们演示了一下如何自动化测试,这一篇宏哥在网上找了一个问卷调查,给小伙伴或童鞋们来演示一下.上 ...
- ThinkPHP视图查询详解
ThinkPHP视图查询详解 参考http://www.jb51.net/article/51674.htm 这篇文章主要介绍了ThinkPHP视图查询,需要的朋友可以参考下 ThinkP ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- (转)Mysql 多表查询详解
MySQL 多表查询详解 一.前言 二.示例 三.注意事项 一.前言 上篇讲到mysql中关键字执行的顺序,只涉及了一张表:实际应用大部分情况下,查询语句都会涉及到多张表格 : 1.1 多表连接有 ...
随机推荐
- 测试人员应该掌握的oracle知识体系
闲来无事,总结了一下,软件测试人员应该掌握的基本的oracle数据库知识体系 1.安装 1.1 oracle安装 1.2 oracle升级 1.3 oracle补丁 2.管理 2.1数据库创建(dbc ...
- Oracle数据库服务器更改计算机名称,导致监听服务打不开解决办法
1.修改listener.ora和tnsnames.ora文件 文件路径为:C:\Oracle\Instanclient_11_2\network\admin # listener.ora Netwo ...
- Web Scraping using Python Scrapy_BS4 - Introduction
What is Web Scraping This is also referred to as web harvesting and web data extraction. This is the ...
- day10 python之函数的参数
函数的基本属性 1.1 函数的含义 # 1.功能 :包裹代码,实现功能,达到目的 # 2.特点 :反复调用,提高开发效率,便于代码维护 1.1.2 函数的基本格式 # 函数名 :变量命名规则 # 函数 ...
- STL源码剖析:配置器
作用:对内存的管理 接口:申请和释放 内容: 几个全局函数 一级配置器 二级配置器 准备知识 POD是什么: Plain Old Data简称POD,表示传统的C语言类型:与POD类型对应的是非POD ...
- SQL语法入门
SQL语句概述 ·SQL定义:是一种特定目的编程语言,用于管理关系数据库 ·GaussDB T是一种关系数据库,SQL语句包括 1.DDL 数据定义语言,用于定义或修改数据库中的对象(表,视图,序列, ...
- lua中 string.find(查找获取字符串) string.gsub(查找替换字符串) string.sub(截取字符串)
> aaa='/p/v2/api/winapi/adapter/lgj'> print(string.find(aaa, "^/.+/adapter/(.*)"))1 ...
- Python编程语言简介
Python诞生于20世纪90年代初,由荷兰人吉多·范罗苏姆发明.那么,Python这一门编程语言是如何发明的呢?这之中又有怎么的故事呢?请看下面. 故事发生在1989年的圣诞节上,吉多先生为了打发无 ...
- 《闲扯Redis九》Redis五种数据类型之Set型
一.前言 Redis 提供了5种数据类型:String(字符串).Hash(哈希).List(列表).Set(集合).Zset(有序集合),理解每种数据类型的特点对于redis的开发和运维非常重要. ...
- 10-Pandas之数据融合(pd.merge()、df.join()、df.combine_first()详解)
一.pd.merge() pd.merge()的常用参数 参数 说明 left 参与合并的左侧DataFrame right 参与合并的右侧DataFrame how 如何合并.值为{'left',' ...