Elasticsearch第三篇:查询详解
从第一篇开始,我用的ES版本就是7.8.0的,与低版本略有不同,不同点可以参考官方介绍,最大的不同就是抛弃 type 这一概念,为了方便测试,首先建立一个学生成绩的索引库(在建立的同时,规定字段类型,并指定IK中文分词)
PUT http://localhost:9200/db_student
{
"mappings": {
"properties": {
"class": {
"type": "integer",
"store": true,
"index":true
},
"chinese": {
"type": "integer",
"store": true,
"index":true
},
"english": {
"type": "integer",
"store": true,
"index":true
},
"math": {
"type": "integer",
"store": true,
"index":true
},
"name": {
"type": "text",
"store": true,
"index":true
},
"school": {
"type": "text",
"store": true,
"index":true,
"analyzer":"ik_max_word"
}
}
}
}
为了方便测试,需要先插入测试数据,如下,一共插入8条记录
PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Vincent",
"school":"华南理工大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Kitty",
"school":"华南理工大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Thomas",
"school":"华南师范大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Lucy",
"school":"华南师范大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Lily",
"school":"华南农业大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Coco",
"school":"华南农业大学"
} PUT http://localhost:/db_student/_doc/
{
"chinese":,
"class":,
"english":,
"math":,
"name":"Allen",
"school":"中山大学"
} PUT http://localhost:/db_student/_doc/
{"chinese":,
"class":,
"english":,
"math":,
"name":"Zack",
"school":"中山大学"
}
打开 Kibana 可以看到已经插入的数据,如下
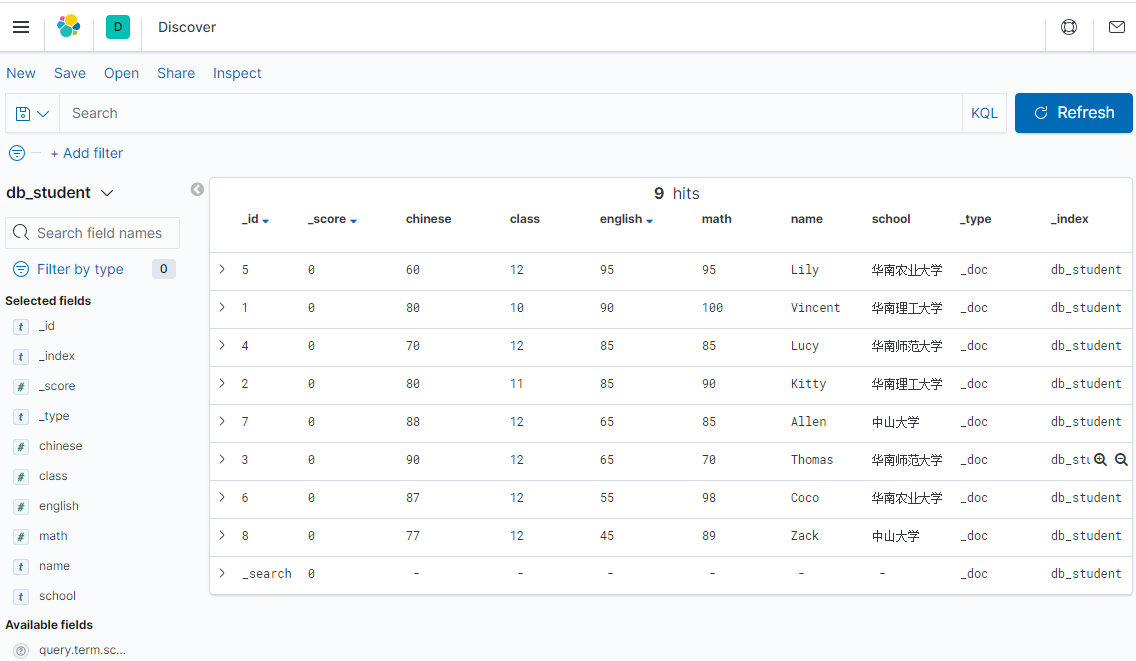
数据已经插入,现在可以来实现基本的查询了。
1、查询所有索引库、所有文档
POST http://localhost:9200/_search
{
"query": {
"match_all": {}
}
}
2、查询索引库 db_student 所有文档
POST http://localhost:9200/db_student/_search
或者是 http://localhost:9200/db_student/_doc/_search
{
"query": {
"match_all": {}
}
}
3、根据文档编号 id=1 来获取文档
GET http://localhost:/db_student/_doc/
4、查询 class=10 的学生
注意:term 在这里相当于 = 的逻辑,但是如果是字符串,还可以是包含的逻辑。
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"class":}}
]
}
}
}
5、And 逻辑查询,如查询 class=10 并且 name=vincent 的文档
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"name":"vincent"}},
{"term":{"class":}}
]
}
}
}
6、模糊查询,例如,查询 school 包含 “华南” 的文档
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"match":{"school":"华南"}}
]
}
}
}
也可以是term
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"term":{"school":"华南"}}
]
}
}
}
7、范围查询,查询 english 大于等于90,小于等于100的文档
注意:from、to 都是闭包的,包含等于
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"range":{"english":{"from":,"to":}}}
]
}
}
}
还可以查大于、小于的逻辑,例如查询 english 大于90的文档
注意:gt 表示大于, lt 表示小于 ,这两者都不包含等于
POST http://localhost:/db_student/_search
{
"query": {
"bool":{
"must":[
{"range":{"english":{"gt":}}}
]
}
}
}
8、高亮显示,例如 name 高亮
POST http://localhost:/db_student/_search
{
"query": {
"term":{"name":"vincent"}
},
"highlight":{
"pre_tags" : "<a class='red'>",
"post_tags" : "</a>",
"fields" : {
"name" : {}
}
}
}
查询结果是:
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": {
"value": ,
"relation": "eq"
},
"max_score": .,
"hits": [
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": .,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Vincent",
"school": "华南理工大学"
},
"highlight": {
"name": [
"<a class='red'>Vincent</a>"
]
}
}
]
}
}
9、分页和排序,先按照 english 倒序,再按 math 升序,每页3条记录,取第一页
POST http://localhost:/db_student/_search
{
"query": {
"match_all":{}
},
"from": ,
"size": ,
"sort":{
"english" : {"order" : "desc"},
"math": {"order" : "asc"} }
}
查询结果是
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": {
"value": ,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Lily",
"school": "华南农业大学"
},
"sort": [
,
]
},
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Vincent",
"school": "华南理工大学"
},
"sort": [
,
]
},
{
"_index": "db_student",
"_type": "_doc",
"_id": "",
"_score": null,
"_source": {
"chinese": ,
"class": ,
"english": ,
"math": ,
"name": "Lucy",
"school": "华南师范大学"
},
"sort": [
,
]
}
]
}
}
聚合查询、统计查询等等, 稍后补上
Elasticsearch第三篇:查询详解的更多相关文章
- ElasticSearch第四步-查询详解
ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense ElasticSearch第三步-中文分词 ElasticSea ...
- 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳
学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 JERRY_Z. ~ 2020 / 10 / 25 转载请注明出处!️ 目录 学会Git玩转GitHub(第三篇) 入门详解 - 精简归纳 ...
- elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群))
一.分词器 1. 认识分词器 1.1 Analyzer 分析器 在ES中一个Analyzer 由下面三种组件组合而成: character filter :字符过滤器,对文本进行字符过滤处理,如 ...
- Mysql高手系列 - 第9篇:详解分组查询,mysql分组有大坑!
这是Mysql系列第9篇. 环境:mysql5.7.25,cmd命令中进行演示. 本篇内容 分组查询语法 聚合函数 单字段分组 多字段分组 分组前筛选数据 分组后筛选数据 where和having的区 ...
- Mysql高手系列 - 第12篇:子查询详解
这是Mysql系列第12篇. 环境:mysql5.7.25,cmd命令中进行演示. 本章节非常重要. 子查询 出现在select语句中的select语句,称为子查询或内查询. 外部的select查询语 ...
- 《手把手教你》系列技巧篇(三十一)-java+ selenium自动化测试- Actions的相关操作-番外篇(详解教程)
1.简介 上一篇中,宏哥说的宏哥在最后提到网站的反爬虫机制,那么宏哥在自己本地做一个网页,没有那个反爬虫的机制,谷歌浏览器是不是就可以验证成功了,宏哥就想验证一下自己想法,于是写了这一篇文章,另外也是 ...
- 《手把手教你》系列技巧篇(三十六)-java+ selenium自动化测试-单选和多选按钮操作-番外篇(详解教程)
1.简介 前边几篇文章是宏哥自己在本地弄了一个单选和多选的demo,然后又找了网上相关联的例子给小伙伴或童鞋们演示了一下如何自动化测试,这一篇宏哥在网上找了一个问卷调查,给小伙伴或童鞋们来演示一下.上 ...
- ThinkPHP视图查询详解
ThinkPHP视图查询详解 参考http://www.jb51.net/article/51674.htm 这篇文章主要介绍了ThinkPHP视图查询,需要的朋友可以参考下 ThinkP ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- (转)Mysql 多表查询详解
MySQL 多表查询详解 一.前言 二.示例 三.注意事项 一.前言 上篇讲到mysql中关键字执行的顺序,只涉及了一张表:实际应用大部分情况下,查询语句都会涉及到多张表格 : 1.1 多表连接有 ...
随机推荐
- Iphone上对于动态生成的html元素绑定点击事件$(document).click()失效解决办法
在Iphone上,新生成的DOM元素不支持$(document).click的绑定方法,该怎么办呢? 百度了N久都没找到解决办法,在快要走投无路之时,试了试Google,我去,还真找到了,歪国人就是牛 ...
- Linux-常见的命令
1.杀掉tomcat进程 ps -ef |grep tomcat kill -9 pid 2.启动http服务 service httpd start 3.停止mysql服务 servi ...
- P1136 迎接仪式 题解
题目描述 LHX教主要来X市指导OI学习工作了.为了迎接教主,在一条道路旁,一群Orz教主er穿着文化衫站在道路两旁迎接教主,每件文化衫上都印着大字.一旁的Orzer依次摆出"欢迎欢迎欢迎欢 ...
- oracle创建Javasource实现数据库备份
因客户需求,需要在业务系统中,菜单中的网页中的按钮中加入一个按钮,用于点击备份数据库 (环境:只配置了数据源连接oralce ,应用服务器和数据服务器不在一台机器,且数据库机器oracle操作系统账号 ...
- Ubuntu安装Redis过程完整笔记
在阿里云与百度云均已经安装成功~~ 下载文件 切换路径设置下载存放地址 cd /home 下载安装包(http://download.redis.io/releases建议下载最新稳定版本) sudo ...
- Java中lambda(λ)表达式的语法
举一个排序的例子,我们传入代码来检查一个字符串是否比另一个字符串短.这里要计算: first.length() - second.length() first和second是什么?他们都是字符串.Ja ...
- 05 ES6模块化规范基础详解
ES6模块规范 1.1 ES6规范说明 历史上,JavaScript 一直没有模块(module)体系,无法将一个大程序拆分成互相依赖的小文件,再用简单的方法拼装起来.其他语言都有这项功能,比如 Ru ...
- Jmeter(十八) - 从入门到精通 - JMeter后置处理器 -下篇(详解教程)
1.简介 后置处理器是在发出“取样器请求”之后执行一些操作.取样器用来模拟用户请求,有时候服务器的响应数据在后续请求中需要用到,我们的势必要对这些响应数据进行处理,后置处理器就是来完成这项工作的.例如 ...
- MySQL组复制MGR(四)-- 单主模式与多主模式
(一)概述 组复制可以运行在单主模式下,也可以运行在多主模式下,默认为单主模式.组的不同成员不能部署在不同模式下,要切换模式,需要使用不同配置重新启动组而不是单个server. 相关参数如下: # 该 ...
- Python环境那点儿事(Windows篇)
Python环境配置那点儿事(Windows篇) 版本选择 (根据你的开发经验选择合适版) 适当版2.7 适当版3.6 适当版3.7 下载链接:python.org 安装 正规的Windows10操作 ...