java集合源码分析(三):ArrayList
概述
在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Collection 接口到 List 接口,从 AbstractCollection 抽象类到 AbstractList 的层次关系和方法实现的大体过程。
在本篇文章,将在前文的基础上,阅读 List 最常用的实现类 Arraylist 的源码,深入了解这个“熟悉的陌生人”。
一、ArrayList 的类关系
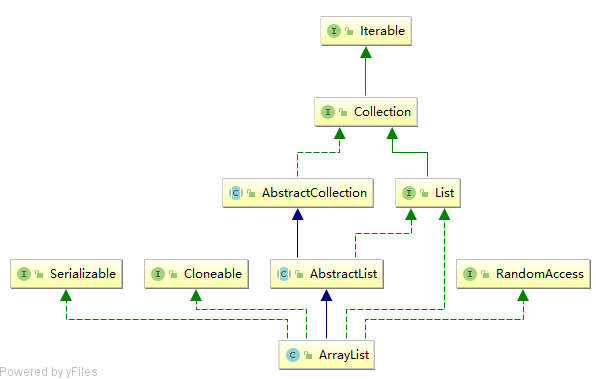
ArrayList 实现了三个接口,继承了一个抽象类,其中 Serializable ,Cloneable 与 RandomAccess 接口都是用于标记的空接口,他的主要抽象方法来自于 List,一些实现来自于 AbstractList。
1.AbstractList 与 List
ArrayList 实现了 List 接口,是 List 接口的实现类之一,他通过继承抽象类 AbstractList 获得的大部分方法的实现。
比较特别的是,理论上父类 AbstractList 已经实现类 AbstractList 接口,那么理论上 ArrayList 就已经可以通过父类获取 List 中的抽象方法了,不必再去实现 List 接口。
网上关于这个问题的答案众说纷纭,有说是为了通过共同的接口便于实现 JDK 代理,也有说是为了代码规范性与可读性的,在 Stack Overflow 上 Why does LinkedHashSet extend HashSet and implement Set 一个据说问过原作者的老哥给出了一个 it was a mistake 的回答,但是这似乎不足以解释为什么几乎所有的容器类都有类似的行为。事实到底是怎么回事,也许只有真正的原作者知道了。
2.RandomAccess
RandomAccess 是一个标记性的接口,实现了此接口的集合是允许被随机访问的。
根据 JavaDoc 的说法,如果一个类实现了此接口,那么:
for (int i=0, n=list.size(); i < n; i++)
list.get(i);
要快于
for (Iterator i=list.iterator(); i.hasNext(); )
i.next();
随机访问其实就是根据下标访问,以 LinkedList 和 ArrayList 为例,LinkedList 底层实现是链表,随机访问需要遍历链表,复杂度为 O(n),而 ArrayList 底层实现为数组,随机访问直接通过下标去寻址就行了,复杂度是O(1)。
当我们需要指定迭代的算法的时候,可以通过实现类是否实现了 RandomAccess 接口来选择对应的迭代方式。在一些方法操作集合的方法里(比如 AbstractList 中的 subList),也根据这点做了一些处理。
3.Cloneable
Cloneable 接口表示它的实现类是可以被拷贝的,根据 JavaDoc 的说法:
一个类实现Cloneable接口,以表明该通过Object.clone()方法为该类的实例进行逐域复制是合法的。
在未实现Cloneable接口的实例上调用Object的clone方法会导致抛出CloneNotSupportedException异常。
按照约定,实现此接口的类应使用公共方法重写Object.clone()。
简单的说,如果一个类想要使用Object.clone()方法以实现对象的拷贝,那么这个类需要实现 Cloneable 接口并且重写 Object.clone()方法。值得一提的是,Object.clone()默认提供的拷贝是浅拷贝,浅拷贝实际上没有拷贝并且创建一个新的实例,通过浅拷贝获得的对象变量其实还是指针,指向的还是原来那个内存地址。深拷贝的方法需要我们自己提供。
4.Serializable
Serializable 接口也是一个标记性接口,他表明实现类是可以被序列化与反序列化的。
这里提一下序列化的概念。
序列化是指把一个 Java 对象变成二进制内容的过程,本质上就是把对象转为一个 byte[] 数组,反序列化同理。
当一个 java 对象序列化以后,就可以得到的 byte[] 保存到文件中,或者把 byte[] 通过网络传输到远程,这样就相当于把 Java 对象存储到文件或者通过网络传输出去了。
值得一提的是,针对一些不希望被存储到文件,或者以字节流的形式被传输的私密信息,java 提供了 transient 关键字,被其标记的属性不会被序列化。比如在 AbstractList 里,之前提到的并发修改检查中用于记录结构性操作次数的变量 modCount,还有下面要介绍到的 ArrayList 的底层数组 elementData 就是被 transient 关键字修饰的。
更多的内容可以参考大佬的博文:Java transient关键字使用小记
二、成员变量
在 ArrayList 中,一共有七个成员变量:
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 共享的空数组实例,用于默认大小的空实例。我们将此与EMPTY_ELEMENTDATA区别开来,以了解添加第一个元素时要扩容数组到多大。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 存储ArrayList的元素的数组缓冲区。 ArrayList的容量是此数组缓冲区的长度。添加第一个元素时,任何符合
* elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的空ArrayList都将扩展为DEFAULT_CAPACITY。
*/
transient Object[] elementData;
/**
* ArrayList的大小(它包含的元素数)
*/
private int size;
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
我们来一个一个的解释他们的作用。
1.serialVersionUID
private static final long serialVersionUID = 8683452581122892189L;
用于序列化检测的 UUID,我们可以简单的理解他的作用:
当序列化以后,serialVersionUID 会被一起写入文件,当反序列化的时候,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
更多内容仍然可以参考大佬的博文:java类中serialversionuid 作用 是什么?举个例子说明
2.DEFAULT_CAPACITY
默认容量,如果实例化的时候没有在构造方法里指定初始容量大小,第一个扩容就会根据这个值扩容。
3.EMPTY_ELEMENTDATA
一个空数组,当调用构造方法的时候指定容量为0,或者其他什么操作会导致集合内数组长度变为0的时候,就会直接把空数组赋给集合实际用于存放数据的数组 elementData。
4.DEFAULTCAPACITY_EMPTY_ELEMENTDATA
也是一个空数组,不同于 EMPTY_ELEMENTDATA 是指定了容量为0的时候会被赋给elementData,而DEFAULTCAPACITY_EMPTY_ELEMENTDATA是在不指定容量的时候才会被赋给 elementData,而且添加第一个元素的时候就会被扩容。
DEFAULTCAPACITY_EMPTY_ELEMENTDATA和 EMPTY_ELEMENTDATA都不影响实际后续往里头添加元素,两者主要表示一个逻辑上的区别:前者表示集合目前为空,但是以后可能会添加元素,而后者表示这个集合一开始就没打算存任何东西,是个容量为0的空集合。
5.elementData
实际存放数据的数组,当扩容或者其他什么操作的时候,会先把数据拷贝到新数组,然后让这个变量指向新数组。
6.size
集合中的元素数量(注意不是数组长度)。
7.MAX_ARRAY_SIZE
允许的最大数组长度,之所以等于 Integer.MAX_VALUE - 8,是为了防止在一些虚拟机中数组头会被用于保持一些其他信息。
三、构造方法
ArrayList 中提供了三个构造方法:
ArrayList()ArrayList(int initialCapacity)ArrayList(Collection<? extends E> c)
// 1.构造一个空集合
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 2.构造一个具有指定初始容量的空集合
public ArrayList(int initialCapacity) {
// 判断指定的初始容量是否大于0
if (initialCapacity > 0) {
// 若大于0,则直接指定elementData数组的长度
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 若等于0,将EMPTY_ELEMENTDATA赋给elementData
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 小于0,抛异常
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
}
// 3.构造一个包含指定集合所有元素的集合
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
// 判断传入的集合是否为空集合
if ((size = elementData.length) != 0) {
// 确认转为的集合底层实现是否也是Objcet数组
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 如果是空集合,将EMPTY_ELEMENTDATA赋给elementData
this.elementData = EMPTY_ELEMENTDATA;
}
}
我们一般使用比较多的是第一种,有时候会用第三种,实际上,如果我们可以估计到实际会添加多少元素,就可以使用第二种构造器指定容量,避免扩容带来的消耗。
四、扩容缩容
ArrayList 的可扩展性是它最重要的特性之一,在开始了解其他方法前,我们需要先了解一下 ArrayList 是如何实现扩容和缩容的。
0.System.arraycopy()
在这之前,我们需要理解一下扩容缩容所依赖的核心方法 System.arraycopy()方法:
/**
* 从一个源数组复制元素到另一个数组,如果该数组指定位置已经有元素,就使用复制过来的元素替换它
*
* @param src 要复制的源数组
* @param srcPos 要从源数组哪个下标开始复制
* @param dest 要被移入元素的数组
* @param destPos 要从被移入元素数组哪个下标开始替换
* @param length 复制元素的个数
*/
arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length)
我们举个例子,假如我们现在有 arr1 = {1,2,3,4,5}和 arr2 = {6,7,8,9,10},现在我们使用 arraycopy(arr1, 0, arr2, 0, 2),则意为:
使用从 arr1 索引为 0 的元素开始,复制 2 个元素,然后把这两个元素从 arr2 数组中索引为 0 的地方开始替换原本的元素,
int[] arr1 = {1, 2, 3, 4, 5};
int[] arr2 = {6, 7, 8, 9, 10};
System.arraycopy(arr1, 0, arr2, 0, 2);
// arr2 = {1,2,8,9,10}
1.扩容
虽然在 AbstractCollection 抽象类中已经有了简单的扩容方法 finishToArray(),但是 ArrayList 没有继续使用它,而是自己重新实现了扩容的过程。ArrayList 的扩容过程一般发生在新增元素上。
我们以 add() 方法为例:
public boolean add(E e) {
// 判断新元素加入后,集合是否需要扩容
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
(1)检查是否初次扩容
我们知道,在使用构造函数构建集合的时候,如果未指定初始容量,则内部数组 elementData 会被赋上默认空数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。
因此,当我们调用 add()时,会先调用 ensureCapacityInternal()方法判断elementData 是否还是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,如果是,说明创建的时候没有指定初始容量,而且没有被扩容过,因此要保证集合被扩容到10或者更大的容量:
private void ensureCapacityInternal(int minCapacity) {
// 判断是否还是初始状态
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 扩容到默认容量(10)或更大
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
(2)检查是否需要扩容
当决定好了第一次扩容的大小,或者elementData被扩容过最少一次以后,就会进入到扩容的准备过程ensureExplicitCapacity(),在这个方法中,将会增加操作计数器modCount,并且保证新容量要比当前数组长度大:
private void ensureExplicitCapacity(int minCapacity) {
// 扩容也是结构性操作,modCount+1
modCount++;
// 判断最小所需容量是否大于当前底层数组长度
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
(3)扩容
最后进入真正的扩容方法 grow():
// 扩容
private void grow(int minCapacity) {
// 旧容量为数组当前长度
int oldCapacity = elementData.length;
// 新容量为旧容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果新容量小于最小所需容量(size + 1),就以最小所需容量作为新容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于允许的最大容量,就再判断能否再继续扩容
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 扩容完毕,将旧数组的数据拷贝到新数组上
elementData = Arrays.copyOf(elementData, newCapacity);
}
这里可能有人会有疑问,为什么oldCapacity要等于elementData.length而不可以是 size()呢?
因为在 ArrayList,既有需要彻底移除元素并新建数组的真删除,也有只是对应下标元素设置为 null 的假删除,size()实际计算的是有元素个数,因此这里需要使用elementData.length来了解数组的真实长度。
回到扩容,由于 MAX_ARRAY_SIZE已经是理论上允许的最大扩容大小了,如果新容量比MAX_ARRAY_SIZE还大,那么就涉及到一个临界扩容大小的问题,hugeCapacity()方法被用于决定最终允许的容量大小:
private static int hugeCapacity(int minCapacity) {
// 是否发生溢出
if (minCapacity < 0) // overflow
throw new OutOfMemoryError
("Required array size too large");
// 判断最终大小是MAX_ARRAY_SIZE还是Integer.MAX_VALUE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
ArrayList 的 hugeCapacity()与 AbstractCollection抽象类中的 hugeCapacity()是完全一样的,当 minCapacity > MAX_ARRAY_SIZE的情况成立的时候,说明现在的当前元素个数size容量已经等于 MAX_ARRAY_SIZE,数组已经极大了,这个时候再进行拷贝操作会非常消耗性能,因此最后一次扩容会直接扩到 Integer.MAX_VALUE,如果再大就只能溢出了。
以下是扩容的流程图:

2.缩容
除了扩容,ArrayList 还提供了缩容的方法 trimToSize(),但是这个方法不被任何其他内部方法调用,只能由程序猿自己去调用,主动让 ArrayList 瘦身,因此在日常使用中并不是很常见。
public void trimToSize() {
// 结构性操作,modCount+1
modCount++;
// 判断当前元素个数是否小于当前底层数组的长度
if (size < elementData.length) {
// 如果长度为0,就变为EMPTY_ELEMENTDATA空数组
elementData = (size == 0)
? EMPTY_ELEMENTDATA
// 否则就把容量缩小为当前的元素个数
: Arrays.copyOf(elementData, size);
}
}
3.测试
我们可以借助反射,来看看 ArrayList 的扩容和缩容过程:
先写一个通过反射获取 elementData 的方法:
// 通过反射获取值
public static void getEleSize(List<?> list) {
try {
Field ele = list.getClass().getDeclaredField("elementData");
ele.setAccessible(true);
Object[] arr = (Object[]) ele.get(list);
System.out.println("当前elementData数组的长度:" + arr.length);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
然后实验看看:
public static void main(String[] args) {
// 第一次扩容
ArrayList<String> list = new ArrayList<>();
getEleSize(list); // 当前elementData数组的长度:0
list.add("aaa");
getEleSize(list); // 当前elementData数组的长度:10
// 指定初始容量为0的集合,进行第一次扩容
ArrayList<String> emptyList = new ArrayList<>(0);
getEleSize(emptyList); // 当前elementData数组的长度:0
emptyList.add("aaa");
getEleSize(emptyList); // 当前elementData数组的长度:1
// 扩容1.5倍
for (int i = 0; i < 10; i++) {
list.add("aaa");
}
getEleSize(list); // 当前elementData数组的长度:15
// 缩容
list.trimToSize();
getEleSize(list);// 当前elementData数组的长度:11
}
五、添加 / 获取
1.add
public boolean add(E e) {
// 如果需要就先扩容
ensureCapacityInternal(size + 1);
// 添加到当前位置的下一位
elementData[size++] = e;
return true;
}
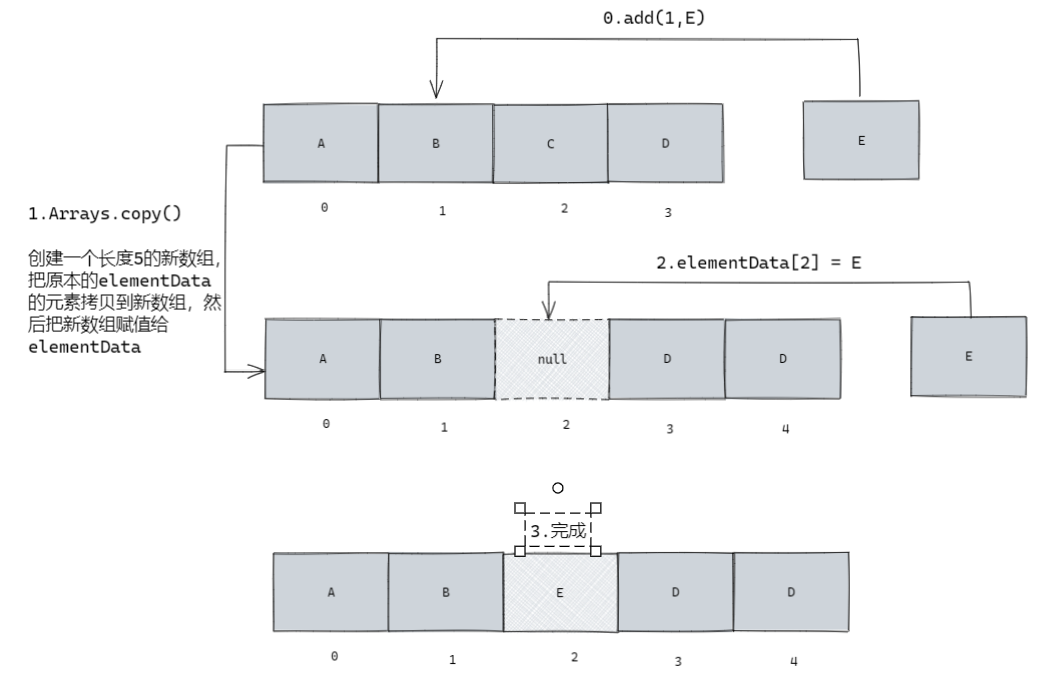
public void add(int index, E element) {
// 若 index > size || index < 0 则抛 IndexOutOfBoundsException 异常
rangeCheckForAdd(index);
// 如果需要就先扩容
ensureCapacityInternal(size + 1);
// 把原本 index 下标以后的元素集体后移一位,为新插入的数组腾位置
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
添加的原理比较简单,实际上就是如果不指定下标就插到数组尾部,否则就先创建一个新数组,然后把旧数组的数据移动到新数组,并且在这个过程中提前在新数组上留好要插入的元素的空位,最后再把元素插入数组。后面的增删操作基本都是这个原理。
2.addAll
public boolean addAll(Collection<? extends E> c) {
// 将新集合的数组取出
Object[] a = c.toArray();
int numNew = a.length;
// 如有必要就扩容
ensureCapacityInternal(size + numNew);
// 将新数组拼接到原数组的尾部
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
// 先扩容
ensureCapacityInternal(size + numNew);
// 判断是否需要移动原数组
int numMoved = size - index;
if (numMoved > 0)
// 则将原本 index 下标以后的元素移到 index + numNew 的位置
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
3.get
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
// 根据下标从数组中取值,被使用在get(),set(),remove()等方法中
E elementData(int index) {
return (E) elementData[index];
}
六、删除 / 修改
1.remove
public E remove(int index) {
// 若 index >= size 会抛出 IndexOutOfBoundsException 异常
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
// 判断是否需要移动数组
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 把元素尾部位置设置为null,便于下一次插入
elementData[--size] = null;
return oldValue;
}
public boolean remove(Object o) {
// 如果要删除的元素是null
if (o == null) {
for (int index = 0; index < size; index++)
// 移除第一位为null的元素
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 如果要删除的元素不为null
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
这里有用到一个fastRemove()方法:
// fast 的地方在于:跳过边界检查,并且不返回删除的值
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
}
比较有趣的地方在于,remove()的时候检查的是index >= size,而 add()的时候检查的是 index > size || index < 0,可见添加的时候还要看看 index 是否小于0。
原因在于 add()在校验完以后,立刻就会调用System.arraycopy(),由于这是个 native 方法,所以出错不会抛异常;而 remve() 调用完后,会先使用 elementData(index)取值,这时如果 index<0 会直接抛异常。
2.clear
比较需要注意的是,相比起remove()方法,clear()只是把数组的每一位都设置为null,elementData的长度是没有改变的:
public void clear() {
modCount++;
// 把数组每一位都设置为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
3.removeAll / retainAll
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
这两个方法都依赖于 batchRemove()方法:
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
// 遍历本集合
for (; r < size; r++)
// 如果新增集合存在与本集合存在相同的元素,有两种情况
// 1.removeAll,complement=false:直接跳过该元素
// 2.retainAll,complement=true:把新元素插入原集合头部
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// 如果上述操作中发生异常,则判断是否已经完成本集合的遍历
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
上述过程可能有点难一点理解,我们假设这是 retailAll(),因此 complement=true,执行流程是这样的:
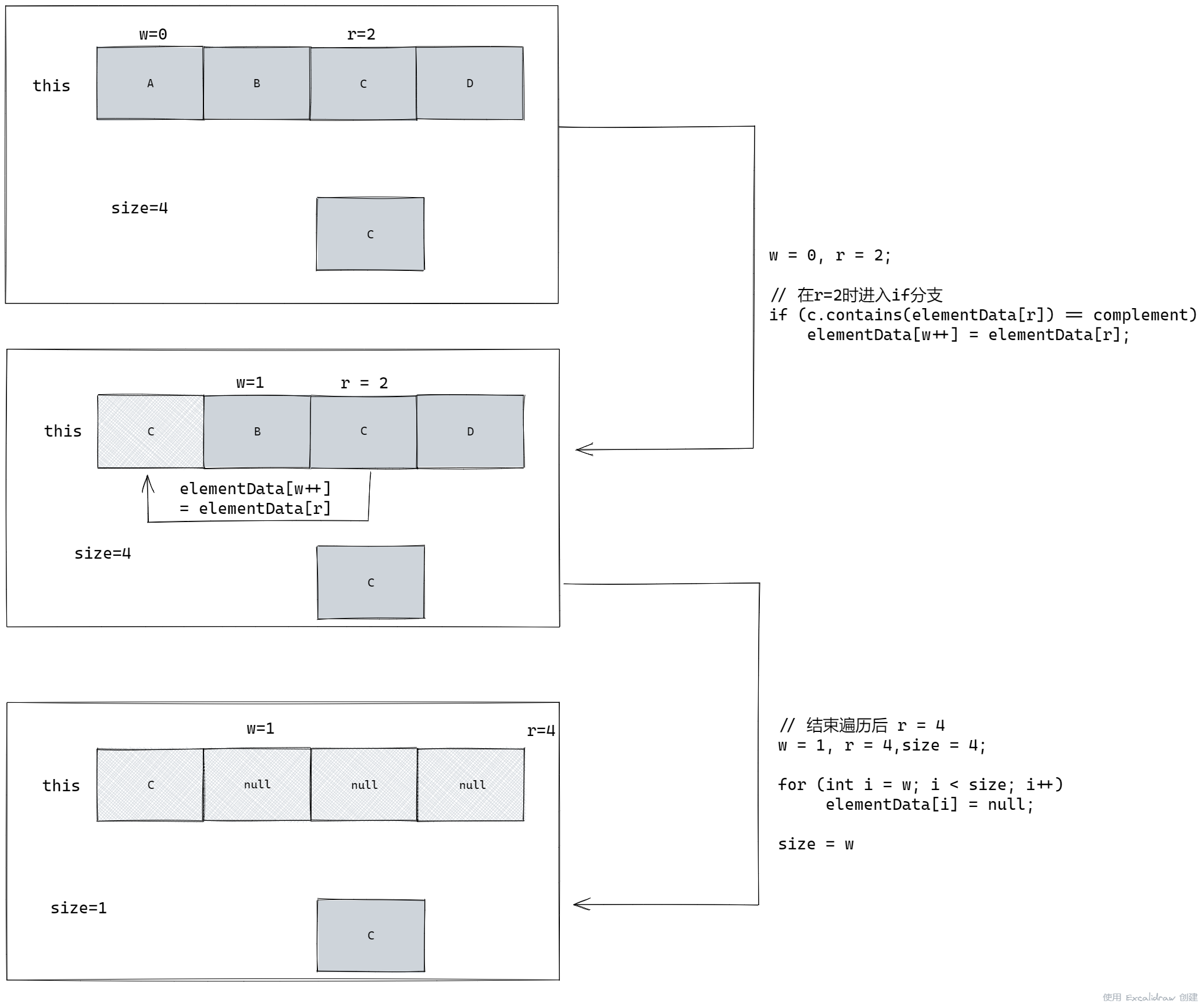
同理,如果是removeAll(),那么 w 就会始终为0,最后就会把 elementData 的所有位置都设置为 null。
4.removeIf
这个是 JDK8 以后的新增方法:
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
// 遍历集合,同时做并发修改检查
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
// 使用 lambda 表达式传入的匿名方法校验元素
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
// 并发修改检测
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// 是否有有需要删除的元素
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
// 新容量为旧容量-删除元素数量
final int newSize = size - removeCount;
// 把被删除的元素留下的空位“补齐”
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
// 将删除的位置设置为null
for (int k=newSize; k < size; k++) {
elementData[k] = null;
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
5.set
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
6.replaceAll
这也是一个 JDK8 新增的方法:
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
// 遍历,并使用lambda表达式传入的匿名函数处理每一个元素
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
七、迭代
1.iterator / listIterator
ArrayList 重新实现了自己的迭代器,而不是继续使用 AbstractList 提供的迭代器。
和 AbstracList 一样,ArrayList 实现的迭代器内部类仍然是基础迭代器 Itr 和加强的迭代器 ListItr,他和 AbstractList 中的两个同名内部类基本一样,但是针对 ArrayList 的特性对方法做了一些调整:比如一些地方取消了对内部方法的调用,直接对 elementData 下标进行操作等。
这一块可以参考上篇文章,或者看看源码,这里就不赘述了。
2.forEach
这是一个针对 Collection 的父接口 Iterable 接口中 forEach 方法的重写。在 ArrayList 的实现是这样的:
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
// 获取 modCount
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
// 遍历元素并调用lambda表达式处理元素
action.accept(elementData[i]);
}
// 遍历结束后才进行并发修改检测
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
3.迭代删除存在的问题
到目前为止,我们知道有三种迭代方式:
- 使用
iterator()或listIterator()获取迭代器; forEach();- for 循环。
如果我们在循环中删除集合的节点,只有迭代器的方式可以正常删除,其他都会出问题。
forEach
我们先试试使用 forEach():
ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D"));
arrayList1.forEach(arrayList1::remove); // java.util.ConcurrentModificationException
可见会抛出 ConcurrentModificationException异常,我们回到 forEach()的代码中:
public void forEach(Consumer<? super E> action) {
// 获取 modCount
final int expectedModCount = modCount;
... ...
for () {
// 遍历元素并调用lambda表达式处理元素
action.accept(elementData[i]);
}
... ...
// 遍历结束后才进行并发修改检测
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
由于在方法执行的开始就令 expectedModCount= modCount,等到循环处理结束后才进行 modCount != expectedModCount的判断,这样如果我们在匿名函数中对元素做了一些结构性操作,导致 modCount增加,最后就会在检测就会发现循环结束以后的 modCount 与一开始得到的 modCount不一致,所以会抛出 ConcurrentModificationException异常。
for循环
先写一个例子:
ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D"));
for (int i = 0; i < arrayList1.size(); i++) {
arrayList1.remove(i);
}
System.out.println(arrayList1); // [B, D]
可以看到,B 和 C 的删除被跳过了。实际上,这个问题和 AbstractList 的迭代器 Itr 中 remove() 方法遇到的问题有点像:
在 AbstractList 的 Itr 中,每次删除都会导致数组的“缩短”,在被删除元素的前一个元素会在 remove()后“补空”,落到被删除元素下标所对应的位置上,也就是说,假如有 a,b 两个元素,删除了下标为0的元素a以后,b就会落到下标为0的位置。
上文提到 ArrayList 的 remove() 调用了 fastRemove()方法,我们可以看看他是否就是罪魁祸首:
private void fastRemove(int index) {
... ...
// 如果不是在数组末尾删除
if (numMoved > 0)
// 数组被缩短了
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
}
所以数组“缩短”导致的元素下标变动就是问题的根源,换句话说,如果不调用 System.arraycopy()方法,理论上就不会引起这个问题,所以我们可以试试反向删除:
ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D"));
// 反向删除
for (int i = arrayList1.size() - 1; i >= 0; i--) {
arrayList1.remove(i);
}
System.out.println(arrayList1); // []
可见反向删除是没有问题的。
八、其他
1.indexOf / lastIndexOf / contains
相比起 AbstractList ,ArrayList 不再使用迭代器,而是改写成了根据下标进行for循环:
// indexOf
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// lastIndexOf
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
至于 contains() 方法,由于已经实现了 indexOf(),自然不必继续使用 AbstractCollection 提供的迭代查找了,而是改成了:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
2.subList
subList() 和 iterator()一样,也是返回一个特殊的内部类 SubList,在 AbstractList 中也已经有相同的实现,只不过在 ArrayList 里面进行了一些改进,大体逻辑和 AbstractList 中是相似的,这部分内容在前文已经有提到过,这里就不再多费笔墨。
3.sort
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
java 中集合排序要么元素类实现 Comparable 接口,要么自己写一个 Comparator 比较器。这个函数的参数指明了类型是比较器,因此只能传递自定义的比较器,在 JDK8 以后,Comparator 类提供的了一些默认实现,我们可以以类似 Comparator.reverseOrder() 的方式去调用,或者直接用 lambda 表达式传入一个匿名方法。
4.toArray
toArray() 方法在 AbstractList 的父类 AbstractCollection 中已经有过基本的实现,ArrayList 根据自己的情况重写了该方法:
public Object[] toArray() {
// 直接返回 elementData 的拷贝
return Arrays.copyOf(elementData, size);
}
public <T> T[] toArray(T[] a) {
// 如果传入的素组比本集合的元素数量少
if (a.length < size)
// 直接返回elementData的拷贝
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
// 把elementData的0到size的元素覆盖到传入数组
System.arraycopy(elementData, 0, a, 0, size);
// 如果传入数组元素比本集合的元素多
if (a.length > size)
// 让传入数组size位置变为null
a[size] = null;
return a;
}
5.clone
ArrayList 实现了 Cloneable 接口,因此他理当有自己的 clone()方法:
public Object clone() {
try {
// Object.clone()拷贝ArrayList
ArrayList<?> v = (ArrayList<?>) super.clone();
// 拷贝
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
要注意的是,通过 clone()得到的 ArrayList 不是同一个实例,但是使用 Arrays.copyOf()得到的元素对象是同一个对象。我们举个例子:
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
ArrayList<MyBean> arrayList1 = new ArrayList<>(Arrays.asList(new MyBean()));
ArrayList<MyBean> arrayList2 = (ArrayList<MyBean>) arrayList1.clone();
System.out.println(arrayList1); // [$MyBean@782830e]
System.out.println(arrayList2); // [$MyBean@782830e]
System.out.println(arrayList1 == arrayList2); // false
arrayList1.add(new MyBean());
System.out.println(arrayList1); // [MyBean@782830e, $MyBean@470e2030]
arrayList2.add(new MyBean());
System.out.println(arrayList2); // [$MyBean@782830e, $MyBean@3fb4f649]
}
public static class MyBean {}
可以看到,arrayList1 == arrayList2是 false,说明是 ArrayList 两个实例,但是内部的第一个 MyBean 都是 $MyBean@782830e,说明是同一个实例。
6.isEmpty
public boolean isEmpty() {
return size == 0;
}
九、总结
ArrayList 底层是 Object[] 数组,被 RandomAccess 接口标记,具有根据下标高速随机访问的功能;
ArrayList 扩容是扩大1.5倍,只有构造方法指定初始容量为0时,才会在第一次扩容出现小于10的容量,否则第一次扩容后的容量必然大于等于10;
ArrayList 有缩容方法trimToSize(),但是自身不会主动调用。当调用后,容量会缩回实际元素数量,最小会缩容至默认容量10;
ArrayList 的添加可能会因为扩容导致数组“膨胀”,同理,不是所有的删除都会引起数组“缩水”:当删除的元素是队尾元素,或者clear()方法都只会把下标对应的地方设置为null,而不会真正的删除数组这个位置;
ArrayList 在循环中删除——准确的讲,是任何会引起 modCount变化的结构性操作——可能会引起意外:
在
forEach()删除元素会抛ConcurrentModificationException异常,因为forEach()在循环开始前就获取了modCount,但是到循环结束才比较旧modCount和最新的modeCount;在 for 循环里删除实际上是以步长为2对节点进行删除,因为删除时数组“缩水”导致原本要删除的下一下标对应的节点,却落到了当前被删除的节点对应的下标位置,导致被跳过。
如果从队尾反向删除,就不会引起数组“缩水”,因此是正常的。
java集合源码分析(三):ArrayList的更多相关文章
- Java集合源码分析之ArrayList
ArrayList简介 从上图可以看到,ArrayList是集合框架中List接口的一个实现类,它继承了AbstractList类,实现了List, RandomAccess, Cloneable, ...
- Java集合源码分析之ArrayList(JDK1.8)
package annoction; import java.util.*; import java.util.function.Consumer; import java.util.function ...
- Java集合源码分析(二)ArrayList
ArrayList简介 ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存. ArrayList不是线程安全的,只能用在单线程环境下,多线 ...
- java集合源码分析(六):HashMap
概述 HashMap 是 Map 接口下一个线程不安全的,基于哈希表的实现类.由于他解决哈希冲突的方式是分离链表法,也就是拉链法,因此他的数据结构是数组+链表,在 JDK8 以后,当哈希冲突严重时,H ...
- Java 集合源码分析(一)HashMap
目录 Java 集合源码分析(一)HashMap 1. 概要 2. JDK 7 的 HashMap 3. JDK 1.8 的 HashMap 4. Hashtable 5. JDK 1.7 的 Con ...
- Java集合源码分析(三)LinkedList
LinkedList简介 LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈.队列和双端队列来使用. LinkedList同样是非线程安全 ...
- Java集合源码分析(四)Vector<E>
Vector<E>简介 Vector也是基于数组实现的,是一个动态数组,其容量能自动增长. Vector是JDK1.0引入了,它的很多实现方法都加入了同步语句,因此是线程安全的(其实也只是 ...
- 集合源码分析[3]-ArrayList 源码分析
历史文章: Collection 源码分析 AbstractList 源码分析 介绍 ArrayList是一个数组队列,相当于动态数组,与Java的数组对比,他的容量可以动态改变. 继承关系 Arra ...
- java集合源码分析几篇文章
java集合源码解析https://blog.csdn.net/ns_code/article/category/2362915
随机推荐
- 打印Sql查询语句
如果在使用了yii的查询语句的话,可以打印本次的Sql,可以用 $model->find()->createCommand()->getRawSql();此语句返回的就是sql查询语 ...
- P1526 [NOI2003]智破连环阵
目录 题意描述 算法分析 闲话 初步分析 具体思路 剪枝一 剪枝二 剪枝三 总结一下 代码实现 预处理 剪枝一 剪枝二 剪枝三 二分图匹配 代码综合 结语 又是被楼教主虐的体无完肤的一天 题意描述 在 ...
- linux修改ssh远程端口22
建议先查看redhat的release版本,CentOS 7的启动服务不同: # more /etc/redhat-release 正文: 如题: 在此前,建议先查看redhat的release版本, ...
- NOIP 2012 P1081 开车旅行
倍增 这道题最难的应该是预处理... 首先用$set$从后往前预处理出每一个点海拔差绝对值得最大值和次大值 因为当前城市的下标只能变大,对于点$i$,在$set$中二分找出与其值最接近的下标 然后再$ ...
- 双十一,就用turtle画个单身狗送给自己
今年的双十一到了 但还有谁记得双十一是 单身狗的节日 单身狗的我是时候站出来 捍卫自己的权益了 单身是一种怎样的状态? 我们所有人都单身过,但也许只有很少的人真正体验过. 短视频内容完全是假的,全程是 ...
- 【linux】helloword原理分析及实战
目录 前言 linux中hello word原理 hello word 实战 学习参考 前言 hello word 著名演示程序,哈哈 下面在 arm linux 下展示一下hello world,便 ...
- Socket connect 等简要分析
connect 系统调用 分析 #include <sys/types.h> /* See NOTES */#include <sys/socket.h>int connect ...
- 1、线性DP 198. 打家劫舍
198. 打家劫舍 https://leetcode-cn.com/problems/house-robber/ //dp动态规划,dp[i] 状态表示0-i家的盗的得最大值.那么dp[i] = (d ...
- 限流10万QPS、跨域、过滤器、令牌桶算法-网关Gateway内容都在这儿
一.微服务网关Spring Cloud Gateway 1.1 导引 文中内容包含:微服务网关限流10万QPS.跨域.过滤器.令牌桶算法. 在构建微服务系统中,必不可少的技术就是网关了,从早期的Zuu ...
- 关于CTFshow中Web入门42-54
0x00前记 终于把学校上学期的期末考试考完了,刚好复习的时候跟着群里的师傅写了ctfshow上Web入门的42-54的题目,其中有很多的坑,但是收获也是很多的,这里做一下总结吧!给自己挖了很多的 ...