全文检索django-haystack+jieba+whoosh
全文检索里的组件简介
1、什么是haystack?
1. haystack是django的开源搜索框架,该框架支持Solr,Elasticsearch,Whoosh, *Xapian*搜索引擎,不用更改代码,直接切换引擎,减少代码量。
2. 搜索引擎使用Whoosh,这是一个由纯Python实现的全文搜索引擎,没有二进制文件等,比较小巧,配置比较简单,当然性能自然略低。
3. 中文分词Jieba,由于Whoosh自带的是英文分词,对中文的分词支持不是太好,故用jieba替换whoosh的分词组件。
2、什么是jieba?
1、很多的搜索引擎对中的支持不友好,jieba作为一个中文分词器就是加强对中文的检索功能
3、Whoosh是什么?
1、Python的全文搜索库,Whoosh是索引文本及搜索文本的类和函数库
2、Whoosh 自带的是英文分词,对中文分词支持不太好,使用 jieba 替换 whoosh 的分词组件。
haystack配置使用(前后端分离)
安装工具
pip install django-haystack
pip install whoosh
pip install jieba
在setting.py中配置
'''注册app '''
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# haystack要放在应用的上面
'haystack',
'jsapp', # 这个jsapp是自己创建的app
] ''' 模板路径 '''
TEMPLATES = [
{
'DIRS': [os.path.join(BASE_DIR,'templates')], },
] '''配置haystack '''
# 全文检索框架配置
HAYSTACK_CONNECTIONS = {
'default': {
# 指定whoosh引擎
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 'ENGINE': 'jsapp.whoosh_cn_backend.WhooshEngine', # whoosh_cn_backend是haystack的whoosh_backend.py改名的文件为了使用jieba分词
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 添加此项,当数据库改变时,会自动更新索引,非常方便
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
setting.py
定义数据库
from django.db import models # Create your models here.
class UserInfo(models.Model):
name = models.CharField(max_length=254)
age = models.IntegerField() class ArticlePost(models.Model):
author = models.ForeignKey(UserInfo,on_delete=models.CASCADE)
title = models.CharField(max_length=200)
desc = models.SlugField(max_length=500)
body = models.TextField()
jsapp/models.py
索引文件生成
1)在子应用下创建索引文件
在子应用的目录下,创建一个名为 jsapp/search_indexes.py 的文件
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from haystack import indexes
from .models import ArticlePost # 修改此处,类名为模型类的名称+Index,比如模型类为GoodsInfo,则这里类名为GoodsInfoIndex(其实可以随便写)
class ArticlePostIndex(indexes.SearchIndex, indexes.Indexable):
# text为索引字段
# document = True,这代表haystack和搜索引擎将使用此字段的内容作为索引进行检索
# use_template=True 指定根据表中的那些字段建立索引文件的说明放在一个文件中
text = indexes.CharField(document=True, use_template=True) # 对那张表进行查询
def get_model(self): # 重载get_model方法,必须要有!
# 返回这个model
return ArticlePost # 建立索引的数据
def index_queryset(self, using=None):
# 这个方法返回什么内容,最终就会对那些方法建立索引,这里是对所有字段建立索引
return self.get_model().objects.all()
jsapp/search_indexes.py
2)指定索引模板文件
# 创建文件路径命名必须这个规范:templates/search/indexes/应用名称/模型类名称_text.txt
# templates/search/indexes/jsapp/articlepost_text.txt
{{ object.title }}
{{ object.author.name }}
{{ object.body }}
templates/search/indexes/jsapp/articlepost_text.txt
3)使用命令创建索引
python manage.py rebuild_index # 建立索引文件
替换成jieba分词
1)将haystack源码复制到项目中并改名
'''1.复制源码中文件并改名 '''
将 C:\python37\Lib\site-packages\haystack\backends\whoosh_backend.py文件复制到项目中
并将 whoosh_backend.py改名为 whoosh_cn_backend.py 放在APP中如:jsapp\whoosh_cn_backend.py '''2.修改源码中文件'''
# 在全局引入的最后一行加入jieba分词器
from jieba.analyse import ChineseAnalyzer # 修改为中文分词法
查找
analyzer=StemmingAnalyzer()
改为
analyzer=ChineseAnalyzer()
2)Django内settings内修改相应的haystack后台文件名
# 全文检索框架配置
HAYSTACK_CONNECTIONS = {
'default': {
# 指定whoosh引擎
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
# 'ENGINE': 'jsapp.whoosh_cn_backend.WhooshEngine', #article.whoosh_cn_backend便是你刚刚添加的文件
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 添加此项,当数据库改变时,会自动更新索引,非常方便
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
setting.py
索引文件使用
from django.conf.urls import url
from . import views as view urlpatterns=[
url(r'abc/$', view.basic_search), ]
jsapp/urls.py
from django.shortcuts import render # Create your views here.
import json
from django.conf import settings
from django.core.paginator import InvalidPage, Paginator
from django.http import Http404, HttpResponse,JsonResponse
from haystack.forms import ModelSearchForm
from haystack.query import EmptySearchQuerySet
RESULTS_PER_PAGE = getattr(settings, 'HAYSTACK_SEARCH_RESULTS_PER_PAGE', 20) def basic_search(request, load_all=True, form_class=ModelSearchForm, searchqueryset=None, extra_context=None, results_per_page=None):
query = ''
results = EmptySearchQuerySet()
if request.GET.get('q'):
form = form_class(request.GET, searchqueryset=searchqueryset, load_all=load_all) if form.is_valid():
query = form.cleaned_data['q']
results = form.search()
else:
form = form_class(searchqueryset=searchqueryset, load_all=load_all) paginator = Paginator(results, results_per_page or RESULTS_PER_PAGE)
try:
page = paginator.page(int(request.GET.get('page', 1)))
except InvalidPage:
result = {"code": 404, "msg": 'No file found!', "data": []}
return HttpResponse(json.dumps(result), content_type="application/json") context = {
'form': form,
'page': page,
'paginator': paginator,
'query': query,
'suggestion': None,
}
if results.query.backend.include_spelling:
context['suggestion'] = form.get_suggestion() if extra_context:
context.update(extra_context) jsondata = []
print(len(page.object_list))
for result in page.object_list:
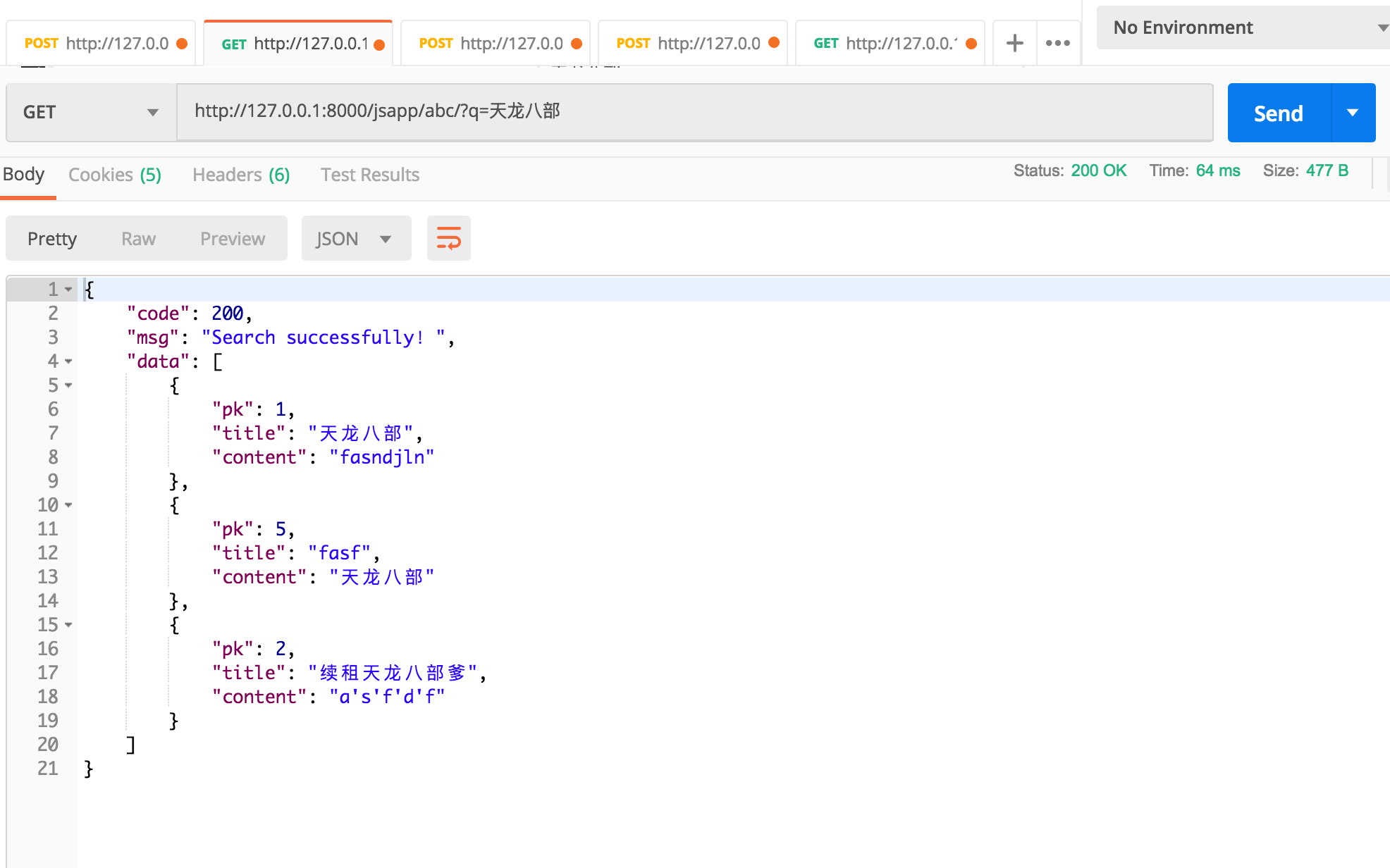
data = {
'pk': result.object.pk,
'title': result.object.title,
'content': result.object.body, }
jsondata.append(data)
result = {"code": 200, "msg": 'Search successfully!', "data": jsondata}
return JsonResponse(result, content_type="application/json")
jsapp/views.py
全文检索django-haystack+jieba+whoosh的更多相关文章
- Django Haystack 全文检索与关键词高亮
Django Haystack 简介 django-haystack 是一个专门提供搜索功能的 django 第三方应用,它支持 Solr.Elasticsearch.Whoosh.Xapian 等多 ...
- Django、haystack、whoosh实现全局搜索
Django.haystack.whoosh实现全局搜索 关注公众号"轻松学编程"了解更多. [参考:https://blog.csdn.net/zhaogeno1/article ...
- django haystack报错: ModuleNotFoundError: No module named 'blog.whoosh_cn_backend'
在配置django haystack时报错: 解决方案: 将ENGINE的值 改为 这样就可以了.
- 08: Django使用haystack借助Whoosh实现全文搜索功能
参考文章01:http://python.jobbole.com/86123/ 参考文章02: https://segmentfault.com/a/1190000010866019 参考官网自定制v ...
- django haystack
# coding=utf-8 from haystack import indexes from yw_asset.models import * class AssetIndex(indexes.S ...
- 全文检索:haystack+elasticsearch
优点: 1.查询速度快 2.支持中文分词准备工作:安装es软件 1.拷贝到ubuntu 2.docker load -i 文件路径 3.配置 修改ip地址 4.docker run -dti --ne ...
- Django haystack+solr搜索引擎部署的坑.
跟着<<Django by Example>> 一路做下来,到了搭建搜索引擎的步骤 默认的思路是用 obj.objects.filter(body__icontains='fr ...
- Django+haystack实现全文搜索出现错误 ImportError: cannot import name signals
原因是在你的settings.py或者其他地方使用了 "import haystack" 当我们使用django-haysatck库时,表面上会有haystack库,但实际上并不 ...
- Django之使用haystack+whoosh实现搜索功能
为了实现项目中的搜索功能,我们使用的是全文检索框架haystack+搜索引擎whoosh+中文分词包jieba 安装和配置 安装所需包 pip install django-haystack pip ...
随机推荐
- 快速傅里叶变换(FFT)学习笔记(其一)
再探快速傅里叶变换(FFT)学习笔记(其一) 目录 再探快速傅里叶变换(FFT)学习笔记(其一) 写在前面 为什么写这篇博客 一些约定 前置知识 多项式卷积 多项式的系数表达式和点值表达式 单位根及其 ...
- flex与bison的学习
获取bison http://www.gnu.org/software/bison 获取flex http://flex.sourceforge.net/ 本书的范例 ftp://ftp.iecc.c ...
- Youtube订阅——解决在弹窗内使用Youtube订阅按钮高度显示不全的问题
背景:公司网站业务在做海外营销网站,为了配合营销工作,前端总要在各种地方添加各种社媒订阅(摊手.jpg):最近遇到的是在弹窗内展示公司的Youtube账号的订阅按钮. 理想:我想使用的例子是这样的: ...
- Flink基础:实时处理管道与ETL
往期推荐: Flink基础:入门介绍 Flink基础:DataStream API Flink深入浅出:资源管理 Flink深入浅出:部署模式 Flink深入浅出:内存模型 Flink深入浅出:J ...
- 数组和list 相互转换中遇到的坑
代码示例: public class ArrayDemo { public static void main(String[] args) { Integer[] arr = {1, 2, 3, 4, ...
- IP/TCP/UDP checsum
今天调试bug时, 忘了将原始的check_sum值reset,导致发包-抓包后发现.check-sum 错误. 来看一看check-sum:简单讲就是对要计算的数据,以16bit为单元进行累加,然后 ...
- nginx&http 第六章 http 协议学习 1
1.HTTP方法 GET :获取资源 ,GET 方法用来请求访问已被 URI 识别的资源 POST:传输(上传和下载)实体主体 ,POST 方法用来传输实体的主体.虽然用 GET 方法也可以传输实体的 ...
- Pinpoint 编译环境搭建(Pinpoint系列一)
本文基于 Pinpoint 2.1.0 版本 目录 一.2.1.0 版本特性 二.编译环境准备 三.编译注意事项 四.编译目录 五.注意事项 新版本的内容参考官方文档, Pinpoint的整个搭建是历 ...
- Apache Shiro 1.2.4反序列化漏洞(CVE-2016-4437)复现
Apache Shiro 1.2.4反序列化漏洞(CVE-2016-4437)复现 环境搭建 docker pull medicean/vulapps:s_shiro_1 docker run -d ...
- ctf-misc-图片隐写术套路总结
1.直接右键notepad打开,搜索flag,如果图片很多的话,可以写py脚本也 可以打开后搜索全部打开文件 2.是一个压缩包,改了后缀 3.图片中藏了一个二维码,用Stegsolve加几次滤镜 ...