深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
前阵子工作上需要用到Calcite做一些事情,然后发现这个东西也是蛮有意思的,就花了些时间研究了一下。本篇主要围绕SQL 优化这块来介绍Calcite,后面会介绍Hive如何Calcite进行SQL的优化。
此外,也将Calcite的一些使用样例整理成到github,https://github.com/shezhiming/calcite-demo。里面包含了基础的CSV适配器例子,从这个例子延伸出的SQL解析,校验,RBO优化,CBO优化,以及自定义RelNode,自定义Cost信息,自定义rule等使用用例。如果觉得有帮助不妨点个start吧。
Calcite简介与CBO介绍
Calcite背景与介绍
先来说Calcite出现的背景,在上世纪,关系型数据库系统基本主导了数据处理领域,但是在Google三篇创世纪论文发表后,大家开始意识到,一种适合所有场景的数据库是不存在的。事实上,今天也确实是这样,许多特定场景下的数据处理系统已经成为主流,比如流处理领域的Flink,Storm,批处理领域的Spark SQL,文本搜索领域的Elasticsearch等等。而在开发不同特定场景的数据处理系统的时候,有两个主要问题。
- 一个是每种系统基本都需要查询语言(SQL)及相关拓展(比如流式SQL查询),或是开发过程中碰到查询优化问题,没有一个统一框架,那么每个系统都要一套自己的查询解析框架,那无疑是在重复造轮子。
- 另一个问题是,开发的这些系统通常要对接或集成其他系统,比如Kylin集成MR,Spark,Hbase等,如何支持跨异构数据源也是一个问题。
Calcite就是为了解决这些问题而生的。
说完背景,再来简单介绍Calcite。从功能上说,Calcite提供了通过SQL管理数据的能力,但是它本身不存储数据。最简单的例子,假如你有一些CSV文件,想通过SQL来查询这些CSV文件,那Calcite就很适合。要做到这一点,只需要提供一个有关CSV的适配器,告诉Calcite文件位置,字段这些信息(这些信息称为Schema)。Calcite就可以帮你实现SQL查询这些CSV文件,这只是最基础的功能。当然这个例子有些鸡肋,将CSV可以直接导入到Mysql同样能用SQL查询,但换个东西,Elasticsearch的数据,你总不能导到Mysql再用SQL查吧,这时候就能用Calcite实现SQL检索ES的数据。
具体CSV适配器例子,可以看我在最开始的github代码里面看到,:Calcite-demo-csv
实际效果大概是这样:
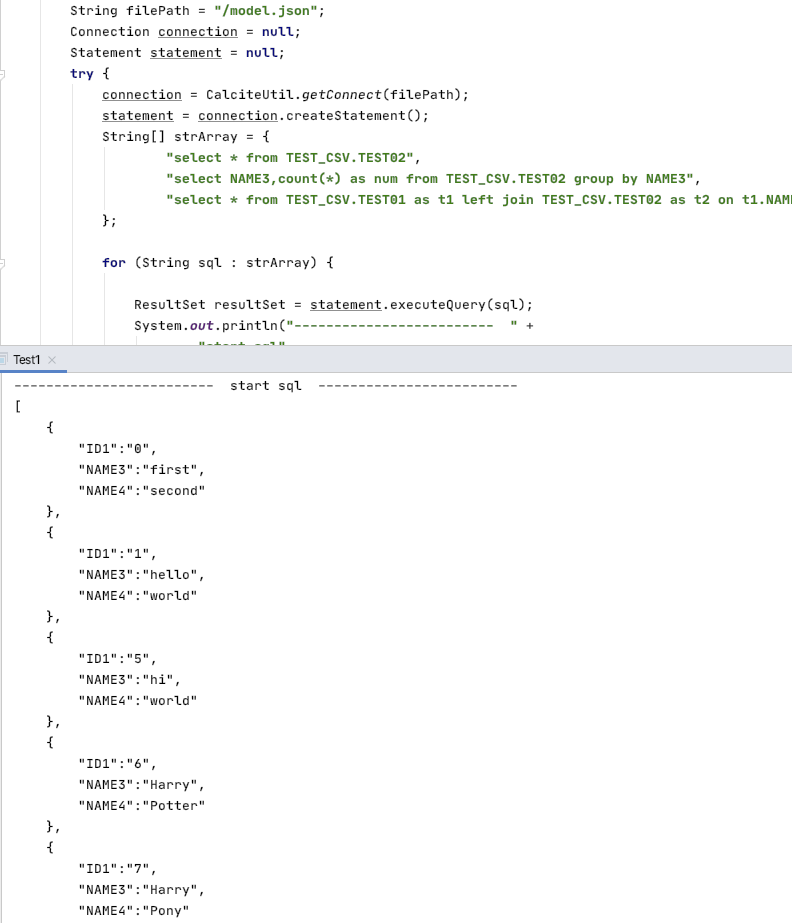
上述例子通过从配置文件中获取定义的Schema信息,然后就能编写对应的SQL进行查询。
从设计特点来说,因为Calcite的目的是提供一个通用的查询引擎,所以它的设计目标就是flexible, embeddable, and extensible,即灵活,可插拔,可拓展。这里可以顺便看一下它的架构图:

Calcite中的各个模块,Parse,Validate,Optimizer,都是可以单独拿出来用,并且可以方便得对其进行拓展。比如你想拓展你的SQL解析,想支持诸如"my select t1.a from t1"这样的语句,Calcite就有提供对应的接口(当然这算是比较高级的用法)。所以诸多开源框架,包括大家耳熟能详的Apache Hive,Apche Storm,Apache Flink,Apache Kylin等等,都会选择使用Calcite作为自己的SQL解析引擎,因为通用的东西直接用,定制化的东西可以方便得自定义。
此外,Calcite还有一些高级用法,比如物化视图,流式SQL支持等等,这里就不做展开。
接下来再介绍下SQL优化。
SQL优化与CBO
SQL从诞生到现在已经有几十年的时间了,尽管前几年nosql一度自我感觉良好号称要去掉sql,却也被现实教做人不得不改口,说是自己其实是not only sql,从这点可以看出sql语言的强大和通用。
说回sql,sql是一种声明式语言,所谓声明式,就是用户只需要告诉机器我要什么样的结果,机器会自己摸索并帮助用户找到结果返回。与之相比的是命令式语言,需要详细告诉机器如何执行,比如常见的编程语言。
那么作为声明式语言,如何帮助用户高效准确地获取到结果,这就是机器的责任。在这其中,SQL优化是许多研究者一直在探索的一个领域。
SQL优化的发展,则可以分为两个阶段,即RBO(Rule Base Optimization),和CBO(Cost Base Optimization)。
先简单说下RBO,RBO主要是开发人员在使用SQL的过程中,有些发现有些通用的规则,可以显著提高SQL执行的效率,比如最经典的filter下推:
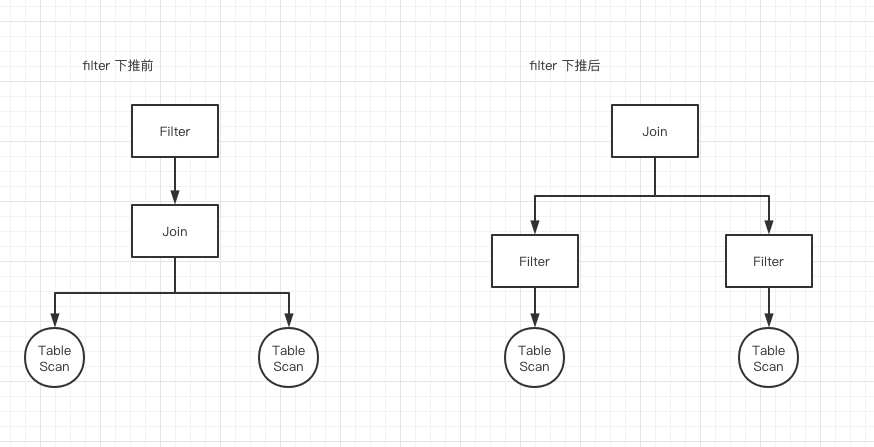
上面图片的意思很明显,我们都知道join是非常耗时的一个操作,且性能与join双方数据量大小呈线性关系(通常情况下)。那么很自然的一个优化,就是尽可能减少join左右双方的数据量,于是就想到了先filter再join这样一个rule。而非常多个类似的rule,就构成了RBO。
但后面开发者发现,RBO确实能够对通用情况下对SQL进行优化,但在有些需要本地状态才能优化的场景却无能为力。比如某个计算引擎,在数据量小于XXX的时候,可以做一些特殊的优化操作,这种场景下RBO无能为力。
而这就是CBO出现的背景了,CBO全称Cost Base Optimization,基于Cost的优化,其中Cost指的是执行SQL所需要的资源,通常是行数rowcount,CPU,内存,IO等等。基于Cost意思就是根据需要的资源,做更加智能的优化。
最典型的例子,就是Spark的join的选择。在Spark中,join会触发Shuffle操作,这种操作类型是非常消耗资源的。而Spark有三种类型的join,分别是broadcase join,将小的表广播到所有节点,在内存中hash碰撞进行join,这种join避免节点间shuffle操作,性能最好,但条件也苛刻。第二种是hash join,就是普通的shuffle join。第三种是sort merge join,先排序然后join,类似归并的思想,排序后能减少一些hash碰撞后的数据扫描,在join双方都是大表的情况下性能较好。
选择哪种类型的join,就要根据数据类型来选择,如果一方是小表,就用broadcase join,如果双方都是大表,就用sort merge join,否则就是 hash join。而这就需要用到Cost的信息了。
小结一下,RBO和CBO的区别大概在于,RBO只会无脑得应用提供的rule,而CBO会根据给出的Cost信息,智能应用rule,求出一个Cost最低的执行计划。需要纠正很多人误区的一点是,CBO其实也是基于rule的,接触到RBO和CBO这两个概念的时候,很容易将他们对立起来。但实际上CBO,可以理解为就是加上Cost的RBO。
Calcite优化器
HepPlanner优化器与VolcanoPlanner优化器
Calcite提供了两类型的优化器,即上述所说的RBO优化器和CBO优化器,在Calcite中的具体实现类对应HepPlanner(RBO)和VolcanoPlanner(CBO)。
其中HepPlanner简单理解就是两个循环,第一个循环会遍历用户提供的rule,第二个循环会遍历SQL树的节点,每当rule匹配到对应树节点的时候,会重新进行一遍循环。这个比较好理解。
而VolcanoPlanner则相对复杂一些,它不是简单地应用rule,而是会使用动态规划算法,计算每种rule匹配后生成新的SQL树的Cost信息,与原先SQL树的Cost信息相比较,如果新的树的Cost比较低,那么才会真正应用对应的rule。
当然这里都只是简单介绍,更加具体的内容,可以看看下面的两篇文章,一篇主要从理论的角度介绍了Calcite优化的原理,一篇从源码实现的角度剖析优化流程。
同时我的github代码中也有提供RBO和CBO相关的测试样例(主要是Test5和Test6),可以通过debug来看具体的执行流程,再结合理论和上述文章的解析,相信会有更加深入的理解。
Calcite优化样例代码介绍
github代码中Test6主要对比了RBO和CBO的差异,这里再顺便说下Test6测试样例的逻辑,其中的输出结果大概是这样:
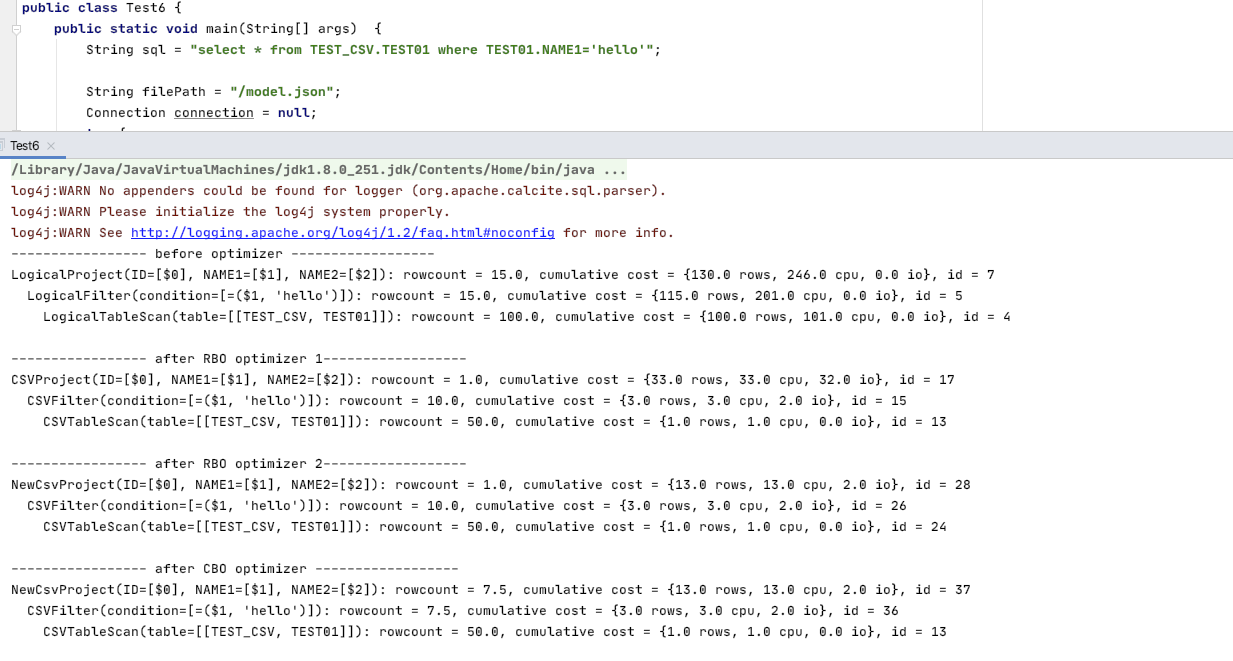
这里有比较多自定义的内容,不过也很好理解。最开始就是简单地将SQL解析成RelNode树(RelNode可以理解树节点吧)。然后提供自定义的rule,使用RBO将对应RelNode转成CSV类型的RelNode(RBO optimizer 1),改变下rule顺序,会发现生成了NewCsvProject而不再是CSVProject(RBO optimizer 2)。
最后是CBO,代码实现是自定义了一个CsvProject->NewCsvProject的rule,添加到VolcanoPlanner中。最终会发现,修改NewCsvProject的computeSelfCost()方法返回的Cost信息,该条rule会产生不同的效果,即CBO的体现。
以上就是本篇的全部内容,下面一篇主要介绍hive Sql解析的流程,以及在这个过程中如何应用Calcite来进行优化。
参考文章:
相关论文:
- Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
- The Volcano Optimizer Generator: Extensibility and Efficient Search
- The Cascades Framework for Query Optimization
深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化的更多相关文章
- Spark SQL 性能优化再进一步:CBO 基于代价的优化
摘要: 本文将介绍 CBO,它充分考虑了数据本身的特点(如大小.分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan. Spark ...
- Spark SQL includes a cost-based optimizer, columnar storage and code generation to make queries fast.
https://spark.apache.org/sql/ Performance & Scalability Spark SQL includes a cost-based optimize ...
- 【SQL系列】深入浅出数据仓库中SQL性能优化之Hive篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[SQL系列]深入浅出数据仓库中SQL性能优化之 ...
- CBO 基于成本的优化器[基础]
转载:CBO基于成本的优化器 ----------------------------------2013/10/02 CBO基于成本的优化器:让oracle获取所有执行计划的相关信息,通过对这些信息 ...
- 「MySQL高级篇」explain分析SQL,索引失效&&常见优化场景
大家好,我是melo,一名大三后台练习生 专栏回顾 索引的原理&&设计原则 欢迎关注本专栏:MySQL高级篇 本篇速览 在我们上一篇文章中,讲到了索引的原理&&设计原则 ...
- SQL Server 聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值 ...
- pytorch1.0进行Optimizer 优化器对比
pytorch1.0进行Optimizer 优化器对比 import torch import torch.utils.data as Data # Torch 中提供了一种帮助整理数据结构的工具, ...
- Sql Server性能排查和优化懒人攻略
转载自作者zhang502219048的微信公众号[SQL数据库编程]:Sql Server性能排查和优化懒人攻略 很多年前,笔者那时刚从广东技术师范学院(现为广东技术师范大学,以前为广东民族学院)的 ...
- 47、Spark SQL核心源码深度剖析(DataFrame lazy特性、Optimizer优化策略等)
一.源码分析 1. ###入口org.apache.spark.sql/SQLContext.scala sql()方法: /** * 使用Spark执行一条SQL查询语句,将结果作为DataFram ...
随机推荐
- 在 Go 语言中,我为什么使用接口
强调一下是我个人的见解以及接口在 Go 语言中的意义. 如果您写代码已经有了一段时间,我可能不需要过多解释接口所带来的好处,但是在深入探讨 Go 语言中的接口前,我想花一两分钟先来简单介绍一下接口. ...
- SSM整合 完美支持RESTful(Jsp和客户端<android ios...>)
一 RESTful简介 RESTful是一种网络应用程序的设计风格和开发方式 它结构清晰 符合标准 易于理解 扩展方便 REST 即Representational State Transfer的缩写 ...
- Js中的各种高度问题
一.屏幕宽高相关 屏幕高度就是你的整个屏幕高度(开机会亮的那片区域的高度),相关的其他高度划分很简单,就是以任务栏为分界线从而分为两部分. screen.height :屏幕高度. screen.wi ...
- YApi——手摸手,带你在Win10环境下安装YApi可视化接口管理平台
手摸手,带你在Win10环境下安装YApi可视化接口管理平台 YApi YApi 是高效.易用.功能强大的 api 管理平台,旨在为开发.产品.测试人员提供更优雅的接口管理服务.可以帮助开发者轻松创建 ...
- Hive执行count函数失败,Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException)
Hive执行count函数失败 1.现象: 0: jdbc:hive2://192.168.137.12:10000> select count(*) from emp; INFO : Numb ...
- vue+leaflet
1.index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- 解决VS Code安装golang相关插件失败问题
解决VS Code安装golang相关插件失败问题 VSCode作为一款优秀的编辑器,基本上前端开发,Python,markdown都可以用,真正是开发过程中的好帮手,所以学习go也当仁不让的要用vs ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- Manico--自定义应用快速切换
快速切换应用的app,使用非常频繁,奈何还是没有钱! 这玩意儿虽然免费,但是时不时跳一个弹框让你购买,也是够烦的,然后我们正好利用逆向工具,对着玩意儿进行破解,让它不再弹框! 下载安装Hopper D ...
- 使用Java8中的Optional类来消除代码中的null检查
简介 Optional类是Java 8新增的一个类,Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException). —— 每个 Java 程序员都非常了解的异常 ...