JAVA之G1与CMS垃圾回收
G1 GC,全称Garbage-FirstGarbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推出,相信熟悉JVM的同学们都不会对它感到陌生。在JDK 9中,G1被提议设置为默认垃圾收集器(JEP 248)。那么与之前的CMS相比,G1有哪些改变,哪些优势呢?
什么是CMS
CMS收集器是基于标记清除算法的一种并发的,低停顿的收集器,值得注意的一点是,CMS只是低停顿而不是没有停顿
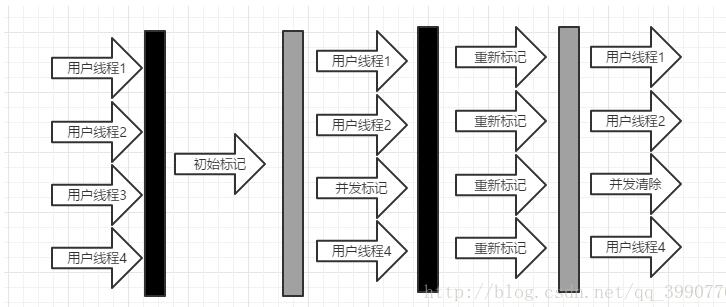
CMS分为以下四步:
l 初始标记
l 并发标记
l 重新标记
l 并发清除
初始标记和重新标记都是需要Stop the world的。
初始标记仅仅是记录CG root关联的对象,因此停顿时间比较短,并发标记是进行GC RootTracing,重新标记是修正并发标记期间标记的改动(时间比初始标记稍长一点),之后就是进行并发清除, 由于最耗时间的工作都是在并发操作中完成的,所以CMS的停顿会比较低
下面是CMS的过程图
CMS是一个优秀的垃圾回收器,但是他也有不少缺点:
l 他没有办法处理浮动垃圾(就是在初始标记之后产生的垃圾)
l 他会占用大量的CPU资源
l 他会产生碎片空间(当发生FullGC时会使用Serial Old回收器来处理碎片空间)
l 他在回收垃圾时,由于是并行的收集,所以需要的空间比较大
什么是G1
G1是一个并行回收器,它把堆内存分割为很多不相关的区间,每个区间可以属于老年代或者年轻代,并且每个年龄代区间可以是物理上不连续的。老年代区间这个设计理念本身是为了服务于并行后台线程,这些线程的主要工作是寻找未被引用的对象,而这样就会产生一种现象,即某些区间的垃圾(未被引用对象)多于其它的区间。垃圾回收时都是需要停下应用程序的,不然就没办法防止应用程序的干扰。G1 GC可以集中精力在垃圾最多的区间上,并且只费一点点时间就可以清空这些区间的垃圾,腾出完全空闲的区间。由于这种方式的侧重点在于处理垃圾最多的区间,所以我们给G1一个名字:垃圾优先(Garbage First)。
G1内部有四个操作阶段:
l 年轻代回收;(AYoung Collection)
l 运行在后台的并行循环;(ABackground,Concurrent Cycle)
l 混合回收;(A MixedCollection)
l 全量回收;(A FullGC)
CMS与G1的分析比较
分代收集
这个现在是垃圾回收器的标配,G1和CMS也不例外。但是G1同时回收老年代和年轻代,而CMS只能回收老年代,需要配合一个年轻代收集器。另外G1的分代更多是逻辑上的概念,G1将内存分成多个等大小的region,Eden/ Survivor/Old分别是一部分region的逻辑集合,物理上内存地址并不连续。
CMS在old gc的时候会回收整个Old区,对G1来说没有old gc的概念,而是区分Fullyyoung gc和Mixed gc,前者对应年轻代的垃圾回收,后者混合了年轻代和部分老年代的收集,因此每次收集肯定会回收年轻代,老年代根据内存情况可以不回收或者回收部分或者全部(这种情况应该是可能出现)。
如何处理跨代引用
在垃圾回收的时候都是从Root开始搜索,这会先经过年轻代再到老年代,对于年轻代引用老年代的这种跨代不需要单独处理。但是老年代引用年轻代的会影响young gc,这种跨代需要处理。
为了避免在回收年轻代的时候扫描整个老年代,需要记录老年代对年轻代的引用,young gc的时候只要扫描这个记录。CMS和G1都用到了Card Table,但是用法不太一样。JVM将内存分成一个个固定大小的card,然后有一个专门的数据结构(即这里的Card Table)维护每个Card的状态,一个字节对应一个Card,有点像内存page的概念,只是page是硬件上的,Card Table是软件上的。当一个Card上的对象的引用发生变化的时候,就将这个Card对应的Card Table上的状态置为dirty,young gc的时候扫描状态是dirty的Card即可。这是基本的用法,CMS基本上就是这么使用。
G1在Card Table的基础上引入的rememberedset(下面简称RSet)。每个region都会维护一个RSet,记录着引用到本region中的对象的其他region的Card。比如A对象在regionA,B对象在regionB,且B.f = A,则在regionA的RSet中需要记录B所在的Card的地址。这样的好处是可以对region进行单独回收,这要求RSet不只是维护老年代到年轻代的引用,也要维护这老年代到老年代的引用,对于跨代引用的每次只要扫描这个region的RSet上的Card即可。
上面说过年轻代到老年代的引用不需要单独处理,这带来了很大的性能上的提升,因为年轻代的对象引用变化很大,如果都需要记录下来成本会很高。同时也说明只需要在老年代维护Card Table。
如何处理并发过程的对象变化
CMS和G1都有并发处理过程,这个过程应用程序跟着gc线程一起运行,会产生新对象,也会有旧的对象死去,对象之间的引用关系也会发生变化。这部分数据可以暂时不处理,留到下一次再处理吗?如果可以这样的话问题就会变得很简单,但是答案是不行。考虑下图的场景(图中每一行表示一个内存状态,每一列表示一个Card,这里有4个):第一步a是并发标记中途的一个状态,标记了a b c e四个对象,0 1两个Card已经标记好;第二步b并发标记的同时引用发生变化,g不再指向d,而b不再指向c,变成指向d,这个时候处理Card 2,会标记到g,然后就标记结束了,导致d对象丢失。
CMS初始标记的时候会标记所有从root直接可达的对象,并发标记的时候再从这些对象进一步搜索其他可达对象,最终构成一个存活的对象图。并发标记过程中引用发生变化的也是通过Card Table来记录。但是young gc的时候如果一个dirty card没有包含到年轻代的引用,这个card会重新标记为clean,这有可能将并发标记过程产生的dirty card错误清除,因此CMS引入了另一个数据结构mod union table,这里一个bit对应一个Card,young gc在将Card Table设置为clean的时候会将对应的mod union table置为dirty。最终标记的时候会将Card Table或者mod union table是dirty的Card也作为root去扫描,从而解决并发标记过程产生的引用变化。CMS还需要处理并发过程从年轻代晋升到老年代的对象,处理方式是将这部分对象也作为root去扫描。
G1使用一个称为snapshot at thebeginning(下面简称SATB)的算法,在初始标记的时候得到一个从root直接可达的snapshot,之后从这个snapshot不可达的对象都是可以回收的垃圾,并发过程产生的对象都默认是活的对象,留到下一次再处理。对于引用关系发生变化的,将这个对象对应的Card放到一个SATB队列里,在最终标记的时候进行处理(如果超过一定的阈值并发标记的时候也会处理一部分),处理的过程就是以队列中的Card作为root进行扫描。
Write Barrier
Write Barrier可以理解为在写的时候插入一条特定的操作。
在CMS中老年代引用年轻代的时候就是通过触发一个Write Barrier来更新Card Table的标志位。这是一个同步操作,在更新引用的时候顺带执行,只需要两个指令,引入的消耗不大。
G1比较复杂,在两个地方用到了WriteBarrier,分别是更新RSet的rememberd set Write Barrier和记录引用变化的ConcurrentMarking Write Barrier,前者发生在引用更新之后,称为Post Write Barrier,后者发生在引用变化之前,称为Pre Write Barrier。G1为了提高性能,这两个Write Barrier都是先放到队列中,再异步进行处理。
Full GC
导致CMS Full GC的可能原因主要有两个:Promotion Failure和Concurrent Mode Failure,前者是在年轻代晋升的时候老年代没有足够的连续空间容纳,很有可能是内存碎片导致的;后者是在并发过程中jvm觉得在并发过程结束前堆就会满了,需要提前触发Full GC。CMS的Full GC是一个多线程STW的Mark-Compact过程,,需要尽量避免或者降低频率。
G1的初衷就是要避免Full GC的出现,Full GC会会对所有region做Evacuation-Compact,而且是单线程的STW,非常耗时间。导致G1Full GC的原因可能有两个:1. Evacuation的时候没有足够的to-space来存放晋升的对象;2. 并发处理过程完成之前空间耗尽。这两个原因跟CMS类似。
————————————————
版权声明:本文为CSDN博主「HelloWorld搬运工」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wufaliang003/article/details/80684379
JAVA之G1与CMS垃圾回收的更多相关文章
- CMS垃圾回收与G1垃圾回收
CMS垃圾回收与G1垃圾回收的比较请参见:http://colobu.com/2015/04/14/G1-Getting-Started/
- Java虚拟机内存模型及垃圾回收监控调优
Java虚拟机内存模型及垃圾回收监控调优 如果你想理解Java垃圾回收如果工作,那么理解JVM的内存模型就显的非常重要.今天我们就来看看JVM内存的各不同部分及如果监控和实现垃圾回收调优. JVM内存 ...
- Java进阶 JVM 内存与垃圾回收篇(一)
JVM 1. 引言 1.1 什么是JVM? 定义 Java Vritual Machine - java 程序的运行环境(Java二进制字节码的运行环境) 好处 一次编译 ,到处运行 自动内存管理,垃 ...
- CMS垃圾回收机制
详解CMS垃圾回收机制 原创不易,未经允许,不得转载~~~ 什么是CMS? Concurrent Mark Sweep. 看名字就知道,CMS是一款并发.使用标记-清除算法的gc. CMS是针对老 ...
- 图解 CMS 垃圾回收机制原理,-阿里面试题
最近在整理JVM相关的PPT,把CMS算法又过了一遍,每次阅读源码都能多了解一点,继续坚持. 什么是CMS CMS全称 ConcurrentMarkSweep,是一款并发的.使用标记-清除算法的垃圾回 ...
- 图解 CMS 垃圾回收机制,你值得拥有(转 强烈推荐)
首页 所有文章 资讯 Web 架构 基础技术 书籍 教程 Java小组 工具资源 - 导航条 - 首页 所有文章 资讯 Web 架构 基础技术 书籍 教程 Java小组 工具资源 ...
- 【译】Java SE 14 Hotspot 虚拟机垃圾回收调优指南
原文链接:HotSpot Virtual Machine Garbage Collection Tuning Guide,基于Java SE 14. 本文主要包括以下内容: 优化目标与策略(Ergon ...
- CMS 垃圾回收日志
CMS 垃圾回收日志 https://blogs.oracle.com/poonam/entry/understanding_cms_gc_logs http://www.blogjava.net/D ...
- Java虚拟机学习笔记——JVM垃圾回收机制
Java虚拟机学习笔记——JVM垃圾回收机制 Java垃圾回收基于虚拟机的自动内存管理机制,我们不需要为每一个对象进行释放内存,不容易发生内存泄漏和内存溢出问题. 但是自动内存管理机制不是万能药,我们 ...
随机推荐
- 解决 Oracle TNSListener 服务启动找不到路径问题
TNSListener服务无法启动,提示从系统无法找到指定路径! 解决方法: 在控制面板/管理工具/服务中双击打开OracleOraHome92TNSListener的服务看到其 “可执行文件的路径” ...
- 服务框架 Pigeon 的设计与实现
1.服务框架Pigeon架构 监控系统 - CAT,负责调用链路分析.异常监控告警 配置中心 - Lion,负责一些开关配置读取 服务治理 - Governor 一个interface定义为一个服务, ...
- Python的Struct模块
python strtuct模块主要在Python中的值于C语言结构之间的转换.可用于处理存储在文件或网络连接(或其它来源)中的二进制数据. #!/usr/bin/env python # -*- c ...
- 利用python3 爬取 网易云 上 周杰伦所有专辑,歌曲,评论,并完成可视化分析已经歌曲情绪化分析
这篇文章适合于python爱好者,里面可能很多语句是冗长的,甚至可能有一些尚未发现的BUG,这个伴随着我们继续学习来慢慢消解吧.接下来 我把里面会用到的东西在这里做一个简单总结吧:本文用到了两门解释性 ...
- rdb和aof二种持久化方式对比(Redis)
我们已经知道对于一个企业级的redis架构来说,持久化是不可减少的 企业级redis集群架构:海量数据.高并发.高可用 持久化主要是做灾难恢复,数据恢复,也可以归类到高可用的一个环节里面去 比如你re ...
- Spark(一)wordcount
Spark(一)wordcount 一.新建一个scala项目 在maven中导入 <!-- https://mvnrepository.com/artifact/org.apache.spar ...
- Math.pow
一个Math函数,例如:Math.pow(4,3);返回4的三次幂,用法:Math.pow(x,y) x 必需传.底数.必须是数字. y 必需传.幂数.必须是数字. 如果结果是虚数或负数,则该方法将返 ...
- pandas中DataFrame和Series的数据去重
在SQL语言中去重是一件相当简单的事情,面对一个表(也可以称之为DataFrame)我们对数据进行去重只需要GROUP BY 就好. select custId,applyNo from tmp.on ...
- spark_rdd 一波怼完面试官系列
Resilient Distributed dataset , 弹性分布式数据集. 分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现. RDD是Spark最核心的东西,它表 ...
- redistempalate的超时设置的操作更新
redistempalate的超时设置时,一定要每次用set写入时,更新超时,默认是不会自动更新的. 例如: int tempTime = this.redisTemplate.getExpire(& ...