Hadoop_19_MapReduce&&Yarn运行机制
1.YARN的运行机制
1.1.概述:
Yarn集群:负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager
Yarn是一个资源调度(作业调度和集群资源管理)平台,负责为运算程序提供服务器运算资源(包括运行
程序的jar包,配置文件,CPU,内存,IO等),相当于一个分布式的操作系统平台,而Mapreduce等运算程
序则相当于运行于操作系统之上的应用程序
Linux的资源隔离机制cgroup实现了CPU和内存的隔离(一个程序分配单独的CPU和内存),从而给不同的进
程分开运算资源,其中虚拟化技术就是做这种资源隔离的,例如Docker、OpenStack等,在NodeManager中的
运行容器Container就包含了一定的CPU+内存
1.2.YARN的重要概念:
1.Yarn只负责程序运行所需资源的分配回收等调度任务,与用户提交的应用程序的内部运行机制完全
无关,所以Yarn已经成为一个通用的资源调度平台,许多运算框架都可以借助它来实现资源调度,如spark
storm,从而提高资源利用率,方便数据共享
2.yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3.yarn中的主管角色叫ResourceManager
4.yarn中具体提供运算资源的角色叫NodeManager
5.这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程
序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……只要他们各自的框架中
有符合yarn规范的资源请求机制即可
1.3.MR运行在YARN集群的流程分析:
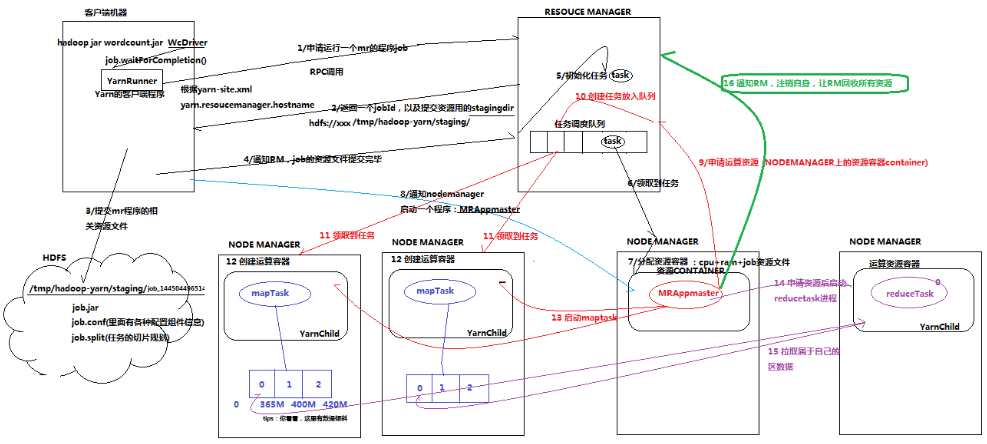
详细步骤说明:
提交过程
- 当客户端(jobclient)提交一个MapReduce程序(作业/job submission)后,将获取到一个跟Yarn通信的客户端程序YarnRunner,它本质上是一个动态代理对象。它负责将任务提交到Yarn集群中
- 接着,YarnRunner根据配置文件yarn-site.xml(yarn.resoucemanager.hostname)中的配置信息向ResourceManager申请提交一个Application,此时ResourceManager会返回一个Application资源提交路径hdfs://xxx/.staging以及job_id
- 提交程序运行所需资源到ResourceManager指定的HDFS目录中,包含job.split(任务的切片规划),job.xml,job.jar等,然后通知ResourceManager,job的资源文件提交完成,申请运行MRAppMaster
运行过程
- 由于ResourceManager会接收很多程序,而运算资源是有限的。因此不能保证每个任务一提交就能运行,所以需要有一个调度机制(调度策略包括FIFO:First Input First Output,先入先出队列;Fair;Capacity等)
- 然后由ResourceManager把Job封装成一个Task对象放入任务调度队列
- NodeManager与ResourceManager通信,领取需要运行的Task任务,并根据Task的任务描述,由NodeManager生成任务运行的容器container,并从HDFS上把任务需要的文件下载下来,放到container的工作目录中,启动MRAppmaster在该容器中运行
- MRAppmaster请求ResourceManager分配若干个Container来启动MapTask,此时ResourceManager同样会将Task放入队列中,NodeManager与ResourceManager通信时,会领取这个Task。然后由NodeManager创建一个容器,有了容器后,MRAppmaster会发送启动程序的脚本给NodeManager。MapTask就运行起来。并由MRAppmaster进行监管,如果某个MapTask失败了,MRAppmaster会申请一个新的容器去再运行这个MapTask
- 等到MapTask运行完毕之后,输出结果保存在container的工作目录下面
- MRAppmaster再申请容器运行ReduceTask
- ReduceTask运行起来以后,会去下载MapTask的输出结果,每个ReduceTask获取自己相应的分区数据,
- ReduceTask执行完毕后,MRAppmaster会向ResourceManager注销自己,YARN会回收所有的计算资源
总结:1. Yarn只负责程序运行所需要资源的分配回收等调度任务,和MapReduce程序只需要请求资源和Yarn并没有什么耦合。所以许许多多的其他的程序也可以在YARN上运行,比如说Spark,Storm等
2. Hadoop1中没有Yarn,它使用JobTracker和TaskTracker。客户端提交任务给JobTracker,JobTracker负责启动MapTask和ReduceTask。JobTracker知道我们的程序是怎么运行的,即JobTracker和MR程序是紧紧耦合在一起的,JobTracker只有一个节点,要负责资源调度和应用的运算流程管理监控,如果JobTracker挂了,所有的程序都不能运行了,而Hadoop2中MRAppmaster一旦挂了,只会影响到当前这一个程序
Hadoop_19_MapReduce&&Yarn运行机制的更多相关文章
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Flink on Yarn运行机制
从图中可以看出,Yarn的客户端需要获取hadoop的配置信息,连接Yarn的ResourceManager.所以要有设置有 YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOO ...
- hadoop Yarn运行机制
- Hadoop记录-MRv2(Yarn)运行机制
1.MRv2结构—Yarn模式运行机制 Client---客户端提交任务 ResourceManager---资源管理 ---Scheduler调度器-资源分配Containers ----在Yarn ...
- 经典MapReduce作业和Yarn上MapReduce作业运行机制
一.经典MapReduce的作业运行机制 如下图是经典MapReduce作业的工作原理: 1.1 经典MapReduce作业的实体 经典MapReduce作业运行过程包含的实体: 客户端,提交MapR ...
- 一文了解 Hadoop 运行机制
大数据技术栈在当下已经是比较成熟的了,Hadoop 作为大数据存储的基石,其重要程度不言而喻,作为一个想从 java 后端转向大数据开发的程序员来说,打好 Hadoop 基础,就相当于夯实建造房屋的地 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- 大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS.但要对 Hadoo ...
- day1--大数据概念,hadoop介绍,hdfs整体运行机制
1.什么是大数据 基本概念 在互联网技术发展到现今阶段,大量日常.工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用 ...
随机推荐
- System.Web.UI.Page的用法,一定要学会懒
在ASP.NET中,任何页面都是继承于System.Web.UI.Page,他提供了ASP.NET中的Response,Request,Session,Application的操作.在使用Visual ...
- sed例子
以care.log这个log文件为例, care.log: 05:44:31,816 DEBUG RawAggregationWorker:70 - LTS is working on Raw Dat ...
- 4.1 python类的特殊成员,偏函数,线程安全,栈,flask上下文
目录 一. Python 类的特殊成员(部分) 二. Python偏函数 1. 描述 2. 实例一: 取余函数 3. 实例二: 求三个数的和 三. 线程安全 1. 实例一: 无线程,消耗时间过长 2. ...
- jenkins:执行远程shell脚本时,脚本没有生效
问题: jenkins远程部署一台机器时,jenkins构建显示成功,但是查看服务日志却没有真正执行的sh run.sh脚本,导致服务并没有启动 解决: 只需要在命令最上方加上source /etc/ ...
- HashMap和ConcurrentHashMap 源码关键点解析
第一部分:关键源码讲解 1.HashMap 是如何存储的? a.底层是一个数组 tab b. hash=hash(key) ,然后根据数组长度n和hash值,决定当前需要put的元素对应的数组下标, ...
- spring boot跨域问题的简便解决方案
刚学spring boot的时候被跨域问题拦住好久,最终好不容易从网上抄了别人的极端代码才解决. 但是前些天看一同事的代码时,发现spring boot中用注解就可以解决. 在controller上添 ...
- Linux 如何找到100M以上的大文件
find / -type f -size +100000k |xargs ls -lh|awk '{print $9 ":" $5}'
- 《PC Assembly Language》读书笔记
本书下载地址:pcasm-book. 前言 8086处理器只支持实模式(real mode),不能满足安全.多任务等需求. Q:为什么实模式不安全.不支持多任务?为什么虚模式能解决这些问题? A: 以 ...
- MySQL中的触发器应用
直接上代码: /*数据库 - udi_ems_test*********************************************************************内容:在 ...
- TypeScript 解构
⒈解构数组 最简单的解构莫过于数组的解构赋值了: let input = [1, 2]; let [first, second] = input; console.log(first); // out ...