一次vaccum导致的事故
1. 问题出现
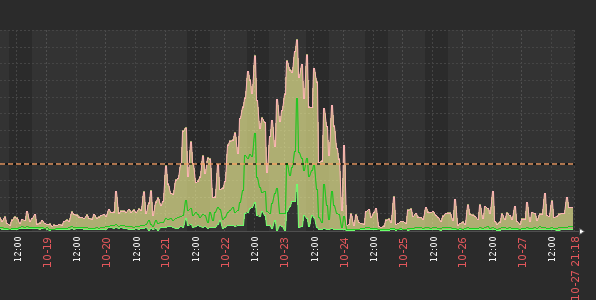
晚上9点,现场报系统查询慢,运维查询zabbix后发现postgres最近几天的IOWait很大
2. 追踪问题
查询数据库,发现很多SQL堵住了
原因是真正创建index,导致表锁住了,其他所有操作都block住了。 将这个操作取消掉后,发现系统自动将这个表进行autovacuum,很多SQL又堵住了。手工将vacuum停掉后,系统好了一点点,但还是较之前慢。
其中一个SQL 执行的频率很高,但一直需要执行很长时间:
19014 | sxacc-devices | AccessShareLock | PostgreSQL JDBC Driver | 2019-10-23 14:22:12.837273+00 | active | get_lock | 00:00:21.477812 |
SELECT COUNT(*) FROM "sxacc-devices" t WHERE (t.info->>'orgId')::text = '67572'
AND (t.info->>'modelName')::text = '804Mesh' AND (t.info->>'manufacturer')::text = 'Calix' AND (t.info->>'productClass')::text = '804Mesh'
AND (t.info->>'hardwareVersion')::text = '3000276410' AND (t.info->>'manufacturerOUI')::text = '44657F' AND (t.info->>'softwareVersion')::text = '1.1.0.100'
查询执行计划
cloud=# explain SELECT COUNT(*) FROM "sxacc-devices" t WHERE (t.info->>'orgId')::text = '7583' AND (t.info->>'modelName')::text = '804Mesh' AND (t.info->>'manufacturer')::text = 'Calix' AND (t.info->>'productClass')::text = '804Mesh' AND (t.info->>'hardwareVersion')::text = '3000276410' AND (t.info->>'manufacturerOUI')::text = 'CCBE59' AND (t.info->>'softwareVersion')::text = '2.0.1.112';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=2368.56..2368.57 rows=1 width=8)
-> Bitmap Heap Scan on "sxacc-devices" t (cost=2273.58..2368.56 rows=1 width=0)
Recheck Cond: (((info ->> 'softwareVersion'::text) = '2.0.1.112'::text) AND ((info ->> 'modelName'::text) = '804Mesh'::text))
Filter: (((info ->> 'orgId'::text) = '7583'::text) AND ((info ->> 'productClass'::text) = '804Mesh'::text) AND ((info ->> 'manufacturer'::text) = 'Calix'::text) AND ((info ->> 'hardwareVersion'::text) = '3000276410'::text) AND ((info ->> 'manufacturerOUI'::text) = 'CCBE59'::text))
-> BitmapAnd (cost=2273.58..2273.58 rows=83 width=0)
-> Bitmap Index Scan on sv_idex (cost=0.00..460.69 rows=3418 width=0)
Index Cond: ((info ->> 'softwareVersion'::text) = '2.0.1.112'::text)
-> Bitmap Index Scan on idx_sxacc_devices_model_name (cost=0.00..1812.65 rows=19706 width=0)
Index Cond: ((info ->> 'modelName'::text) = '804Mesh'::text)
这个SQL还算可以,虽然不是每个字段都走index,但大部分也走索引了,但还是需要执行很长时间,而且Read很高

关键是查询select count(*) from "sxacc-devices"也非常慢,根本查不出来的样子。
根据系统表查询这个表,发现总数据量只有78万多,但占用磁盘高达43GB,真实数据只有16GB,相差悬殊。

根据这个表的每小时统计信息发现一个奇怪的现象:
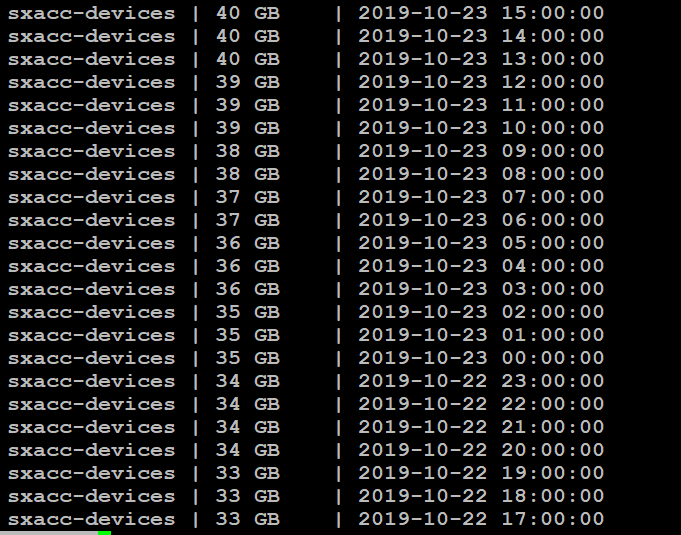
基本每3小时增长1GB,这是一个疯狂的操作。
查询系统vacuum记录,发现这个表在昨天还做个autovacuum,查询
SELECT relname,n_tup_ins as "inserts",n_tup_upd as "updates",n_tup_del as "deletes", n_live_tup as "live_tuples", n_dead_tup as "dead_tuples" FROM pg_stat_user_tables where relname='sxacc-devices'

这个表更新太过于频繁,决定手工vacuum一次, vacuum full analyze “sxacc-devices”, vacuum结束后发现这个表从40GB降到1GB. 执行完之后系统就回归正常。
分析:
由于这个表操作特别频繁,特别是更新过多,导致这个表的中间状态特别庞大,而autovacuum只会针对标识为删除的记录数进行删除,其他的不会做,导致这张表增长比较大。应该经常性的执行vacuum full去释放空间,但需要特别小心的是,但执行vacuum full的时候会进行表锁,导致操作这张表的sql block住,要特别小心。
3.通用查询
--active 的sql及查询时间
SELECT t.relname, l.locktype, page, virtualtransaction, l.pid, mode, granted,a.state,a.client_addr,age(clock_timestamp(), a.query_start), a.usename, a.query
FROM pg_locks l, pg_stat_all_tables t,pg_stat_activity a
WHERE l.relation = t.relid and l.pid=a.pid ORDER BY relation asc;
--表大小统计
select pg_size_pretty (pg_total_relation_size ('"sxacc-devices"')) as total,pg_size_pretty(pg_relation_size('"sxacc-devices"')) as relsize, pg_size_pretty (pg_indexes_size('"sxacc-devices"')) as idx --表查询效率统计
SELECT relname,n_tup_ins as "inserts",n_tup_upd as "updates",n_tup_del as "deletes", n_live_tup as "live_tuples", n_dead_tup as "dead_tuples" FROM pg_stat_user_tables where relname='sxacc-devices'
select * from pg_stat_bgwriter;
benchmarksql2=# select pg_current_xlog_location();
pg_current_xlog_location
--------------------------
4/E9B61648
(1 row) benchmarksql2=# select pg_xlog_location_diff('4/E9B61648','4/7027C648')/(60*5);
-[ RECORD 1 ]------------------
?column? | 6797899.093333333333
iotop
iostat -x 60 5
5. 关于Vacuum
Vacuum是postgres维护磁盘空间的工具,主要是删除标记为删除的数据并释放空间。 postgres执行delete操作后,数据库只是将该记录标识为delete状态,并不会立即清理空间,在后续的update或insert的时候,该空间不能被使用,只有经过vacuum清理后才能释放并重用。
vacuum的语法结构
VACUUM [ ( { FULL | FREEZE | VERBOSE | ANALYZE } [, ...] ) ] [ table_name [ (column_name [, ...] ) ] ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table_name ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table_name [ (column_name [, ...] ) ] ]

注意:
- Vacuum 不能在事务块内执行。
- 对于有GIN索引的表,VACUUM(以任何形式)也完成任何挂起索引插入内容,通过移动挂起索引条目到主GIN索引结构中相应的位置。
- 建议生产数据库经常清理(至少每晚一次),以保证不断地删除死行。尤其是在增删了大量记录之后, 对受影响的表执行VACUUM ANALYZE命令是一个很好的习惯。 这样做将更新系统目录为最近的更改,并且允许PostgreSQL 查询优化器在规划用户查询时有更好的选择。
- 不建议日常使用FULL选项,但是可以在特殊情况下使用。 一个例子就是在你删除或更新了一个表的大部分行之后, 希望从物理上缩小该表以减少磁盘空间占用并且允许更快的表扫描。VACUUM FULL 通常要比单纯的VACUUM收缩更多的表尺寸。
- VACUUM导致 I/O 流量增加,可能会导致其它活动会话的性能恶劣。因此, 有时候会建议使用基于开销的 vacuum 延迟特性。 参阅第 18.4.4 节获取细节。
- PostgreSQL包含一个"autovacuum"设施, 它可以自动进行日常的 vacuum 维护。关于手动和自动清理的更多细节, 参见第 23.1 节。
6. PG 产生IO的总结
- WAL写入
- 每个事务执行都会产生IO,同步提交时还会刷新磁盘。checkpoint后脏页的首次刷出是全页写,最糟糕的情况是每个小事务产生8K WAL写入,后面的WAL写入量可以粗略认为和数据更新两相当。
- 有个后台WAL写入进程专门把WAL buffer 写到磁盘,后台WAL刷的速度赶不上WAL Buffer写入速度时,postgres进程会直接把WAL Buffer写入磁盘。
- 后台写入器
- 后台写入器的目标为postgres进程预留足够的缓冲区,默认是最近所需的平均值的2倍(bgwriter_lru_multiplier),但默认每200毫秒(bgwriter_delay)不超过100个缓冲区(bgwriter_lru_maxpages)
- Checkpoint
- 每次checkpoint会刷出缓冲区中的所有脏页。触发checkpoint的时间有2个:一个默认5分钟(checkpoint_timeout)的定期检查点,另外一个是产生的WAL文件数超过checkpoint_segments。
- 9.5以后checkpoint_segments参数被取消掉了,改成了max_wal_size,WAL写入量超过max_wal_size的1/3~1/2时触发checkpoint
- 自动清理
- 自动清理可能会从磁盘读取数据块。每次自动清理的量可以通过相关参数控制。
- postgres进程
- 读入缓冲区中缺失的页时会产生磁盘读。
- WAL后台写入忙不过来时,pg进程会直接写和刷WAL
- 后台写入器未能预留足够的缓冲区时,刷出脏的缓冲区。
- work_mem不足时生成临时文件也会产生IO
7. PG 间隔大量写IO的解决方法
为了保证数据的可靠性,pg通常将脏页写入磁盘前,先将WAL日志写入磁盘,然后将修改的数据异步分批写入。
为了保证好的读写性能,修改的数据先写到Shared buffer中,而不是直接写入磁盘,因为数据页很离散(修改的数据分布在不同的表中)。数据库会把WAL日志顺序写入磁盘。
postgres两种写方式:write和fsync
write:数据库会将buffer中的脏页数据根据写入策略将老化的脏页写道OS,OS再根据调度算法写入磁盘。
fsync:数据库直接调用OS的fsync函数,直接写入磁盘。
OS 内核参数:
| 参数 | 设置方法 | 含义 |
| dirty_background_ratio |
sysctl -a|grep vm.dirty_background_ratio sysctl -p sysctl -a|grep vm.dirty_background_ratio 10 修改文件/proc/sys/vm/dirty_background_ratio
|
|
| dirty_expire_centisecs |
sysctl -a|grep vm.dirty_writeback_centisecs 修改文件 /proc/sys/vm/dirty_expire_centisecs |
|
| dirty_ratio |
sysctl -a|grep vm.dirty_ratio sysctl -p vm.dirty_ratio vim /proc/sys/vm/dirty_ratio |
|
| dirty_writeback_centisecs |
sysctl -a|grep vm.dirty_writeback_centisecs vim /proc/sys/vm/dirty_writeback_centisecs |
|
| dirty_background_bytes | sysctl -p vm.dirtybackgroundbytes |
|
数据库
| 参数 | 描述 |
| fsync |
|
| backend_flush_after |
|
| bgwrite_flush_after |
|
| checkpoint_flush_after |
|
| wal_write_flush_after |
|
Postgres IO:
https://blog.csdn.net/liyingke112/article/details/78844759
http://m.blog.chinaunix.net/uid-20726500-id-5741651.html
Postgres Vacuum:
https://www.cnblogs.com/gaojian/p/3272620.html
https://blog.csdn.net/pg_hgdb/article/details/79490875
https://confluence.atlassian.com/kb/optimize-and-improve-postgresql-performance-with-vacuum-analyze-and-reindex-885239781.html
https://www.percona.com/blog/2018/08/10/tuning-autovacuum-in-postgresql-and-autovacuum-internals/
https://www.postgresql.org/docs/9.5/routine-vacuuming.html
https://wiki.postgresql.org/wiki/VACUUM_FULL
https://wiki.postgresql.org/wiki/Introduction_to_VACUUM,_ANALYZE,_EXPLAIN,_and_COUNT
https://www.postgresql.org/docs/current/mvcc.html
GP:
https://gp-docs-cn.github.io/docs/best_practices/bloat.html#topic_gft_h11_bp
一次vaccum导致的事故的更多相关文章
- jvm 之 国际酒店 8 月 19 一次full GC 导致的事故
事故经过: 1 15:18收到短信报警:国际酒店调用OMS queryGorderOrderList方法失败:成单接口调用OMS获取token失败. 2 查看checkList发现15:18开始发 ...
- 记因PHP的内存溢出导致的事故之解决
如果对您有用记得关注,更多干货. 今天上午刚到公司,就有同事在公司群里反映某个计划任务出现问题了.我就怀着刨根问底的心,去查看了log.发现挺有意思的一个问题,PHP内存溢出导致脚本执行失败.那就一起 ...
- 记一次zabbix-server故障恢复导致的事故 zabbix-server.log -- One child process died
前言 zabbix-server昨天出了个问题,不停的重启.昨天摆弄到晚上也不搞清楚原因,按照网上说的各种操作,各种CacheSize.TimeOut.StartPollers都改了,还有什么Incl ...
- 一次 MySQL 误操作导致的事故,「高可用」都顶不住了!
这是悟空的第 152 篇原创文章 官网:www.passjava.cn 你好,我是悟空. 上次我们项目不是把 MySQL 高可用部署好了么,MySQL 双主模式 + Keepalived,来保证高可用 ...
- https网页加载http资源导致的页面报错及解决方案
https是当下的网站的主流趋势,甚至像苹果这样的大公司,则完全要求用户必须使用https地址. 然而对于以前http链接来说,我们往往就存在一个兼容性问题,因为你不可能一下就全部切换过去,应该在很长 ...
- 【腾讯Bugly干货分享】微信终端跨平台组件 Mars 系列 - 我们如约而至
导语 昨天上午,微信在广州举办了微信公开课Pro.于是,精神哥这两天的朋友圈被小龙的"八不做"刷屏了.小伙伴们可能不知道,下午,微信公开课专门开设了技术分论坛.在分论坛中,微信开源 ...
- 如约而至:微信自用的移动端IM网络层跨平台组件库Mars已正式开源
1.前言 关于微信内部正在使用的网络层封装库Mars开源的消息,1个多月前就已满天飞(参见<微信Mars:微信内部正在使用的网络层封装库,即将开源>),不过微信团队没有失约,微信Mars ...
- Uber能知道你是不是在开车的时候玩手机
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- js文件缓存之版本管理
以前也做过不少项目,但从来就没有把关注的目光投向过js文件缓存.最近终于在毫无意识的情况下跳进了这个大坑. 近几个月来的工作是一个交易系统持续改进项目,迭代发布周期大约为2~3周.最近一次迭代是V16 ...
随机推荐
- dotnet core use Redis to publish and subscribe
安装Redis 同样我这边再次使用Docker, 方便快捷: # 拉取镜像 docker pull redis # 运行镜像 docker run -d -p 6379:6379 --name red ...
- Spring @Transactional 事务机制
几个概念要清楚:事务的传播机制,事务的边界 工作原理 运行配置@Transactional注解的测试类的时候,具体会发生如下步骤 1)事务开始时,通过AOP机制,生成一个代理connection对象, ...
- 稀疏数组(java实现)
1.稀疏数组 当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组. 稀疏数组的处理方法是: 1.1记录数组一共有几行几列,有多少个不同的值 1.2把具有不同值的元素的行列 ...
- Mybatis笔记2
使用Mybatis完成的CRUD操作 个人总结的一些小规律 学习过程中碰到的错误: org.apache.ibatis.exceptions.PersistenceException: ### Err ...
- Python31之类和对象1(三大特征:多封继——多疯子)
一.对象: Python即是面向对象的编程也是面向过程的编程语言,其内部可谓是无处不对象,我们所熟知的列表,字符串等工厂函数本质上都是对象.对象其实是对属性和方法的封装. 属性是对象的静态特征 方法是 ...
- PAT(B) 1087 有多少不同的值(Java)规律
题目链接:1087 有多少不同的值 (20 point(s)) 题目描述 当自然数 n 依次取 1.2.3.--.N 时,算式 ⌊n/2⌋+⌊n/3⌋+⌊n/5⌋ 有多少个不同的值?(注:⌊x⌋ 为取 ...
- Scratch编程:快乐的小马(三)
“ 上节课的内容全部掌握了吗?反复练习了没有,编程最好的学习方法就是练习.练习.再练习.一定要记得多动手.多动脑筋哦~~” 01 — 游戏介绍 这是一款简单的小游戏,实现了一匹小马跑来跑去(小马有跑动 ...
- 正确使用SQLCipher来加密Android数据库
Android本身自带有不加密的数据库SQLite,如果要保存密码之类的敏感数据在本地的话方法一是使用字段加密解密算法,方法二是整个数据库都加密掉.如果只是加密解密某个字段(如password)就推荐 ...
- display的属性
在一般的CSS布局制作时候,我们常常会用到display对应值有block.none.inline这三个值.,display这个属性用于定义建立布局时元素生成的显示框类型.对于 HTML 等文档类型, ...
- python小实例——tkinter实战(计算器)
一.完美计算器实验一 import tkinter import math import tkinter.messagebox class calculator: #界面布局方法 def __init ...