一次vaccum导致的事故
1. 问题出现
晚上9点,现场报系统查询慢,运维查询zabbix后发现postgres最近几天的IOWait很大
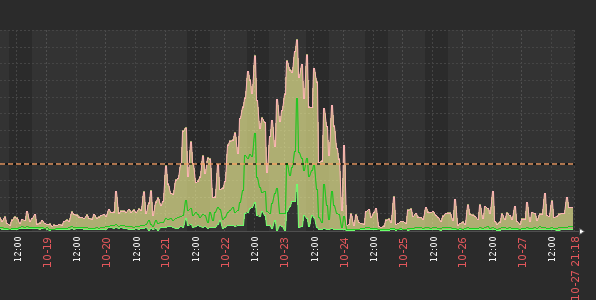
2. 追踪问题
查询数据库,发现很多SQL堵住了
原因是真正创建index,导致表锁住了,其他所有操作都block住了。 将这个操作取消掉后,发现系统自动将这个表进行autovacuum,很多SQL又堵住了。手工将vacuum停掉后,系统好了一点点,但还是较之前慢。
其中一个SQL 执行的频率很高,但一直需要执行很长时间:
19014 | sxacc-devices | AccessShareLock | PostgreSQL JDBC Driver | 2019-10-23 14:22:12.837273+00 | active | get_lock | 00:00:21.477812 |
SELECT COUNT(*) FROM "sxacc-devices" t WHERE (t.info->>'orgId')::text = '67572'
AND (t.info->>'modelName')::text = '804Mesh' AND (t.info->>'manufacturer')::text = 'Calix' AND (t.info->>'productClass')::text = '804Mesh'
AND (t.info->>'hardwareVersion')::text = '3000276410' AND (t.info->>'manufacturerOUI')::text = '44657F' AND (t.info->>'softwareVersion')::text = '1.1.0.100'
查询执行计划
cloud=# explain SELECT COUNT(*) FROM "sxacc-devices" t WHERE (t.info->>'orgId')::text = '7583' AND (t.info->>'modelName')::text = '804Mesh' AND (t.info->>'manufacturer')::text = 'Calix' AND (t.info->>'productClass')::text = '804Mesh' AND (t.info->>'hardwareVersion')::text = '3000276410' AND (t.info->>'manufacturerOUI')::text = 'CCBE59' AND (t.info->>'softwareVersion')::text = '2.0.1.112';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=2368.56..2368.57 rows=1 width=8)
-> Bitmap Heap Scan on "sxacc-devices" t (cost=2273.58..2368.56 rows=1 width=0)
Recheck Cond: (((info ->> 'softwareVersion'::text) = '2.0.1.112'::text) AND ((info ->> 'modelName'::text) = '804Mesh'::text))
Filter: (((info ->> 'orgId'::text) = '7583'::text) AND ((info ->> 'productClass'::text) = '804Mesh'::text) AND ((info ->> 'manufacturer'::text) = 'Calix'::text) AND ((info ->> 'hardwareVersion'::text) = '3000276410'::text) AND ((info ->> 'manufacturerOUI'::text) = 'CCBE59'::text))
-> BitmapAnd (cost=2273.58..2273.58 rows=83 width=0)
-> Bitmap Index Scan on sv_idex (cost=0.00..460.69 rows=3418 width=0)
Index Cond: ((info ->> 'softwareVersion'::text) = '2.0.1.112'::text)
-> Bitmap Index Scan on idx_sxacc_devices_model_name (cost=0.00..1812.65 rows=19706 width=0)
Index Cond: ((info ->> 'modelName'::text) = '804Mesh'::text)
这个SQL还算可以,虽然不是每个字段都走index,但大部分也走索引了,但还是需要执行很长时间,而且Read很高

关键是查询select count(*) from "sxacc-devices"也非常慢,根本查不出来的样子。
根据系统表查询这个表,发现总数据量只有78万多,但占用磁盘高达43GB,真实数据只有16GB,相差悬殊。

根据这个表的每小时统计信息发现一个奇怪的现象:
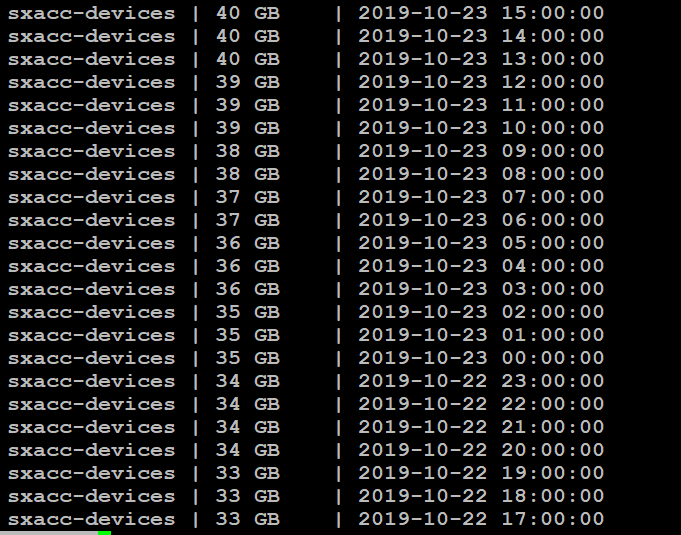
基本每3小时增长1GB,这是一个疯狂的操作。
查询系统vacuum记录,发现这个表在昨天还做个autovacuum,查询
SELECT relname,n_tup_ins as "inserts",n_tup_upd as "updates",n_tup_del as "deletes", n_live_tup as "live_tuples", n_dead_tup as "dead_tuples" FROM pg_stat_user_tables where relname='sxacc-devices'

这个表更新太过于频繁,决定手工vacuum一次, vacuum full analyze “sxacc-devices”, vacuum结束后发现这个表从40GB降到1GB. 执行完之后系统就回归正常。
分析:
由于这个表操作特别频繁,特别是更新过多,导致这个表的中间状态特别庞大,而autovacuum只会针对标识为删除的记录数进行删除,其他的不会做,导致这张表增长比较大。应该经常性的执行vacuum full去释放空间,但需要特别小心的是,但执行vacuum full的时候会进行表锁,导致操作这张表的sql block住,要特别小心。
3.通用查询
--active 的sql及查询时间
SELECT t.relname, l.locktype, page, virtualtransaction, l.pid, mode, granted,a.state,a.client_addr,age(clock_timestamp(), a.query_start), a.usename, a.query
FROM pg_locks l, pg_stat_all_tables t,pg_stat_activity a
WHERE l.relation = t.relid and l.pid=a.pid ORDER BY relation asc;
--表大小统计
select pg_size_pretty (pg_total_relation_size ('"sxacc-devices"')) as total,pg_size_pretty(pg_relation_size('"sxacc-devices"')) as relsize, pg_size_pretty (pg_indexes_size('"sxacc-devices"')) as idx --表查询效率统计
SELECT relname,n_tup_ins as "inserts",n_tup_upd as "updates",n_tup_del as "deletes", n_live_tup as "live_tuples", n_dead_tup as "dead_tuples" FROM pg_stat_user_tables where relname='sxacc-devices'
select * from pg_stat_bgwriter;
benchmarksql2=# select pg_current_xlog_location();
pg_current_xlog_location
--------------------------
4/E9B61648
(1 row) benchmarksql2=# select pg_xlog_location_diff('4/E9B61648','4/7027C648')/(60*5);
-[ RECORD 1 ]------------------
?column? | 6797899.093333333333
iotop
iostat -x 60 5
5. 关于Vacuum
Vacuum是postgres维护磁盘空间的工具,主要是删除标记为删除的数据并释放空间。 postgres执行delete操作后,数据库只是将该记录标识为delete状态,并不会立即清理空间,在后续的update或insert的时候,该空间不能被使用,只有经过vacuum清理后才能释放并重用。
vacuum的语法结构
VACUUM [ ( { FULL | FREEZE | VERBOSE | ANALYZE } [, ...] ) ] [ table_name [ (column_name [, ...] ) ] ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ table_name ]
VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ table_name [ (column_name [, ...] ) ] ]

注意:
- Vacuum 不能在事务块内执行。
- 对于有GIN索引的表,VACUUM(以任何形式)也完成任何挂起索引插入内容,通过移动挂起索引条目到主GIN索引结构中相应的位置。
- 建议生产数据库经常清理(至少每晚一次),以保证不断地删除死行。尤其是在增删了大量记录之后, 对受影响的表执行VACUUM ANALYZE命令是一个很好的习惯。 这样做将更新系统目录为最近的更改,并且允许PostgreSQL 查询优化器在规划用户查询时有更好的选择。
- 不建议日常使用FULL选项,但是可以在特殊情况下使用。 一个例子就是在你删除或更新了一个表的大部分行之后, 希望从物理上缩小该表以减少磁盘空间占用并且允许更快的表扫描。VACUUM FULL 通常要比单纯的VACUUM收缩更多的表尺寸。
- VACUUM导致 I/O 流量增加,可能会导致其它活动会话的性能恶劣。因此, 有时候会建议使用基于开销的 vacuum 延迟特性。 参阅第 18.4.4 节获取细节。
- PostgreSQL包含一个"autovacuum"设施, 它可以自动进行日常的 vacuum 维护。关于手动和自动清理的更多细节, 参见第 23.1 节。
6. PG 产生IO的总结
- WAL写入
- 每个事务执行都会产生IO,同步提交时还会刷新磁盘。checkpoint后脏页的首次刷出是全页写,最糟糕的情况是每个小事务产生8K WAL写入,后面的WAL写入量可以粗略认为和数据更新两相当。
- 有个后台WAL写入进程专门把WAL buffer 写到磁盘,后台WAL刷的速度赶不上WAL Buffer写入速度时,postgres进程会直接把WAL Buffer写入磁盘。
- 后台写入器
- 后台写入器的目标为postgres进程预留足够的缓冲区,默认是最近所需的平均值的2倍(bgwriter_lru_multiplier),但默认每200毫秒(bgwriter_delay)不超过100个缓冲区(bgwriter_lru_maxpages)
- Checkpoint
- 每次checkpoint会刷出缓冲区中的所有脏页。触发checkpoint的时间有2个:一个默认5分钟(checkpoint_timeout)的定期检查点,另外一个是产生的WAL文件数超过checkpoint_segments。
- 9.5以后checkpoint_segments参数被取消掉了,改成了max_wal_size,WAL写入量超过max_wal_size的1/3~1/2时触发checkpoint
- 自动清理
- 自动清理可能会从磁盘读取数据块。每次自动清理的量可以通过相关参数控制。
- postgres进程
- 读入缓冲区中缺失的页时会产生磁盘读。
- WAL后台写入忙不过来时,pg进程会直接写和刷WAL
- 后台写入器未能预留足够的缓冲区时,刷出脏的缓冲区。
- work_mem不足时生成临时文件也会产生IO
7. PG 间隔大量写IO的解决方法
为了保证数据的可靠性,pg通常将脏页写入磁盘前,先将WAL日志写入磁盘,然后将修改的数据异步分批写入。
为了保证好的读写性能,修改的数据先写到Shared buffer中,而不是直接写入磁盘,因为数据页很离散(修改的数据分布在不同的表中)。数据库会把WAL日志顺序写入磁盘。
postgres两种写方式:write和fsync
write:数据库会将buffer中的脏页数据根据写入策略将老化的脏页写道OS,OS再根据调度算法写入磁盘。
fsync:数据库直接调用OS的fsync函数,直接写入磁盘。
OS 内核参数:
| 参数 | 设置方法 | 含义 |
| dirty_background_ratio |
sysctl -a|grep vm.dirty_background_ratio sysctl -p sysctl -a|grep vm.dirty_background_ratio 10 修改文件/proc/sys/vm/dirty_background_ratio
|
|
| dirty_expire_centisecs |
sysctl -a|grep vm.dirty_writeback_centisecs 修改文件 /proc/sys/vm/dirty_expire_centisecs |
|
| dirty_ratio |
sysctl -a|grep vm.dirty_ratio sysctl -p vm.dirty_ratio vim /proc/sys/vm/dirty_ratio |
|
| dirty_writeback_centisecs |
sysctl -a|grep vm.dirty_writeback_centisecs vim /proc/sys/vm/dirty_writeback_centisecs |
|
| dirty_background_bytes | sysctl -p vm.dirtybackgroundbytes |
|
数据库
| 参数 | 描述 |
| fsync |
|
| backend_flush_after |
|
| bgwrite_flush_after |
|
| checkpoint_flush_after |
|
| wal_write_flush_after |
|
Postgres IO:
https://blog.csdn.net/liyingke112/article/details/78844759
http://m.blog.chinaunix.net/uid-20726500-id-5741651.html
Postgres Vacuum:
https://www.cnblogs.com/gaojian/p/3272620.html
https://blog.csdn.net/pg_hgdb/article/details/79490875
https://confluence.atlassian.com/kb/optimize-and-improve-postgresql-performance-with-vacuum-analyze-and-reindex-885239781.html
https://www.percona.com/blog/2018/08/10/tuning-autovacuum-in-postgresql-and-autovacuum-internals/
https://www.postgresql.org/docs/9.5/routine-vacuuming.html
https://wiki.postgresql.org/wiki/VACUUM_FULL
https://wiki.postgresql.org/wiki/Introduction_to_VACUUM,_ANALYZE,_EXPLAIN,_and_COUNT
https://www.postgresql.org/docs/current/mvcc.html
GP:
https://gp-docs-cn.github.io/docs/best_practices/bloat.html#topic_gft_h11_bp
一次vaccum导致的事故的更多相关文章
- jvm 之 国际酒店 8 月 19 一次full GC 导致的事故
事故经过: 1 15:18收到短信报警:国际酒店调用OMS queryGorderOrderList方法失败:成单接口调用OMS获取token失败. 2 查看checkList发现15:18开始发 ...
- 记因PHP的内存溢出导致的事故之解决
如果对您有用记得关注,更多干货. 今天上午刚到公司,就有同事在公司群里反映某个计划任务出现问题了.我就怀着刨根问底的心,去查看了log.发现挺有意思的一个问题,PHP内存溢出导致脚本执行失败.那就一起 ...
- 记一次zabbix-server故障恢复导致的事故 zabbix-server.log -- One child process died
前言 zabbix-server昨天出了个问题,不停的重启.昨天摆弄到晚上也不搞清楚原因,按照网上说的各种操作,各种CacheSize.TimeOut.StartPollers都改了,还有什么Incl ...
- 一次 MySQL 误操作导致的事故,「高可用」都顶不住了!
这是悟空的第 152 篇原创文章 官网:www.passjava.cn 你好,我是悟空. 上次我们项目不是把 MySQL 高可用部署好了么,MySQL 双主模式 + Keepalived,来保证高可用 ...
- https网页加载http资源导致的页面报错及解决方案
https是当下的网站的主流趋势,甚至像苹果这样的大公司,则完全要求用户必须使用https地址. 然而对于以前http链接来说,我们往往就存在一个兼容性问题,因为你不可能一下就全部切换过去,应该在很长 ...
- 【腾讯Bugly干货分享】微信终端跨平台组件 Mars 系列 - 我们如约而至
导语 昨天上午,微信在广州举办了微信公开课Pro.于是,精神哥这两天的朋友圈被小龙的"八不做"刷屏了.小伙伴们可能不知道,下午,微信公开课专门开设了技术分论坛.在分论坛中,微信开源 ...
- 如约而至:微信自用的移动端IM网络层跨平台组件库Mars已正式开源
1.前言 关于微信内部正在使用的网络层封装库Mars开源的消息,1个多月前就已满天飞(参见<微信Mars:微信内部正在使用的网络层封装库,即将开源>),不过微信团队没有失约,微信Mars ...
- Uber能知道你是不是在开车的时候玩手机
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- js文件缓存之版本管理
以前也做过不少项目,但从来就没有把关注的目光投向过js文件缓存.最近终于在毫无意识的情况下跳进了这个大坑. 近几个月来的工作是一个交易系统持续改进项目,迭代发布周期大约为2~3周.最近一次迭代是V16 ...
随机推荐
- mysql 事物控制语言
事务控制语言(DTL) 什么是事务 通常,在此之前,我们说,一条语句使用一个分号(;)来结束,并得到执行. 那么我们说,这个“一次性执行”的过程,可以称为“一个事务” ...
- Python:使用第三方库xlwt来写Excel
继上一篇文章使用xlrd来读Excel之后,这一篇文章就来介绍下,如何来写Excel,写Excel我们需要使用第三方库xlwt,和xlrd一样,xlrd表示read xls,xlwt表示write x ...
- Java的设计模式(7)— 生产者-消费者模式
生产者-消费者模式是一个经典的多线程设计模式,它为多线程间的协作提供了良好的解决方案.这个模式中,通常有两类线程,即若干个生产者线程和若干个消费者线程.生产者线程负责提交用户请求,消费者线程则负责具体 ...
- CodeForces-1159B-Expansion coefficient of the array
B. Expansion coefficient of the array time limit per test:1 second memory limit per test:256 megabyt ...
- Python程序设计基本方法图
Python程序设计基本方法图
- Python重要配置大全
PYTHON 环境安装 安装虚拟环境 pip install virtualenv 卸载包是用:pip uninstall virtualenv 快捷下载安装可用豆瓣源,方法为: pip instal ...
- Python复习笔记01
(1)计算机常识 计算机:硬件(运算器,控制器,存储器,输入设备,输出设备)软件 (系统软件, 应用软件) 二进制 整数存储 文件单 位换算 1Byte = 8bit 1KB = 1024Byte 1 ...
- ALV报表——ALV颜色设置(三)
目录 一.行 二.列 三.单元格 四.附ALV的颜色代码 一.行:用Layout相关属性设置 代码: *Report ZRFI001_XFL_TEST REPORT ZRFI001_XFL_TEST ...
- IOS微信浏览器返回事件监听问题
业务需求:从主页进入A订单页面,然后经过各种刷新或点标签加载后点左上角的返回直接返回到主页 采取方法:采用onpopstate事件监听url改变,从而跳转到主页 遇到的问题:安卓上测试没问题:苹果手机 ...
- Docker从入门到掉坑(五):继续挖一挖 k8s
在之前的几篇文章中,主要还是讲解了关于简单的docker容器该如何进行管理和操作及k8s上手避坑,在接下来的这篇文章开始,我们将继续对k8s模块的学习 pod是啥 在k8s里面,有很多新的技术概念,其 ...