容器--TreeMap
一、概述
在Map的实现中,除了我们最常见的KEY值无序的HashMap之外,还有KEY有序的Map,比较常用的有两类,一类是按KEY值的大小有序的Map,这方面的代表是TreeMap,另外一种就保持了插入顺序的Map,这类的代表是LinkedHashMap. 本文介绍TreeMap.
Java提供了两种可以用来排序的接口,分别是Comparable和Comparactor, 两者分别说明如下:
1. Comparable
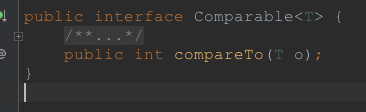
目前这是一个泛型接口,只有一个方法compareTo, 参与比较的类需要实现这个接口,这样该类便具备了可比较性,该方法的参数表示用来比较的对象。根据这个接口的返回值是 > 0, 小于0还是等于0决定了两个比较对象之间的大小关系。
如果一个类实现了这个接口,则该类的所有对象都是可比较的,也就是说,自身具备了比较的能力。JDK中的自带的一些类,比如Integer, Long等都具备比较的能力,原因就是它们实现了这个接口。
这种方式适合那些比较功能是类的特点之一的类,比如前面说到的Integer.
2. Comparator
除了Comparable,JDK还提供了一个接口用来比较,这就是Comparator,其接口定义如下:
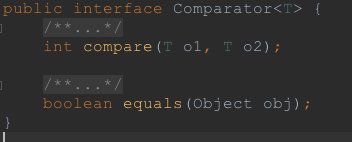
定义了两个方法,其中equals方法可以理解为是Object.equals的增加版本,功能和equal类似,用于比较的方法是compare, 其接收两个参数,这两个参数不需要实现任何接口,本方法负责根据一定的规则来比较两个对象的大小。
打个比较,这个接口的实现者好比是裁判,两个待比较的对象找它来比较大小,它根据自己定义的规则,结合两个对象的自身的数据,通过计算得出一个值,从而来决定哪个对象大哪个对象小。其本身并不参与比较。
有的时候待比较的对象并不需要具备可比较性,只是在某些场合下需要对它们的一个序列进行比较,或者说,可能会按多种规则对同一组序列进行比较,这个时候,用comparator构造构建器就非常合适,首先它不会侵入原类,另外,多种规则就是多个比较器,非常方便。
在JAVA里有关比较的下操作中,如集合排序等都提供了这两种方式的比较,我们可以根据情况进行选择。
二、实现原理分析
顾名思议,TreeMap的实现是基于Tree的数据结构,JAVA中可以用来排序的Tree,最有名的莫过于红黑树,而TreeMap的实现也正是基于红黑树,为了更好的理解红黑树,前面我们已经分了两篇来详细说明红黑树,在此不再细说。本文主要从各个方面分析TreeMap的构建和使用。
1. 创建
创建一个TreeMap,总共有四种方式,如下:
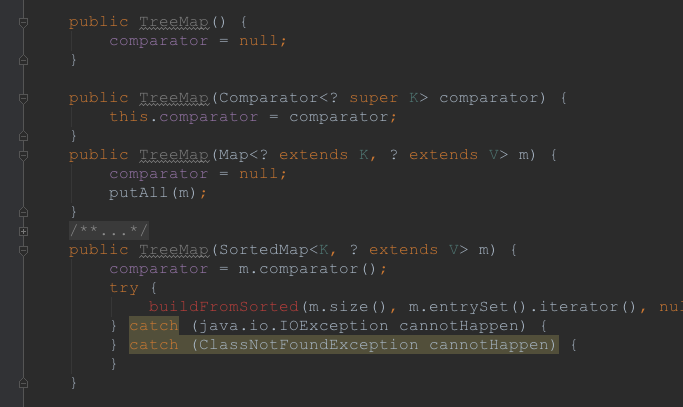
我们可以看到,TreeMap的这四种方式中其实主要分了两种,一是comparator为null的,一种是不为null的,作为一个有序的Map,如果comparator不为NULL,则自然是使用这个来比较,否则,KEY应该继承Comparable接口,这个也是前面解释过的。
作为一个红黑树,那么整个数据的存储则必是一颗树,TreeMap的实现也遵守了这一点,我们可以看一下对于树的构造。
首先,有一个表示根节点的变量。

其次,我们看一下节点的定义,也具备红黑树节点的性质
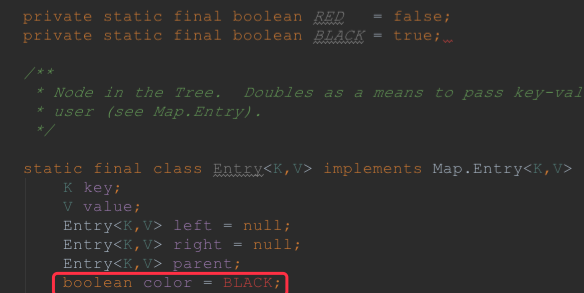
可以看到节点的定义中除了有key和value之外,还有左孩子,右孩子,父节点,以及节点的颜色,根据这三个属性,我们可以很方便的从任何一个节点向上一级或者向下一级导航。通过对节点设置颜色,很容易实现红黑树的相关算法。
2. 添加
添加指添加一个新节点到树的合适位置。那么这个分类两个部分,首先是要找到合适的节点,这个可以通过二叉树的查找算法来完成,查找之后有两个结果,如果找到相同的KEY了,则做更新操作,如果没有找到,则需要把节点和原来的树关联,关联之后,由于可能会破坏红黑树的性质,所以还要根据情况再做一次调整。
具体的算法如下:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
上面的代码就是整个添加的过程,关键的地方进行了加粗显示,可以看到,在查找的时候,实现时根据比较器是否存在来决定采用哪一种方式进行比较,如果比较之后没有找到对应的节点,则parent变量记录了最后一个不为叶子节点的节点,该节点即为新节点的父节点。新增后,需要对树重新做调整。
调整算法已经在红黑树部分介绍过了,所以这里就不再细说。
3. 删除
删除的话同样也是先通过二叉树的查找算法找到对应的节点,如果节点有两个孩子节点,则需要进一步查找其直接后继,然后针对其后继节点做删除操作。这样可以保证被删除的元素只有最多不超过一个节点。
删除完成后,根据被删除节点的后继节点的情况做相应的删除修复操作,以保证删除后,原树还是一个红黑树,删除的完整代码如下:
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
修复的操作在前面的红黑树中已经介绍了,就不再详细分析了。
4. 遍历操作
和普通的Map相比,作为一个排序Map,TreeMap也提供了各种遍历的操作,如headMap, tailMap,descendingMap等,我们可以方便的进行正序或倒序的遍历,这得益于节点的双向关联。在此不再一一描述
三、总结
至此,基于红黑数的TreeMap就算是完全分析完了,这是一种很经典的实现,通过对其源码的分析我们可以更深刻的理解红黑树,也可以学习到一些好的设计思想。同时,也有助于我们正确地使用红黑树
容器--TreeMap的更多相关文章
- Map容器——TreeMap及常用API,Comparator和Comparable接口
TreeMap及常用API ① TreeMap类通过使用红黑树实现Map接口; ② TreeMap提供按排序顺序存储键/值对的有效手段,同时允许快速检索; ③ 不像散列(HashMap), ...
- Comparable接口——容器中自定义类排序
1.容器TreeMap,默认根据Key对象中某个属性的从小到大排列元素. (1)如下代码示例,Key是整型数字,所以按照其从小到大的顺序排列 public class TestTreeMap { pu ...
- 数据结构 - Codeforces Round #353 (Div. 2) D. Tree Construction
Tree Construction Problem's Link ------------------------------------------------------------------- ...
- [个人原创]关于java中对象排序的一些探讨(一)
有的时候我们需要将自己定义的对象,有序输出.因为一般我们程序的中间结果需要存储在容器里,那么怎样对容器中的对象按照一定次序输出就是程序员经常需要考虑的问题.本片文章探讨了怎样有序化输出容器中的对象的问 ...
- Java中统计字符串中各个字符出现的次数
import java.util.Iterator; import java.util.Set; import java.util.TreeMap; public class TreeMapDemo ...
- 给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
- Java 容器 & 泛型:五、HashMap 和 TreeMap的自白
Writer:BYSocket(泥沙砖瓦浆木匠) 微博:BYSocket 豆瓣:BYSocket Java 容器的文章这次应该是最后一篇了:Java 容器 系列. 今天泥瓦匠聊下 Maps. 一.Ma ...
- java:容器/集合(Map(HashMap,TreeMap)Collection和Collections,(Collection-value();)
*Map接口:采用是键值对的方式存放数据.无序 HashMap: *常见的实现类: *--HashMap:基于哈希表的 Map 接口的实现. *常用的构造方法: * HashMap()构造一个具有默认 ...
- Java 容器源码分析之 TreeMap
TreeMap 是一种基于红黑树实现的 Key-Value 结构.在使用集合视图在 HashMap 中迭代时,是不能保证迭代顺序的: LinkedHashMap 使用了双向链表,保证按照插入顺序或者访 ...
随机推荐
- spring-boot 和 docker 集成
描述 java 的 Spring是一个很火的框架,Spring boot 这个也不用说了,Docker 近年也很火热, 本文就介绍下我在 Spring boot + Docker的集成一些经验 :) ...
- Azure PowerShell (2) 修改Azure订阅名称
<Windows Azure Platform 系列文章目录> Update: 2016-01-11 笔者文档主要都是用Azure PowerShell 0.x版本来实现的,比如0.98版 ...
- 混合 Data Warehouse 和 Big Data 倉庫的新架構
(讀書筆記)許多公司,儘管想導入 Big Data,仍必須繼續用 Data Warehouse 來管理結構化的營運數據.系統記錄.而 Big Data 的出現,為 Data Warehouse 提供了 ...
- Module-Zero之发布说明
返回<Module Zero学习目录> ABP v0.7.6.0 创建组织单元系统. 升级了nuget包. 小修复和改进. 注意: AbpUserManager的构造函数更新了.添加了组织 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (36) ------ 第六章 继承与建模高级应用之TPC继承映射
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 6-12 TPC继承映射建模 问题 你有两张或多张架构和数据类似的表,你想使用TP ...
- MySQL外键之级联
简介 MySQL外键起到约束作用,在数据库层面保证数据的完整性.例如使用外键的CASCADE类型,当子表(例如user_info)关联父表(例如user)时,父表更新或删除时,子表会更新或删除记录,这 ...
- 30个你必须记住的CSS选择符
所以你学会了基础的id,类和后代选择符,然后你就一直用它们了吗?如果是这样,你丢失了(css的)巨大的灵活性.在本文中提到的很多选择器属于CSS3规范的一部分,因此,只有在现代浏览器中才可使用. 1. ...
- webpack的安装和使用
Webpack是什么 首先可以看下 官方文档 ,文档是最好的老师. Webpack是由Tobias Koppers开发的一个开源前端模块构建工具.它的基本功能是将以模块格式书写的多个JavaScrip ...
- 使用Ado.net执行SP很慢,而用SSMS执行很快
今天遇到一个问题,有用户反应,在site上打开报表,一直loading,出不来结果. 遇到这种问题,我立刻simulate用户使用Filter Condition,问题repro,看来不是偶然事件,通 ...
- 无法在“EntityFramework”已存在的情况下创建影像复制该文件的解决方案
问题产生的原因:你项目正在生成中你就打开浏览器预览了,导致这个问题解决方案:右击重新生成项目,等生成后再打开 “/”应用程序中的服务器错误. 无法在“EntityFramework”已存在的情况下创建 ...