Flink SQL项目实录
一、Flink SQL层级
为Flink最高层的API,易于使用,所以应用更加广泛,eg. ETL、统计分析、实时报表、实时风控等。
Flink SQL所处的层级:
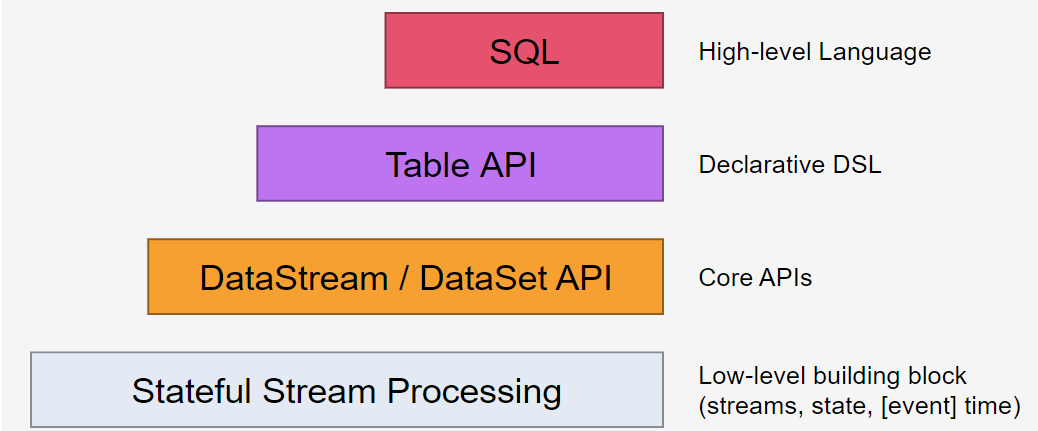
二、Flink聚合:
1、Window Aggregate
内置了三种常用的窗口:
TUMBLE(time, INTERVAL '5' SECOND); //类似于flink 中间层 DataStream API 中 window中的滚动窗口
HOP(time, INTERVAL '10' SECOND, INTERVAL '5' SECOND); //类似于flink 中间层 DataStream API中 window的滑动窗口,每10秒中统计最近5秒的数据
SESSION(time, INTERVAL '5' SECOND)
time有两种格式的时间,一种是proctime也就是系统时间, 另一种是rowtime。

2、 Group Aggregate

继续加入数据时:
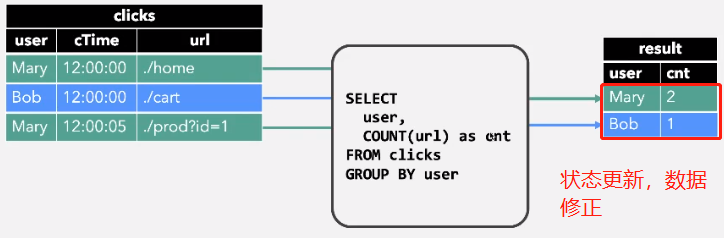
继续进入数据:
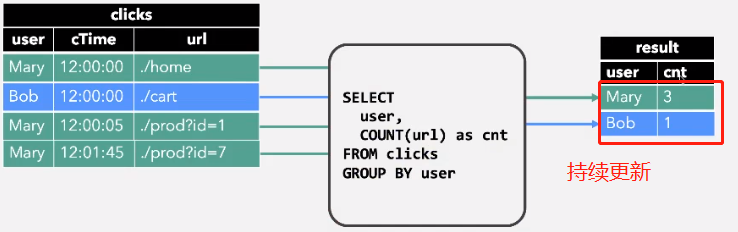
结果是一个不断更新的过程。
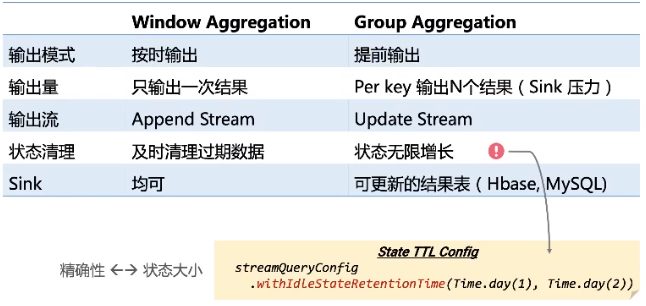
Window Aggregate 与 Group Aggregate 的区别
1)、Window Aggregate 与 Group Aggregate 是有一些明显的区别的。其主要的区别是,Window Aggregate 是当window结束时才输出,其输出的结果是最终值,不会再进行修改,其输出流是一个 Append 流。
而 Group Aggregate 是每处理一条数据,就输出最新的结果,其结果是在不断更新的,就好像数据库中的数据一样,其输出流是一个 Update 流。
2)、另外一个区别是,window Aggregate 由于有 watermark ,可以精确知道哪些窗口已经过期了,所以可以及时清理过期状态,保证状态维持在稳定的大小。
而 Group Aggregate 因为不知道哪些数据是过期的,所以状态会无限增长,这对于生产作业来说不是很稳定,所以建议对 Group Aggregate 的作业配上 State TTL 的配置。
对比图:
项目代码设置:
tEnv.getConfig().setIdleStateRetentionTime(org.apache.flink.api.common.time.Time.minutes(),org.apache.flink.api.common.time.Time.minutes());
Flink SQL项目实录的更多相关文章
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 大数据中必须要掌握的 Flink SQL 详细剖析
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言. 自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 ...
- Flink SQL任务自动生成与提交
目录 起因 思路 实现 1.配置 2.界面如下 3.环境 问题 起因 事情的起因,是看到一篇公众号文章Apache Flink 在汽车之家的应用与实践,里面提到了"基于 SQL 的开发流程& ...
- 如何参与flink开源项目
参与flink开源项目 https://flink.apache.org/how-to-contribute.html 1.回答社区问题 2.撰写bug报告 3.对于改进建议或新的特征 4.帮助别人并 ...
- KSQL和Flink SQL的比较
Confluent公司于2017年11月宣布KSQL进化到1.0版本,标志着KSQL已经可以被正式用于生产环境.自那时起,整个Kafka发展的重心都偏向于KSQL——这一点可以从Confluent官方 ...
- Flink SQL与 SQL Parser ,calcite
http://vinoyang.com/2017/06/12/flink-table-sql-source/ Flink Table&Sql 如何结合Apache Calcite http:/ ...
- Apache Flink SQL
本篇核心目标是让大家概要了解一个完整的 Apache Flink SQL Job 的组成部分,以及 Apache Flink SQL 所提供的核心算子的语义,最后会应用 TumbleWindow 编写 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- Flink SQL 如何实现数据流的 Join?
无论在 OLAP 还是 OLTP 领域,Join 都是业务常会涉及到且优化规则比较复杂的 SQL 语句.对于离线计算而言,经过数据库领域多年的积累,Join 语义以及实现已经十分成熟,然而对于近年来刚 ...
随机推荐
- 三十一.MySQL存储引擎 、 数据导入导出 管理表记录 匹配条件
1.MySQL存储引擎的配置 查看服务支持的存储引擎 查看默认存储类型 更改表的存储引擎 设置数据库服务默认使用的存储引擎 1.1 查看存储引擎信息 mysql> SHOW ENGINES\G ...
- divisors 数学
divisors 数学 给定\(m\)个不同的正整数\(a_1, a_2,\cdots, a_m\),请对\(0\)到\(m\)每一个\(k\)计算,在区间\([1, n]\)里有多少正整数是\(a\ ...
- 【LGR-059】洛谷7月月赛题解
传送门 比赛的时候正在大巴上,笔记本没网又没电(不过就算有我估计也不会打就是了) \(A\) 咕咕 const int N=(1<<10)+5; int a[N][N],n; void s ...
- 第四组团队git现场编程实战
组员职责分工 组员 分工 林涛(组长) 分配任务.整理数据.写博客 童圣滔 UI界面制作 林红莲 UI界面制作 潘雨佳 测评出福州最受欢迎的商圈 于瀚翔 测评出福州最受欢迎的商圈 覃鸿浩 测评出福州人 ...
- 生成一张带有logo的二维码图片
string url = 二维码内容; , , Encoding.UTF8); // 合成活动的LOGO图片 var hasImage = GlobalTools.GetCommonContent(& ...
- NNDL练习——Numpy的简单使用
总结自nndl_exercise Numpy导入 import numpy as np 数组/矩阵的创建 a=np.array([1,2,3]) b=np.array([[1,2],[3,4]]) c ...
- zabbix(9)iterms(监控项)
一.iterms key 监控项按参数来分有两种:带参数和不带参 按定义来分:zabbix自带和用户自定义 1)Key可以带参数,该参数为一个数组列表,可以同时传递多个参数,Key的格式如下: 既Ke ...
- centos7使用yum提示有事物未完成的解决办法:
错误提示: There are unfinished transactions remaining. You might consider running yum-complete-transacti ...
- stdu1309(不老的传说)
题目链接:http://acm.sdut.edu.cn/onlinejudge2/index.php/Home/Index/problemdetail/pid/1309.html 不老的传说问题 Ti ...
- 代码检查p626
1 编译运行p626 图10-3代码,提交编译运行的截图 2 STDOUT_FILENO的值是多少?提交在Ubuntu中查找这个值的命令截图