Flink SQL项目实录
一、Flink SQL层级
为Flink最高层的API,易于使用,所以应用更加广泛,eg. ETL、统计分析、实时报表、实时风控等。
Flink SQL所处的层级:
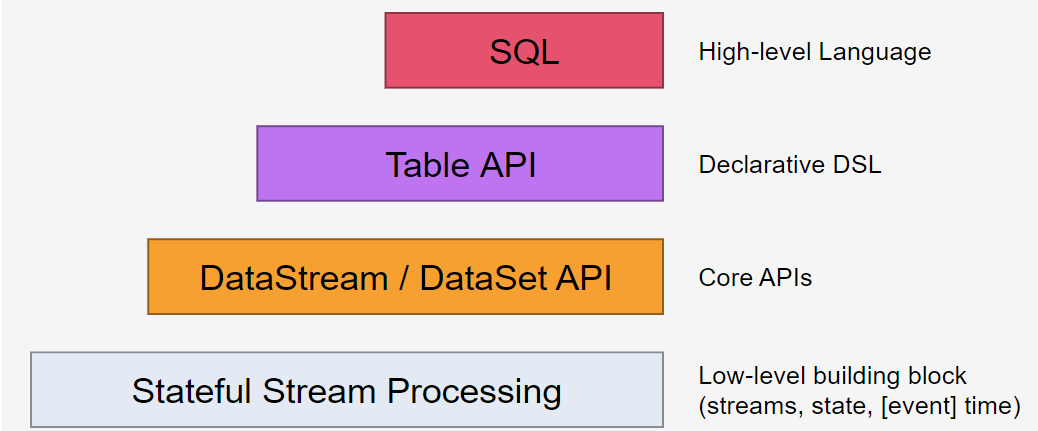
二、Flink聚合:
1、Window Aggregate
内置了三种常用的窗口:
TUMBLE(time, INTERVAL '5' SECOND); //类似于flink 中间层 DataStream API 中 window中的滚动窗口
HOP(time, INTERVAL '10' SECOND, INTERVAL '5' SECOND); //类似于flink 中间层 DataStream API中 window的滑动窗口,每10秒中统计最近5秒的数据
SESSION(time, INTERVAL '5' SECOND)
time有两种格式的时间,一种是proctime也就是系统时间, 另一种是rowtime。

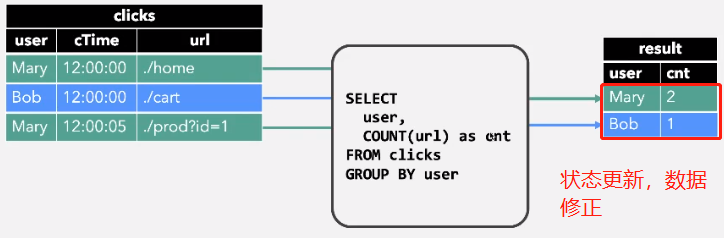
2、 Group Aggregate

继续加入数据时:
继续进入数据:
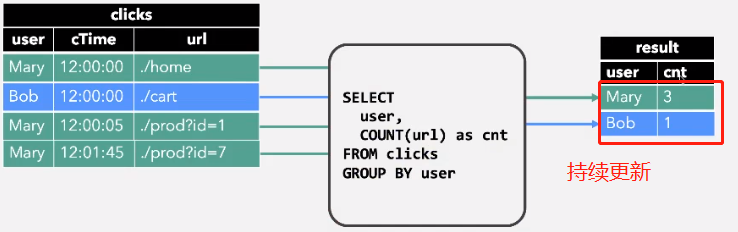
结果是一个不断更新的过程。
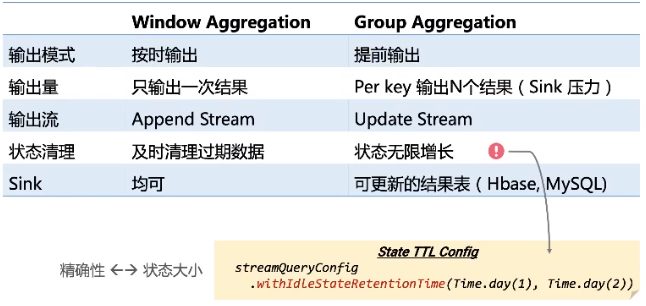
Window Aggregate 与 Group Aggregate 的区别
1)、Window Aggregate 与 Group Aggregate 是有一些明显的区别的。其主要的区别是,Window Aggregate 是当window结束时才输出,其输出的结果是最终值,不会再进行修改,其输出流是一个 Append 流。
而 Group Aggregate 是每处理一条数据,就输出最新的结果,其结果是在不断更新的,就好像数据库中的数据一样,其输出流是一个 Update 流。
2)、另外一个区别是,window Aggregate 由于有 watermark ,可以精确知道哪些窗口已经过期了,所以可以及时清理过期状态,保证状态维持在稳定的大小。
而 Group Aggregate 因为不知道哪些数据是过期的,所以状态会无限增长,这对于生产作业来说不是很稳定,所以建议对 Group Aggregate 的作业配上 State TTL 的配置。
对比图:
项目代码设置:
tEnv.getConfig().setIdleStateRetentionTime(org.apache.flink.api.common.time.Time.minutes(),org.apache.flink.api.common.time.Time.minutes());
Flink SQL项目实录的更多相关文章
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- 大数据中必须要掌握的 Flink SQL 详细剖析
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言. 自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 ...
- Flink SQL任务自动生成与提交
目录 起因 思路 实现 1.配置 2.界面如下 3.环境 问题 起因 事情的起因,是看到一篇公众号文章Apache Flink 在汽车之家的应用与实践,里面提到了"基于 SQL 的开发流程& ...
- 如何参与flink开源项目
参与flink开源项目 https://flink.apache.org/how-to-contribute.html 1.回答社区问题 2.撰写bug报告 3.对于改进建议或新的特征 4.帮助别人并 ...
- KSQL和Flink SQL的比较
Confluent公司于2017年11月宣布KSQL进化到1.0版本,标志着KSQL已经可以被正式用于生产环境.自那时起,整个Kafka发展的重心都偏向于KSQL——这一点可以从Confluent官方 ...
- Flink SQL与 SQL Parser ,calcite
http://vinoyang.com/2017/06/12/flink-table-sql-source/ Flink Table&Sql 如何结合Apache Calcite http:/ ...
- Apache Flink SQL
本篇核心目标是让大家概要了解一个完整的 Apache Flink SQL Job 的组成部分,以及 Apache Flink SQL 所提供的核心算子的语义,最后会应用 TumbleWindow 编写 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- Flink SQL 如何实现数据流的 Join?
无论在 OLAP 还是 OLTP 领域,Join 都是业务常会涉及到且优化规则比较复杂的 SQL 语句.对于离线计算而言,经过数据库领域多年的积累,Join 语义以及实现已经十分成熟,然而对于近年来刚 ...
随机推荐
- 学生管理系统——数据库、java基础
1.项目分层 view层:视图层 controller层:控制层 service层:业务层 dao层:数据库访问层 domain:实体包 tools:工具类 2.jar包 3.配置文件 4.程序设计 ...
- linux系列(十四):head命令
1.命令格式: head [参数] [文件] 2.命令功能: head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行. 3.命令参数: -q 隐藏文件名 -v 显示文件名 ...
- GIAC 技术大会 Redis 演讲文字稿
附录:https://mp.weixin.qq.com/s/mvAkPXBayAzT_RWFdsOt5A 观众朋友们,我是来自掌阅的工程师钱文品,今天我带来的是分享主题是:Redis 在海量数据和高并 ...
- beyond compare秘钥被禁
错误提示:This license key has been revoked xxxxx 即: Windows 系统: 解决方法: 删除以下目录中的所有文件即可. C:\Users\Administr ...
- 黑马vue---33、vue-resource 实现 get, post, jsonp请求
黑马vue---33.vue-resource 实现 get, post, jsonp请求 一.总结 一句话总结: vue-resource使用非常非常非常简单:this.$http.get('htt ...
- C#Winform ListView中没有Item双击事件的两种实现方法!
第一种: //if (this.listView1.FocusedItem != null) //{ // if (this.listView1.SelectedItems != null) // { ...
- sql 从服务器取消主从复制
mysql>change master to master_host='' mysql>stop slave;reset slave;
- angular组件数据和事件
<h1>引入图片</h1> <img src="assets/images/02.png" alt="收藏" /> < ...
- 双缓冲技术局部更新原理之派生自SurfaceView
package com.loaderman.customviewdemo; import android.content.Context; import android.graphics.Canvas ...
- @Deprecated注解
它的作用是对不应该再使用的方法添加注解,当编程人员使用这些方法时,将会在编译时显示提示信息,它与javadoc里的@deprecated标记有相同的功能,准确的说,它还不如javadoc @depre ...